整合包获取(内容搬运@Token)
搜索B站UP主,独立研究员-星空
选择下载最新的整合包即可
如果你有旧的整合包,不要覆盖,只需要迁移旧整合包的模型文件到新的整合包,每个整合包都可以独立使用
环境部署
首先确认自己是N卡1050以上,并更新最新显卡驱动
解压整合包,注意路径不要有中文,安装启动器所需的运行环境也就是windowsdesktop-runtime(整合包内已有)
打开启动助手,选择自动运行,会弹出一个命令行窗口,然后启动器就可以关闭了
命令行窗口等待一段时间之后会开始运行,可能会等待很久没有任何反应,并不是程序没有响应,属于正常现象,请耐心等待
运行完毕之后会自动在默认浏览器弹出网页,也就是sd webui,如果没有弹出,请在浏览器内输入网址
然后就可以开始进行AI绘画了,注意命令行窗口不要关闭,可以放在一旁方便监视计算进度
界面元素
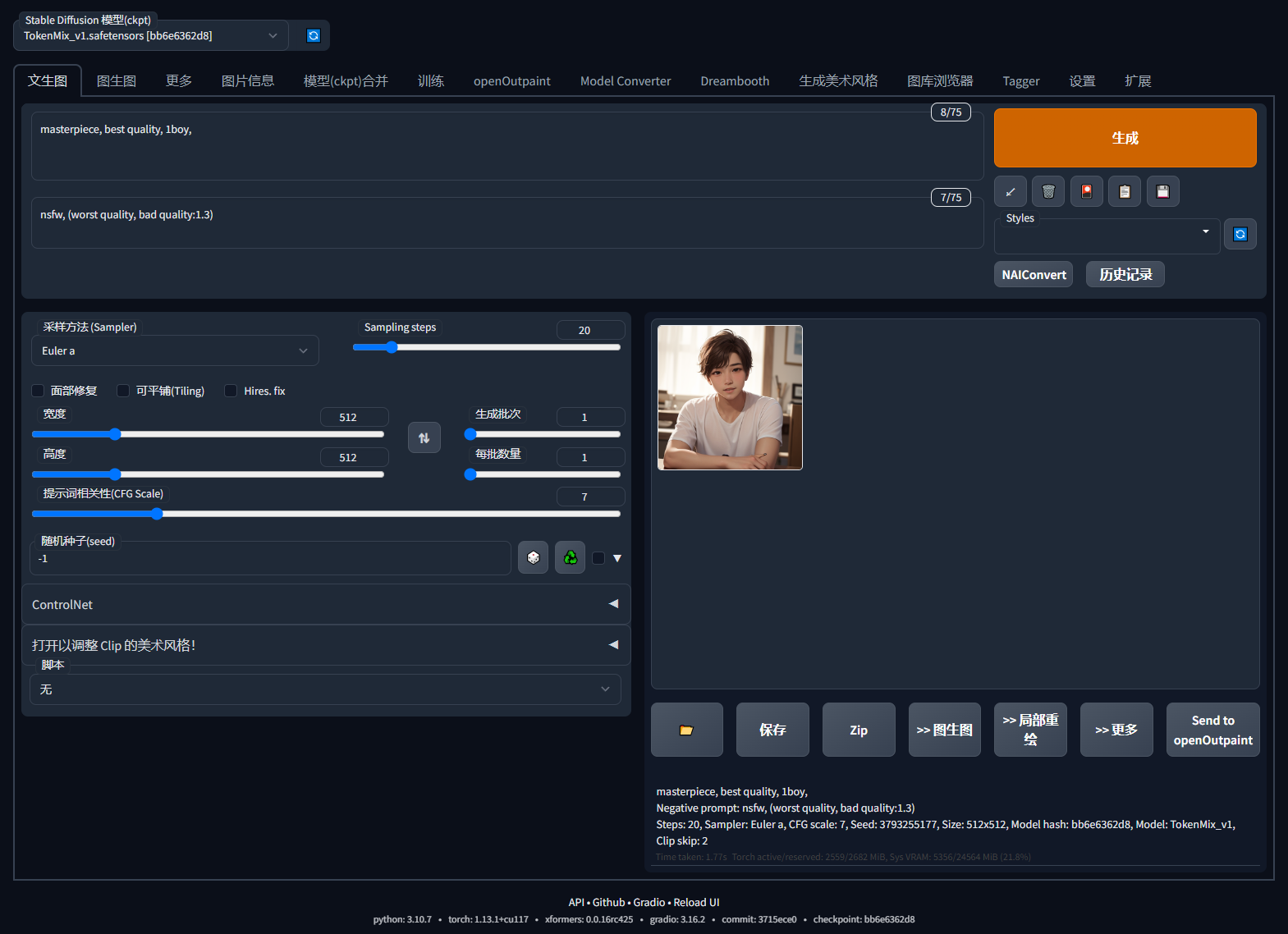
不同整合包和不同版本的界面排布可能会不同,这里不会介绍所有界面元素,只会介绍常用的界面元素
模型选择
所有模型都可以分为两种,NAI base和SD base
- NAI base,基于Novelai泄露的模型库训练融合而来,数据库主要来自于互联网最大的二次元同人数据库Danbooru,提示词基于Danbooru tag group
- SD base,基于StableDiffusion官方模型训练融合而来,数据库基于开源数据库LAION-5B,数据库范围涵盖了整个互联网,提示词系统基于自然语言
现阶段流行的模型大都同时融合了两者,以解决NAI的元素细节问题和SD的元素丰富度问题,而提示词系统则以前者为主,标志性Tag就是1girl
因为Danbooru的粉丝人工标注tag group远比LAION-5B的AI自动标注更为精确和体系化,所以NAI base一开始就有远比SD base高得多的词汇敏感性,而SD base在2.0之前因为这个原因非常难以使用,所以以下所有教程都是基于NAI base为主
模型格式和放置位置
CheckPoint,也就是是模型文件有两个格式,ckpt 和 safetensors,现在提倡使用后者,因为前者会有潜在的系统安全风险,但是一般不用太担心,下到哪个用哪个
模型文件有很多大小,一般分为2G,4G,7G,8G,如果低于1G比如说200M,800M,那说明这个文件不是模型而是lora或者vae。不同大小的同一模型在质量上的差别基本可以忽略不计,除非是用于模型训练否则下小的即可
模型放置路径:*\models\Stable-diffusion
模型下载
以下几个网站基本涵盖了网络上95%的模型来源,其他的只能去各大群组寻找了
Civitai:最流行的AI模型网站,每个模型都有预览图可以预览,还有评论区用来返图
- https://civitai.com/
- 抱脸:以原始大模型为主,因为不是每个模型都有预览图,使用起来不是很方便
- https://huggingface.co/models?other=stable-diffusion
- SD金矿:SD界的维基,大部分模型都是4chan流出,可以找到一些比较古早的模型
- https://rentry.org/sdmodels
- AI绘画模型博物馆:二次元模型最集中的地方
- https://aimodel.subrecovery.top/
- SD-WebUI 资源站:也是以二次元为主,更新没有上面的及时
-
模型推荐
模型的更新迭代非常快速,很多过去评价不错的模型现在都早已被淘汰,因为新的模型的在词汇敏感度,人体结构表现,服装和其他质感细节精度,以及对高分辨率的支持都要远远强于早期模型,所以这里的模型推荐也很可能随时过时
OrangeMixs:跨时代的二次元模型,最新版已经更新到了AbyssOrangeMix3 (AOM3),特点是保留了二次元风格比例的同时融合了照片级的质感表达
