前言:近期,以Stable Diffusion、Dall-E、Midjourney等软件或算法为代表的AI绘图技术引起了广泛关注。尤其是自2022年8月Stable Diffusion模型开源以来,更是加速了这一领域的发展。
对于初学者来说,面对这些令人惊叹的AI绘图作品,他们既想了解绘图软件的使用和技巧,又面对着诸如Lora、ControlNet、Dall-E 等复杂术语,不知道从何入手。通过收集资料,本文将从以下四个方面介绍目前最流行的 AI 绘图工具和模型训练方法,力求用通俗易懂的语言帮助大家理清术语背后的真实含义。
一、文生图算法简介
text to image 技术,又称为文生图,是一种基于自然语言描述生成图像的技术。其历史可以追溯到20世纪80年代。
随着深度学习技术的发展,特别是卷积神经网络 CNN 和循环神经网络 RNN 的出现,text to image技术开始采用神经网络模型进行训练和生成。
GAN(generative adversarial networks)和VAE(variational auto encoder)算法是最早被应用于 text to image任务的算法。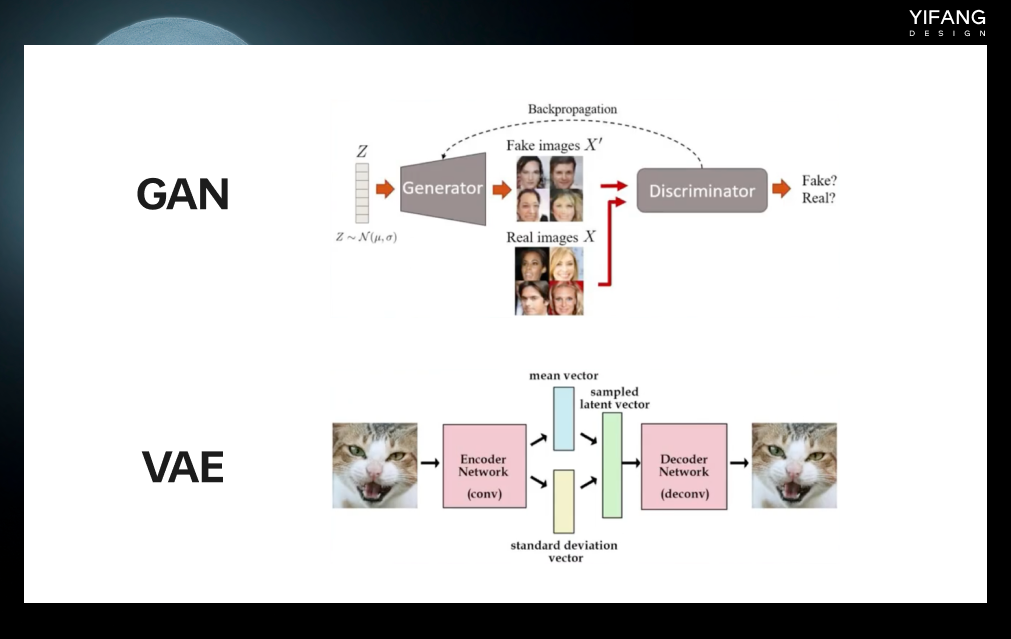
随着计算机硬件和算法的不断进步,越来越多的新算法涌现出来,例如Stable Diffusion 和Dall-E等。相较于传统算法如GAN和VAE,这些新算法在生成高分辨率、高质量的图片方面表现更加卓越。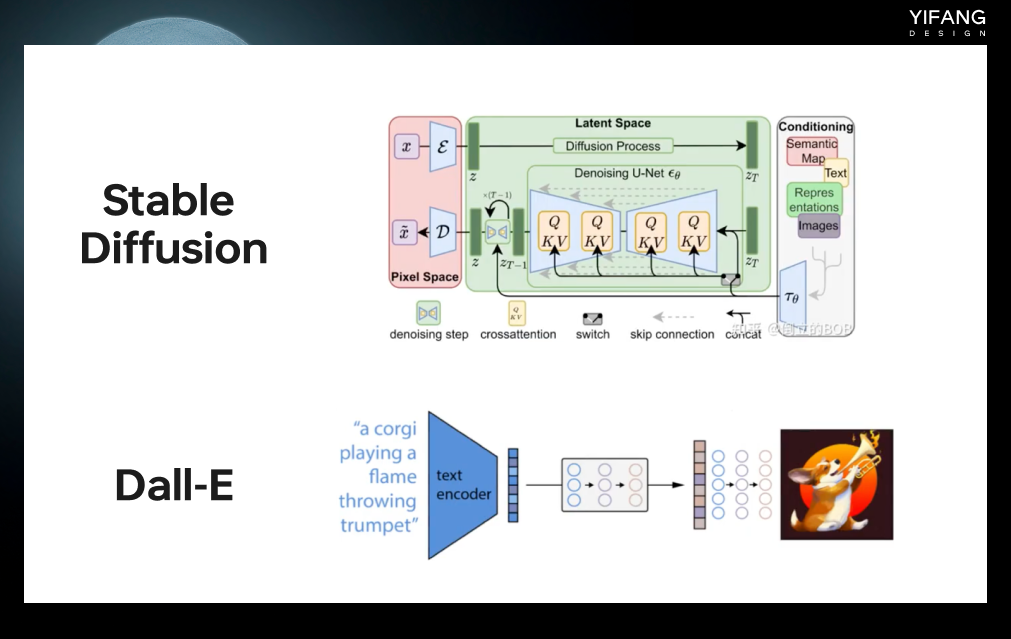
Stable Diffusion(稳定扩散)是基于DPM(Diffusion Probabistic models)的改进版本,DPM是一种概率建模方法,旨在使用初始状态的噪声扰动来生成图像。模型会首先生成一张初始状态的噪声图像,然后通过逐步的运算过程逐渐消除噪声,将图像转换为目标图像。这也是我们在进行Stable Diffusion 绘图时,首先需要确定噪声采样方式和采样步长的原因。
Stable Diffusion是由Stability AI COMP、VIZ LMU和Runway合作发布的一种人工智能技术,其源代码在2022年8月公开于GitHub,任何人都可以拷贝和使用。该模型是使用包含15亿个图像文本数据的公开数据集Line 5B进行训练的。训练时使用了256个Nvidia A100 GPU,在亚马逊网络服务上花费了150,000个GPU小时,总成本为60万美元。