- https://huggingface.co/WarriorMama777/OrangeMixs
- anything-v3.0:一个在NAI的基础上做了一定优化的模型,已经全面替代了NAI,相对比较古早,但是在做模型融合和模型训练时会用到,如果觉得AOM过于油腻也可以拿来使用
- https://huggingface.co/Linaqruf/anything-v3.0
- ChilloutMix:网上的ai cos图所使用的模型,用来生成写实照片图
- https://civitai.com/models/6424/chilloutmix
- 米山舞dbmai:一个贴吧大佬“火柴人之父L”训练的模型,做二次元设计非常好使
- https://drive.google.com/drive/folders/1MUtM5MTXM35fid5TE3tUSKXAqPP7oysz
- ChikMix:我自己融的模型,韩式2.5D
https://civitai.com/models/9871
附加网络(Extra Networks)
点击生成按钮下的红色卡片,会打开附加网络的浏览界面
如果没有这个按钮请更换更新的整合包Textual Inversion
也叫做Embedding,Embedding不会向你的模型添加任何外来的信息和概念,可以把它理解为一个浓缩后的提示词,只不过这个提示词是通过图片来引导训练得出的
文件后缀一般为.pt,少部分为.bin
- 大小非常小,在几kb到几百kb不等
- 有一部分Embedding需要放在反面提示词来使用,作用是提高图片输出的质量和稳定性
-
Hypernetworks
也叫做超网,因为现在基本被lora完全替代所以已经很少能见到了,以画风调节为主
文件后缀一般为.pt
- 大小在数百mb左右
-
Checkpoints
和webui左上角的模型选择是一样的,只不过这里可以设置预览图
文件后缀一般为.ckpt和.safetensors
- 大小最大,2G到8G不等
- Dreambooth(DB)是一种模型训练方式,训练的输出结果就是Checkpoint
模型放置路径:*\models\Stable-diffusion
Lora
现在最流行的附加网络,可以理解为一种剔除了每个模型都通用的sd和nai官方数据之后,只留下剩余数据的DB,会让你的模型学会他原本不了解的信息和概念
文件后缀一般为.safetensors
- 大小在几十mb到两三百mb不等
- Lora大小和使用效果无关
- 部分Lora会需要触发词来使用,否则效果不明显
-
使用附加网络
点击卡片会自动在提示词框或反面提示词框添加相应的提示词,取决于你的输入光标位置
- Lora所需要的触发词需要手动添加,不需要紧挨着Lora的提示词,可以分开放置在任何位置
-
管理附加网络
附加网络可以嵌套文件夹存放,比如*\models\lora\角色\overwatch\
光标移动到附加网络卡片的文字部分,会弹出replace preview的按钮,点击后会将该卡片的预览图设为输出图片栏中正在浏览的图片
- 也可以把图片的名字设为和附加网络一样的名字,放在同一文件夹下来设置预览图,如bad-artist.pt和bad-artist.png
- 预览图必须是png,如果发现预览图没有加载很可能是预览图格式不对
推荐使用浏览器插件Tampermonkey的Civitai网站辅助脚本来下载附加网络,记录lora附加词和下载预览图都很方便
- Tampermonkey安装地址
- https://chrome.google.com/webstore/detail/tampermonkey/dhdgffkkebhmkfjojejmpbldmpobfkfo?hl
- Civitai网站辅助脚本安装地址
https://greasyfork.org/zh-CN/scripts/460557-civitai%E7%BD%91%E7%AB%99%E8%BE%85%E5%8A%A9
提示词和反向提示词