Dall-E是OpenAI公司于2021年1月发布的一种基于Transformer和GAN的文本到图像生成算法,使用了大规模的预训练技术和自监督学习方法。Dall-E的训练集包括了超过250万张图像和文本描述的组合。该算法的灵感来源于2020年7月OpenAI发布的GPT-3模型,后者是一种可以生成具有语言能力的人工智能技术。Dall-E则是将GPT-3的思想应用于图像生成,从而实现了文本到图像的转换。
2022年2月,OpenAI发布了Dall-E2。相比于上一版本,Dall-E2生成的图像质量更高,而且可以生成更加复杂和多样化的图像。Dall-E2的训练集包括了超过1亿张图像和文本描述的组合,比Dall-E的训练集大40倍。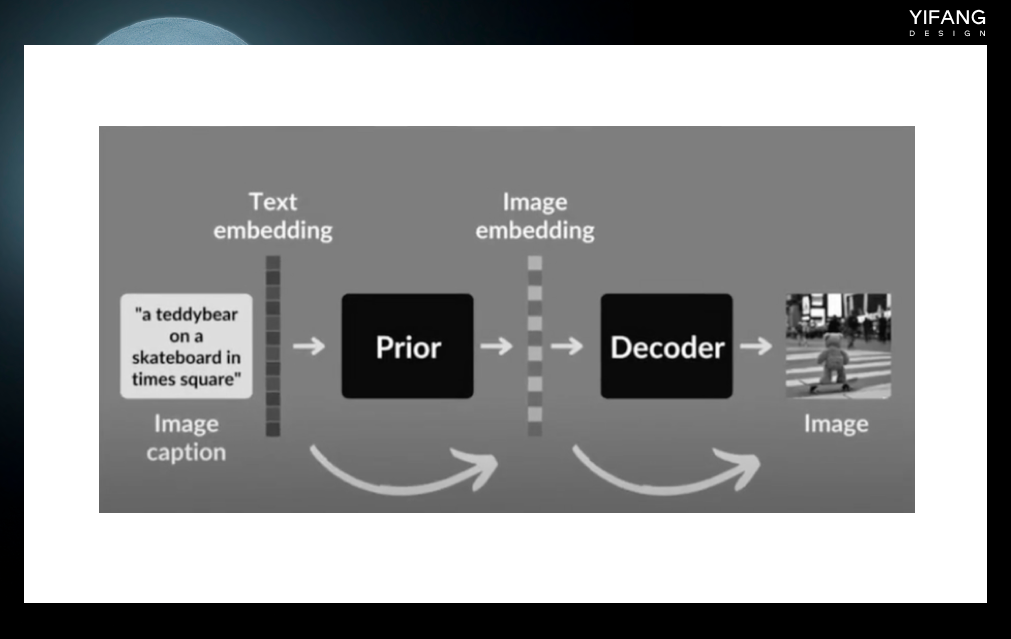
当前Dall-E算法虽未开源,但已经有人尝试创建Dall-E的开源实现。比如,Crayon前身为Doy Mini,于2022年在Hugging Face的平台上发布。
大部分的绘图工具都是基于Stable Diffusion、Dall-E相关的或类似或衍生的算法开发的,尤其是已经开源的稳定扩散算法。
以下是与此相关的几个常见、广泛使用的AI绘图工具:Midjourney、Stable Diffusion、Dall-E、NovelAI、Disco Diffusion。
二、AI绘图工具介绍
1、Midjourney
Midjourney是一个由Leap Motion的联合创始人David Holz创立的独立研究室,他们以相同的名称制作了一个人工智能程序,也就是我们常听到的Midjourney绘图软件。该软件于2022年7月12日进入公开测试阶段,基于Stable Diffusion算法开发,但尚未开源,只能通过Discord的机器人指令进行操作。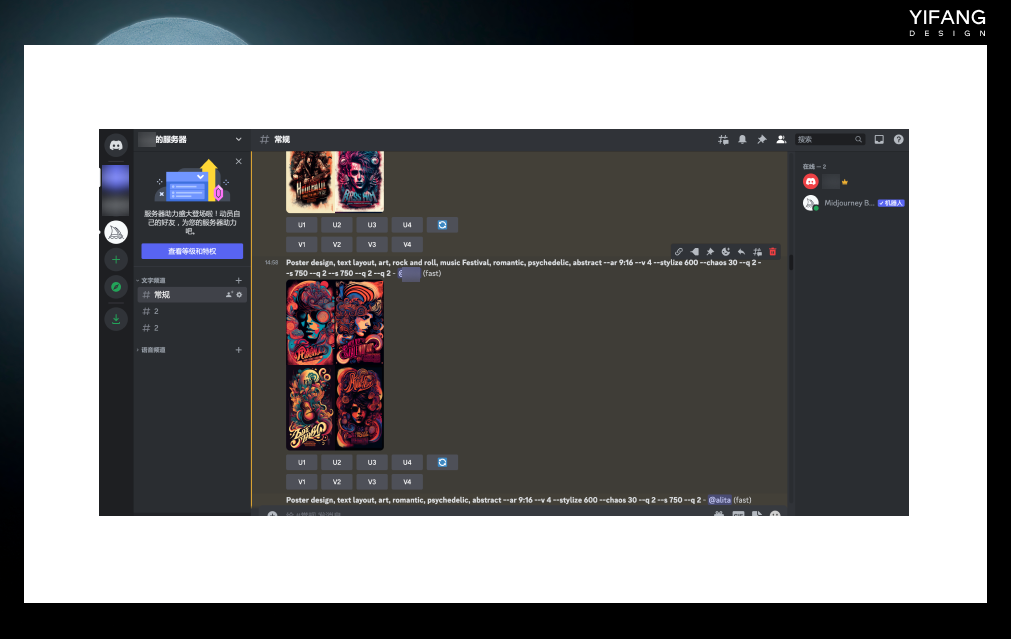 https://www.midjourney.com/app/
https://www.midjourney.com/app/