提示词内输入的东西就是你想要画的东西,反向提示词内输入的就是你不想要画的东西
几乎所有模型都只能理解英文词汇
- 所有符号都要使用英文半角,短语之间使用半角逗号隔开
-
一般原则
一般来说越靠前的词汇权重就会越高,比如说
car,1girl, 可能会出现一整辆车,旁边站着女孩
- 1girl,car, 可能会出现女孩肖像,背景是半辆车
所以多数情况下的提示词格式是
- 质量词,媒介词,主体,主体描述,背景,背景描述,艺术风格和作者
举个例子就是
- masterpiece, bestquality, sketch, 1girl, stand, black jacket, wall backgoround, full of poster, by token,
- 一张token画的高质量速写,内容是一个穿着黑色夹克的女孩站在铺满海报的墙前
但是实际上SD所使用的文本编码器会对一切文本产生反应,对于不同词的敏感度也完全不同,对于同一含义的不同词汇表达也会有不同的敏感度,并没有一定的规则,所以还是需要去亲自反复调试才能体会SD对各种词汇排列和组合的敏感度,形成一种大致的直觉
权重调节
最直接的权重调节就是调整词语顺序,越靠前权重越大,越靠后权重越低
可以通过下面的语法来对关键词设置权重,一般权重设置在0.5~2之间,可以通过选中词汇,按ctrl+↑↓来快速调节权重,每次步进为0.1
- (best quality:1.3)
以下方式也是网上常见的权重调节方式,但是调试起来不太方便所以并不推荐
- (best quality) = (best quality:1.1)
- ((best quality)) = (best quality:1.21) ,即(1.1 * 1.1)
[best quality] = (best quality:0.91)
起手式
现在我的建议是使用尽可能简洁的起手式,而不是早期特别冗长的起手式,因为提示词输入的越多ai绘画时间就会越长,同时分配给每个词汇的注意力也会越低,调试也会很困难
现在的模型相对于早期模型在词汇敏感性上有了长足的进步,所以不必担心提示词太短而导致画面效果不佳
简单的正面和反面起手式masterpiece, best quality, 1boy
- nsfw, (worst quality, bad quality:1.3)
稍长的正面和反面起手式
- masterpiece, best quality, highres, highly detailed, 1girl,
nsfw, bad anatomy, long neck, (worst quality, bad quality, normal quality:1.3), lowres
词条组合
几个词用括号合起来并不会让ai把他们视为一体,即使打上权重也不行,比如以下两者实际上是完全等价的
(car, rockt, gun:1.3)
- (car:1.3), (rocket:1.3), (gun:1.3)
词条组合的方式和自然语言差不多,要使用介词,比如and,with,of 等等,比如
-
采样方法
Euler a
速度最快的采样方式,对采样步数要求很低,同时随着采样步数增加并不会增加细节,会在采样步数增加到一定步数时构图突变,所以不要在高步数情景下使用
DPM++2S a Karras 和 DPM++ SDE Karras
这两个差不太多,似乎SDE的更好,总之主要特点是相对于Euler a来说,同等分辨率下细节会更多,比如可以在小图下塞进全身,代价是采样速度更慢
DDIM
如果使用的模型和lora出现了过拟合的现象,也就是图片有一种碎片化的撕裂感,使用DDIM并开高采样步数可以部分缓解,除此之外很少会用到,据说在Inpaint中会有比其他采样器更好的效果
采样步数
一般来说大部分时候采样部署只需要保持在20~30之间即可,更低的采样部署可能会导致图片没有计算完全,更高的采样步数的细节收益也并不高,只有非常微弱的证据表明高步数可以小概率修复肢体错误,所以只有想要出一张穷尽细节可能的图的时候才会使用更高的步数