Discord是一个在线聊天和语音交流平台,类似于我们常用的QQ聊天工具。Midjourney官方提供了一个discord机器人,用户可以在discord中添加该机器人,进入指定的服务器进行绘图操作。具体方法是,登录discord,在添加了Midjourney Bot的服务器中,在聊天框里输入“image”,然后输入绘图指令即可。
Midjourney是一个学习成本极低、操作简单的绘图工具,生成的图片非常有艺术感,因此以艺术风格闻名。只需输入任意关键词即可获得相对满意的绘图结果。绘图者只需要专注于设计好玩实用的绘图指令(Prompt),而无需花费太多精力在软件操作本身上。但是,Midjourney的使用需要全程科学上网,并且使用成本相对较高。由于软件未开源,生成的图片可能无法满足用户的特定需求,只能通过寻找合适的关键词配合图像编辑软件来实现。
2、Stable Diffusion
Stable Diffusion是一种算法和模型,由Stability.ai、CompVis-LMU和Runway共同发布,于2022年8月开源。因此,用户可以下载Stable Diffusion的源代码,并通过各种方式在自己的电脑上进行本地部署。
将Stable Diffusion分解后,有以下几个结构和模型。在训练时,输入的训练图像首先通过编码器模块进行编码,以进行降维,例如从512512降到64__64,这将大大加快训练速度。输入的文本长度是不固定的,通过文本编码器(通常是clip模型)将其转换为固定长度的向量以进行计算。这两者结合后,输入到UNET网络进行训练。训练后,图像通过解码器解码后恢复为512512的图像。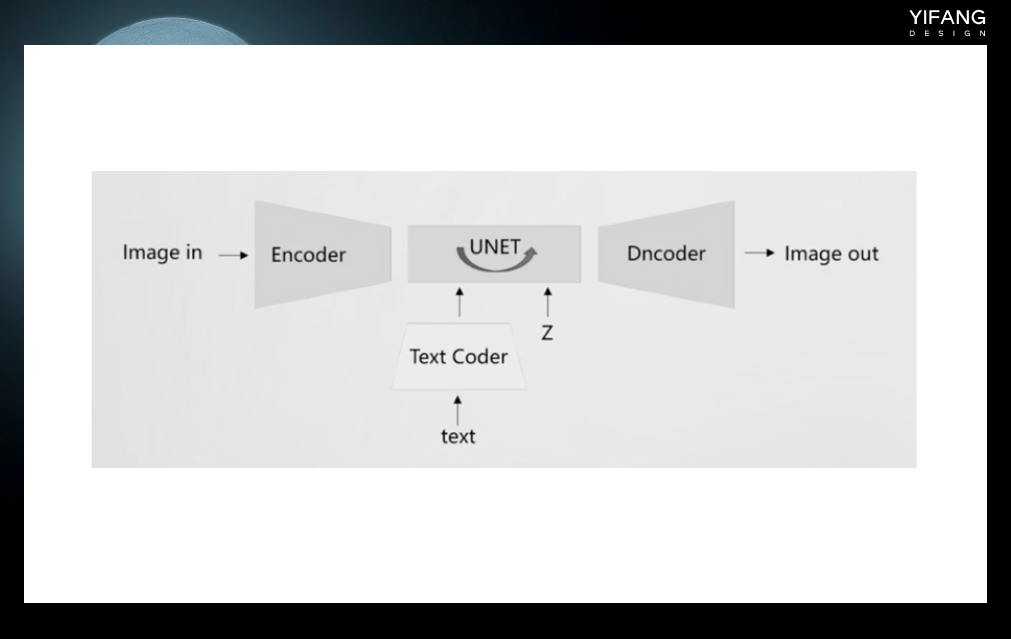
生成图像时候只需要带入一个初始化了的噪声图像和文本,二者组合后输入UNET网络进行去噪,最后通过Dncoder 还原成清晰的图像。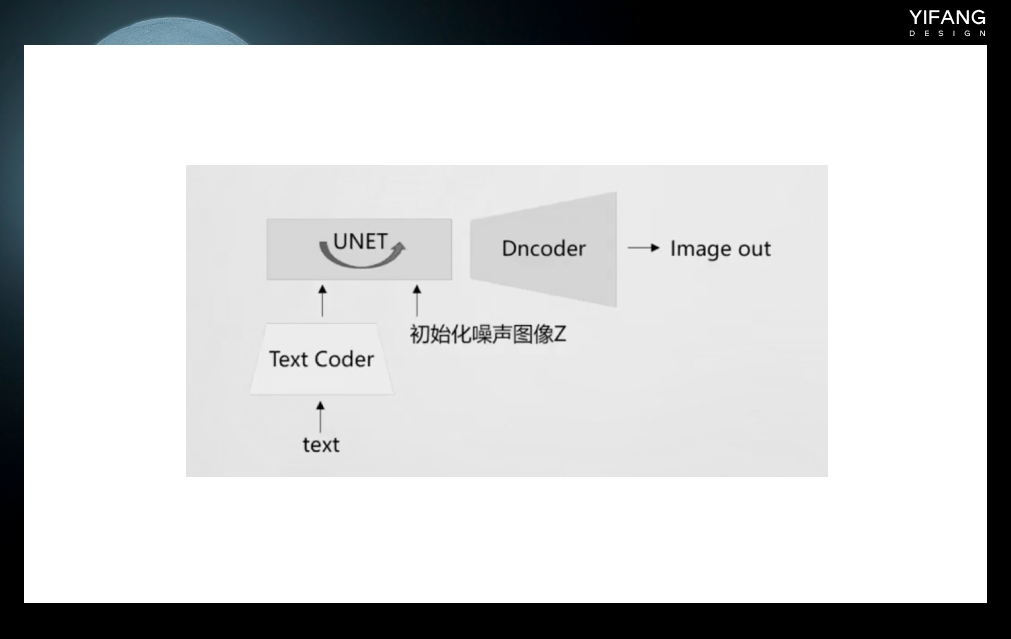
大家可能会认为安装和部署Stable Diffusion很困难,因为需要安装Python运行环境和一些依赖库,以及对Python语言有一定的编程经验。但是,有一些一键式的安装包可以帮助你快速搭建stable diffusion的环境。这些安装包包含了 Python运行环境和相关的依赖库和代码。只需要下载安装包,然后根据指示进行几个简单的步骤,即可完成Stable Diffusion的安装和部署。
最受欢迎的工具包是GitHub上automatic 1111用户创建的Stable Diffusion Web UI。它是基于radio库的浏览器界面交互程序。具体的安装视频可以在各大知识平台都可以搜到,这里就不展开了。
一键式安装包(包含Python运行环境,还集成了Stable Diffusion的相关依赖库和代码)https://github.com/AUTOMATIC1111/stable-diffusion-webui
目前最新的 stable diffusion 的版本是 2.1,但 2.0 以上版本砍掉了NSFW 内容和艺术家关键词,相当于封印了很多能力。
Stable Diffusion Web UI只是运行Stable Diffusion的可视化界面,就如一辆车子缺乏发动机,我们还需要从Stability AI的Hugging Face官网下载Stable Diffusion模型,才能开始运行Stable Diffusion绘图。
本地运行Stable Diffusion需要较高的显卡配置,*建议使用显存大于8G的N卡显卡。如果配置不够但还想体验一下,Stable Diffusion有线上版本DreamStudio,只是需要付费使用。新用户可以获得200个点数,每次标准生成将消耗一个点数。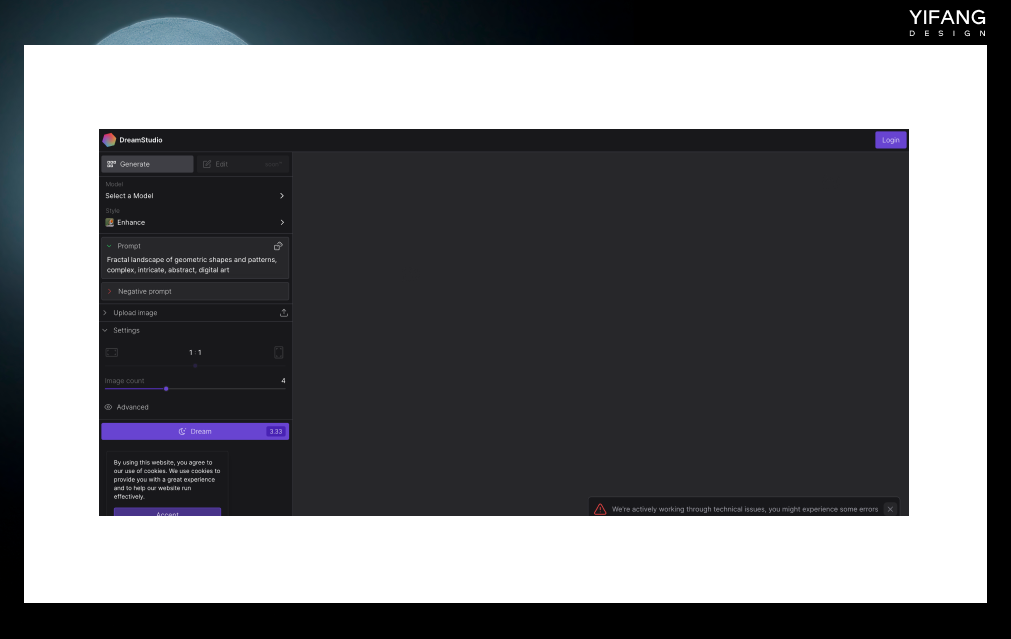 https://beta.dreamstudio.ai/generate?from=%2Fdream
https://beta.dreamstudio.ai/generate?from=%2Fdream
3、Dall-E
Dall-E是OpenAI旗下的一款AI绘图工具软件,与ChatGPT同属于一个公司。最新版本Dall-E 2于2022年2月发布。Dall-E可以在线使用,Dall-E会根据这些文字描述生成一张或多张图片,并显示在屏幕上。用户可以上传自己的图片,标记图像中的区域进行进一步的编辑和修改。Dall-E还会根据已有图像的视觉元素对图像进行二次加工,延展图片边界。 https://labs.openai.com/
https://labs.openai.com/