生成批次和生成数量
生成批次是显卡一共生成几批图片
- 生成数量是显卡每批生成几张图片
也就是说你每点击一次生成按钮,生成的图片数量=批次*数量
需要注意的是生成数量是显卡一次所生成的图片数量,速度要比调高批次快一点,但是调的太高可能会导致显存不足导致生成失败,而生成批次不会导致显存不足,只要时间足够会一直生成直到全部输出完毕
输出分辨率(宽度和高度)
输出分辨率非常重要,直接决定了你的图片内容的构成和细节的质量
输出大小
输出大小决定了画面内容的信息量,很多细节例如全身构图中的脸部,饰品,复杂纹样等只有在大图上才能有足够的空间表现,如果图片过小,像是脸部则只会缩成一团,是没有办法充分表现的
但是图片越大ai就越倾向于往里面塞入更多的东西,绝大多数模型都是在512512分辨率下训练的,少数在768768下训练,所以当输出尺寸比较大比如说1024*1024的时候,ai就会尝试在图中塞入两到三张图片的内容量,于是会出现各种肢体拼接,不受词条控制的多人,多角度等情况,增加词条可以部分缓解,但是更关键的还是控制好画幅,先算中小图,再放大为大图
大致的输出大小和内容关系参考:
- 约30w像素,如512*512,大头照和半身为主
- 约60w像素,如768*768,单人全身为主,站立或躺坐都有
- 越100w像素,如1024*1024,单人和两三人全身,站立为主
-
宽高比例
宽高比例会直接决定画面内容,同样是1girl的例子:
方图512*512,会倾向于出脸和半身像
- 高图512*768,会倾向于出站着和坐着的全身像
- 宽图768*512,会倾向于出斜构图的半躺像
提示词相关性(CFG)
CFG很难去用语言去描述具体的作用,很笼统的来说,就是给你所有的正面和反面提示词都加上一个系数,所以一般CFG越低,画面越素,细节相对较少,CFG越高,画面越腻,细节相对较多
- 二次元风格CFG可以调的高一些以获得更丰富的色彩和质感表达,一般在7~12,也可以尝试12~20
写实风格CFG大都很低,一般在4~7,写实模型对CFG很敏感,稍微调多一点可能就会古神降临,可以以0.5为步进来细微调节
随机种子
随机种子可以锁定这张图的初始潜在空间状态,意思就是如果其他参数不变,同一个随机种子生成的图应该是完全相同的,可以通过锁定随机种子来观察各种参数对画面的影响,也可以用来复现自己和他人的画面结果
点击筛子按钮可以将随机种子设为-1,也就是随机
- 点击回收按钮可以将随机种子设为右边图片栏里正在看的那张图片的随机种子
需要注意的是,即使包括随机种子在内的所有参数相同,也不能保证你生成的而图片和他人完全一致,随着显卡驱动,显卡型号,webui版本等其他因素的变动,同参数输出的图片结果都会可能会发生变动,这种变动可能是细微的细节区别,可能是彻底的构图变化
面部修复
面部修复在早期模型生成的的写实图片分辨率不高的时候有一定价值,可以在低分辨率下纠正错误的写实人脸,但是现在的模型的脸部精度已经远超早期模型,而面部修复功能会改变脸部样貌,所以只要无视这个功能就好
其他
VAE设置
VAE的作用是修正最终输出的图片色彩,如果不加载VAE可能会出现图片特别灰的情况,设置位置:
- 设置-StabelDiffusion-模型的VAE
设置之后记得点击上方的保存设置,VAE是通用的,可以和任何模型组合
整合包已经自带了final-pruned.vae.pt,一般用来修正二次元模型,但是这个VAE可能会在图片计算完成之后提示错误:
- modules.devices.NansException: A tensor with all NaNs was produced in VAE. This could be because there’s no enough precision to represent this picture. Try adding —no-half-vae commandline to fix this.