用户在注册的第一个月可以获得50个免费积分,每月可以获得15个积分,每张图片花费1个积分。如果需要更多的图像,用户需要付费。当前,Dall-E算法并未公开源代码。
4、NovelAI
Nova AI是由美国特拉华州的Anlatan公司开发的云端软件。最初,该软件于2021年6月15日推出测试版,其主要功能是辅助故事写作。之后,在2022年10月3日,Nova AI推出了图像生成服务,由于其生成的二次元图片效果出众,因此它被广泛认为是一个二次元图像生成网站。 https://novelai.net/
https://novelai.net/
Nova AI的图像生成模型是使用8个Nvidia A100 GPU在基于Damburu的约530万张图片的数据集上训练而得到的,其底层算法也是基于stable diffusion模型微调而来的。
使用Nova AI的方法很简单,只需登录官方网站,进入图像生成界面,输入关键字,即可生成图像。此外,由于Novel AI曾经发生过代码泄露,因此也可以下载Novoai 的模型(Naifu、Naifu-diffusion)在Stable Diffusion web UI中使用。
**
5、Disco Diffusion
Disco Diffusion是最早流行起来的 AI 绘图工具,发布于Google Clab平台。它的源代码完全公开且免费使用,可通过浏览器运行而无需对电脑进行配置。Disco Diffusion基于Diffusion扩散模型开发,是在Stable Diffusion发布之前最受欢迎的扩散模型之一。然而,它在绘制人物方面表现不佳,且生成一张图片需要十几二十分钟的时间,因此在Stable Diffusion发布后逐渐失去了市场热度。
6、其他工具
NiJiJourney是一个专门针对二次元绘画的AI绘画软件,由Spellbrush和Midjourney共同推出。使用方法与Midjourney基本相同,用户可以在Discord上输入相应的绘画指令进行绘画。目前NiJiJourney处于内测阶段,绘画是免费的,但是版权问题尚未明确表态。预计在正式公测时,付费用户可以获得商用权利,与Midjourney类似。
Waifu Diffusion是一种基于扩散模型的AI绘图模型,它的早期版本1.4在动漫领域的绘图效果与NovelAI非常相似。有些人甚至认为Waifu Diffusion是在NovelAI模型的基础上进行微调得到的,但Waifu Diffusion团队表示他们的模型是Trinart Derrida和Eimis Anime Diffusion模型的合并结果。我们可以从Hugging Face上下载Waifu Diffusion模型,并在Stable Diffusion Web UI中使用它。
除此以外还有很多类似Midjourney的绘图工具,几乎都是基于Stable Diffsion或者类似算法进行开发。如Leonardo AI、BlueWillow AI、Playground AI、Dreamlike、NightCafe.studio等等。有一些还具备图像修改、图像延展等功能,尽管这些软件还处于测试阶段,需要申请才能使用,但它们生成的图片质量不输Midjourney,因此常被拿来与Midjourney进行对比。
1.Leonardo AI
2.BlueWillow AI
3.Playground AI
4.Dreamlike
5.NightCafe.studio
三、模型训练相关名词
AI大模型,也被称为基础模型(Foundation Model),是指将大量数据导入具有数亿甚至万亿级参数的模型中,通过人工智能算法进行训练。Stable Diffusion、NovelAI、 Dall-E等模型都属于大模型。这类大模型普遍的特点是参数多,训练时间长,具备泛化性、通用性、实用性,适用于各种场景的绘图。
这类 AI 大模型也存在一个普遍的缺点,就是无法满足对细节控制或特定人物特定绘图风格的绘图需要。即便掌握了算法知识,训练一个好的 AI 绘图模型也需要强大的计算资源,这些计算资源对于普通人来说过于昂贵。例如Stable Diffusion在亚马逊网络服务上使用 256 个NVIDIA A100 GPU进行训练,总共花费了 15 万个GPU小时,成本为 60 万美元。
于是,针对这些大模型的微调技术应运而生。为了达到绘制特定人物或特定绘图风格的需要,我们不需要重新训练大模型,只要提供几张图片和一张显卡,几个小时的时间就可以实现。也就是我们常听说的Embedding、Hypernetwork、Dreambooth、Lora、ControINet,它们都属于大模型的微调技术,可以在Stable Diffusion Web UI 中进行训练后使用,感兴趣的话可以在Civitai进行下载。