如果出现这种情况,需要在启动器额外参数一栏填写—no-half-vae来解决
除了这个VAE,还有别的VAE可供使用,觉得颜色偏灰可以去切换使用:
- https://huggingface.co/stabilityai/sd-vae-ft-mse-original/resolve/main/vae-ft-mse-840000-ema-pruned.ckpt
- https://huggingface.co/stabilityai/sd-vae-ft-ema-original/resolve/main/vae-ft-ema-560000-ema-pruned.ckpt
VAE放置路径:*\models\VAE
新的VAE放置后可能需要重启webui
使用这两个VAE如果发现二次元图片算出来线条很粗还有红边紫边的情况,切换回final-pruned.vae.pt即可解决
图片信息
每个SD生成的图片都会自动写入相关参数信息,包括正面和反面提示词,采样步数,采样器,CFG,随机种子,尺寸,模型哈希,模型名称,Clip skip,超分参数等等
在图片信息界面拖入他人或者自己的原始图片都可以读取到参数信息,点击文生图等相应按钮即可将图片和参数一同复制到指定模块,需要注意的是他可能会改变你的webui不容易注意到的一些设置,比如controlnet等插件的设置,Clip skip,ENSD等等,如果后面用自己的参数算图发现不太对劲的时候可以检查一下这些部分
图片保存和浏览
所有输出的图片都会自动存放在以下路径,不同模块的图片都分开放置在相应文件夹下
- *\outputs
webui自带了一个图库浏览器,可以满足小规模的图片浏览,用来调取参数也更方便,但是毕竟是网页程序,在大规模图片管理方面还是使用资源管理器效率更高
40系显卡相关
如果你是40系显卡可能会需要替换整合包自带的cudnn文件来获得全部的计算速度性能,大概会有一倍以上的提升
在webui文件夹中搜索“cudnn”,找到cudnn文件所在的路径,将下载的压缩包解压,把包内bin文件夹中的文件全部复制到webui的cudnn文件所在的路径,并选择替换相应的文件
如果没有加速效果,可能是因为没有安装cuda和更新cuda的cudnn,可以参照以下视频操作更新
- https://www.bilibili.com/video/BV1xs4y1Y7NZ/?vd_source=46cfd585df52676c2171f114276670c3
隐私相关
StableDiffusion本身是完全离线运行的,所有程序都运行在本地,所有信息也存储在本地
SD模型只会在训练时学习图像数据,在生成图片时不会有任何模型信息被改变
有十分微弱的的证据表明SD会有一点语义残留的现象,就是在生成一张图片后,改变你的提示词,上一张图的一些元素会在下一张图中出现,但是这与SD模型的学习训练没有任何关系,可能只是一种优化出图速度的缓存方式导致的 :::info
🌍WeChat:eatsoo
:::
:::tips
抖音:袁锐钦丶点击进入
:::
:::info
🌍WeChat:eatsoo
:::
:::tips
抖音:袁锐钦丶点击进入
:::
:::success 哔哩哔哩:袁锐钦丶点击进入 :::

若有收获,就点个赞吧
0 人点赞