1、Embedding
Text Coder 就像一本词典,输入文本后Text Coder能快速查找到符合要求的词向量,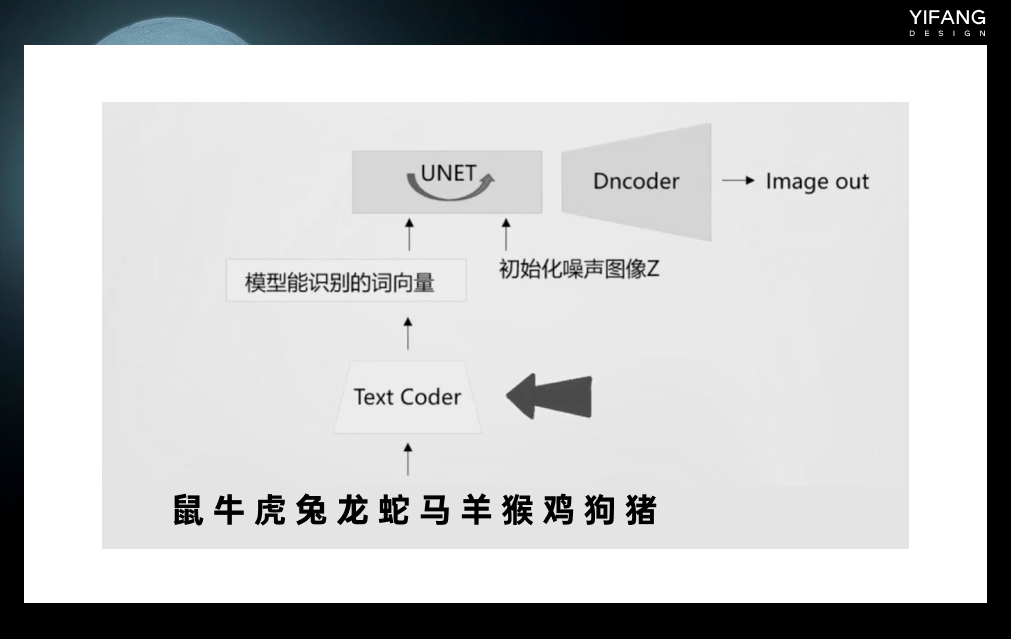
那如果出现新的关键词,text coder上找不到该怎么办?这就是Embedding算法要做的事情,它通过训练在Text Coder中找到与新的词特征、风格相同的词向量。例如这个麒麟训练后可以看作龙羊虎的组合。
Embedding算法不改变大模型的基本结构,也不改变text coder,所以就能达到微调模型的目的。对于风格的描述,一般需要较多的关键词。Embedding对于复杂的词汇的调整结果并不太好,定义人物需要的关键词少,所以适用于对人物的训练。
2、Hypernetwork
与Embedding不同,Hypernetwork是作用在UNET网络上的,UNET神经网络相当于一个函数,内部有非常多的参数, Hypernetwork 通过新建一个神经网络,称之为超网络。超网络的输出的结果是UNET网络的参数。超网络不像UNET,它的参数少,所以训练速度比较快,因此Hypernetwork能达到以较小时间空间成本微调模型的目的。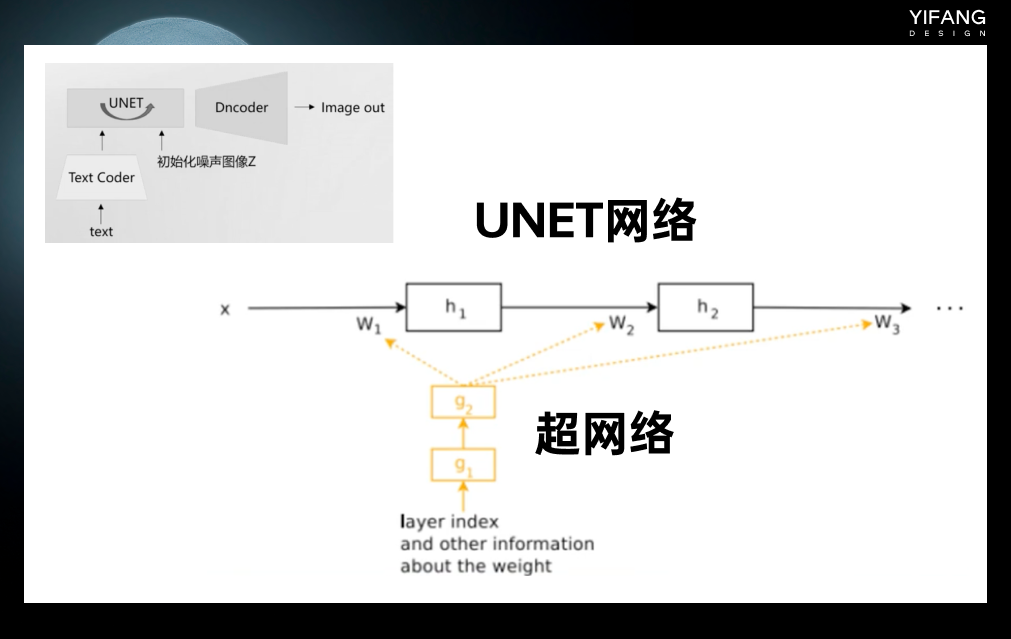
Hypernetwork 会影响整个UNET的参数生成,理论上更适合风格的训练。Stable Diffusion Web UI上也继承了 Embedding和Hypernetwork的训练环境。
**
3、Dreambooth
Dreambooth是Google在 2022 年8月提出的一种新的网络模型,它的强大之处在于能完整地保留你想要关键视觉特征。例如图中最左边的黄色闹钟上面一个醒目的黄色的。采用Dreambooth生成的新图像可以准确还原这个图像最右边这个样子。这需要模型能够准确识别物体的细节。你只需提供 3- 5 张的图像和文本提示作为输入,就可以达到很好的效果。Dreambooth适合人物训练,改版的Dreambooth方法native train适合于风格的训练。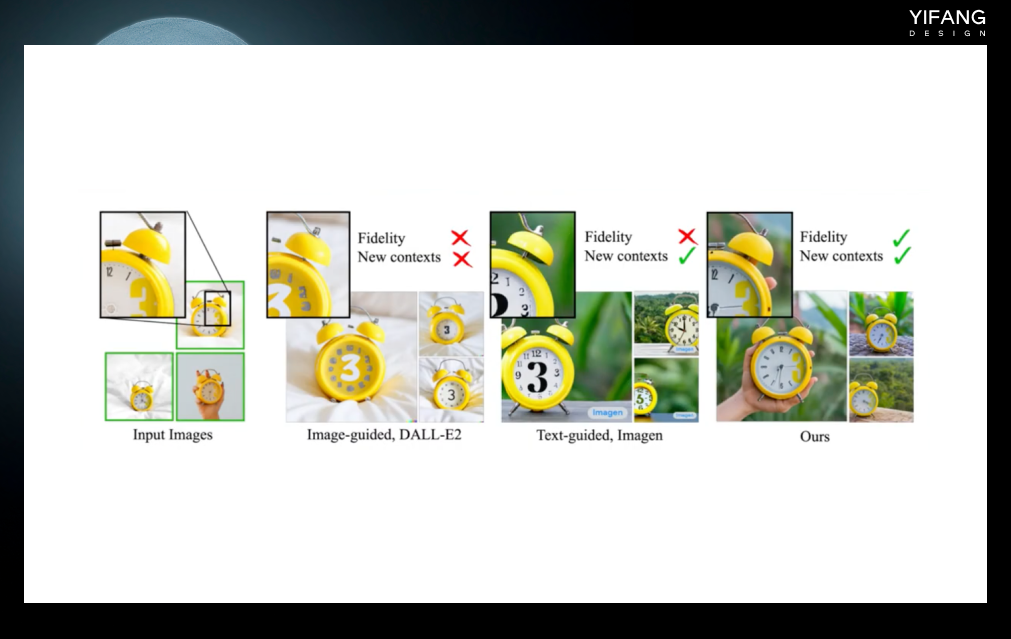
Dreambooth要求同时提供特征词加类别和类别文本图片信息带入模型进行训练,例如 a dog 和 a [V] dog。这样做的好处是既可以保留类别的原始信息,又可以学习到特征词加类别的新的信息。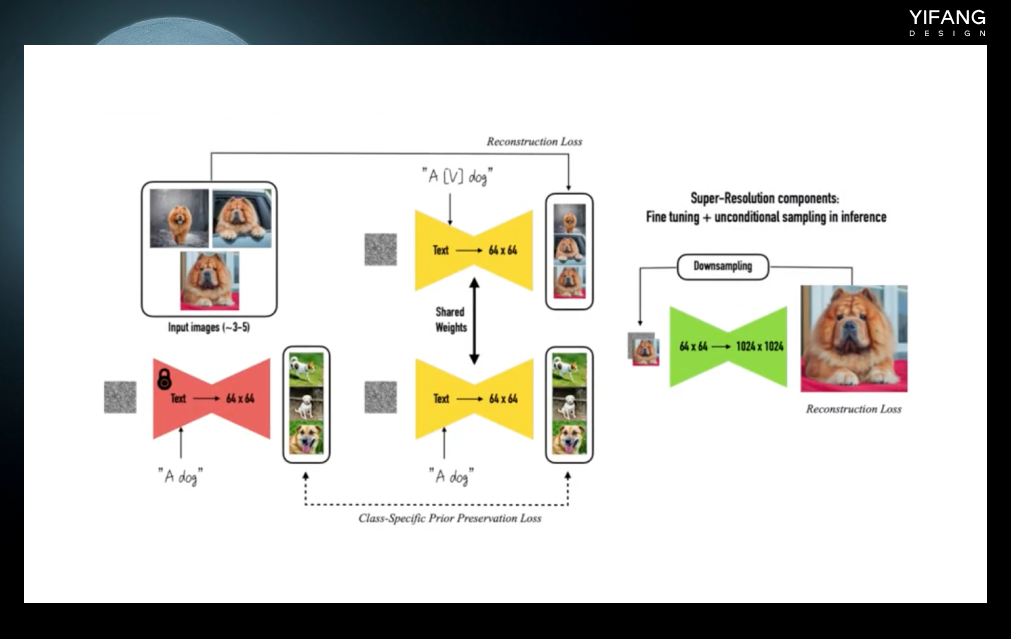
**
4、LoRA
LoRA(Low-Rank Adaptation of large Language Models)是由微软研究员开发的一种用于微调大模型的技术。该技术建议冻结预训练模型的权重,并在每个 Transformer 块中注入可训练层,从而在保持大部分参数不变的情况下,调整局部的一些模型参数。由于不需要重新计算模型的权重参数的梯度,这大大减少了需要训练的计算量,并降低了 GPU 的内存要求。
使用 LoRA 模型进行微调可以为我们提供更自由、更便捷的微调模型的方式。例如,它使我们能够在基本模型的基础上进一步指定整体风格、指定人脸等等。此外,LoRA 模型本身非常小,即插即用,非常方便易用。
5、Controlnet
Controlnet是当前备受瞩目的AI绘图算法之一。它是一种神经网络结构,通过添加额外的条件来控制基础扩散模型,从而实现对图像构图或人物姿势的精细控制。结合文生图的操作,它还能实现线稿转全彩图的功能。
Controlnet的意义在于它不再需要通过大量的关键词来堆砌构图效果。即使使用大量关键词,生成的效果也难以令人满意。借助Controlnet可以在最开始就引导它往你需要的构图方向上走,从而实现更准确的图像生成。
四 、VAE模型的作用
正如我们之前介绍的,Stable Diffusion在训练时会有一个编码(Encoder)和解码(Dncoder)的过程,我们将编码和解码模型称为VAE模型。预训练的模型,如官网下载的Stable Diffusion模型,一般都是内置了训练好的VAE模型的,不用我们再额外挂载。但有些大模型并不内置VAE模型,或者VAE模型经过多次训练融合不能使用了,就需要额外下载,并在Stable Diffusion Web UI 中添加设置。如果不添加,出图的色彩饱和度可能会出问题,发灰或变得不清晰。大家可以根据模型说明信息来确定是否要下载VAE 。
公众号:AI Design Center
小红书:一方YiFang
知 乎:一方YiFang

若有收获,就点个赞吧
0 人点赞
