概述(内容搬运@Token)
所有从已有图片生成新图片的方式,包括线稿上色,草图细化,风格转换,图片放大等等,本质上都是图生图,只不过从原始图片提取的信息有所区别,一次完整的图生图流程为下
- 输入图片
- 在提示词中对画面内容进行大致描述
- 选择贴合目标风格的模型
- 输出样图
- 根据样图找出参数,模型和提示词中的问题,作相应调整
- 重复4-5,直到输出满意的结果
图生图本质上,是AI根据你给出的图片和参数,在AI自己的理解上重新绘制了一张图片,AI并不能理解和继承你没有反映在参数上的任何和已有图片相关的知识和信息,所以想得到好的结果,就要去协助AI去认识你给出的输入图片,以及清楚地描述你想要的结果
界面元素
模型选择
模型会直接影响图生图输出的最终效果,特别是脸部效果,所以要根据想要的效果来选择图生图所使用的模型
- 真人模型,如ChilloutMix,输出材质会更写实,一般会带有较为强烈的光照,对复杂的细节元素识别较差,脸部和身材贴近真人比例
- 2.5d模型,如OrangeMixs,Chikmix,输出材质会较油腻,可能有一定泛光效果,对复杂的细节元素识别中等,脸部和身材有一定美化
- 二次元模型,如米山舞dbmai,线条感较强,基本没有材质表达,色彩丰富,对复杂元素识别最佳,脸部和身材会有夸张
目前并没有针对平面设计和场景设计的模型,对于场景设计而言真人和2.5d都会有不错的效果,因为其中融入了大量真实场景照片元素,不太推荐二次元模型,二次元模型基于手绘的场景数据库质量比较参差,输出效果会比较廉价
提示词和反向提示词
和文生图的提示词基本原则相同,想要提升图生图质量的关键要点在于尽可能详细的描述你的输入画面内容
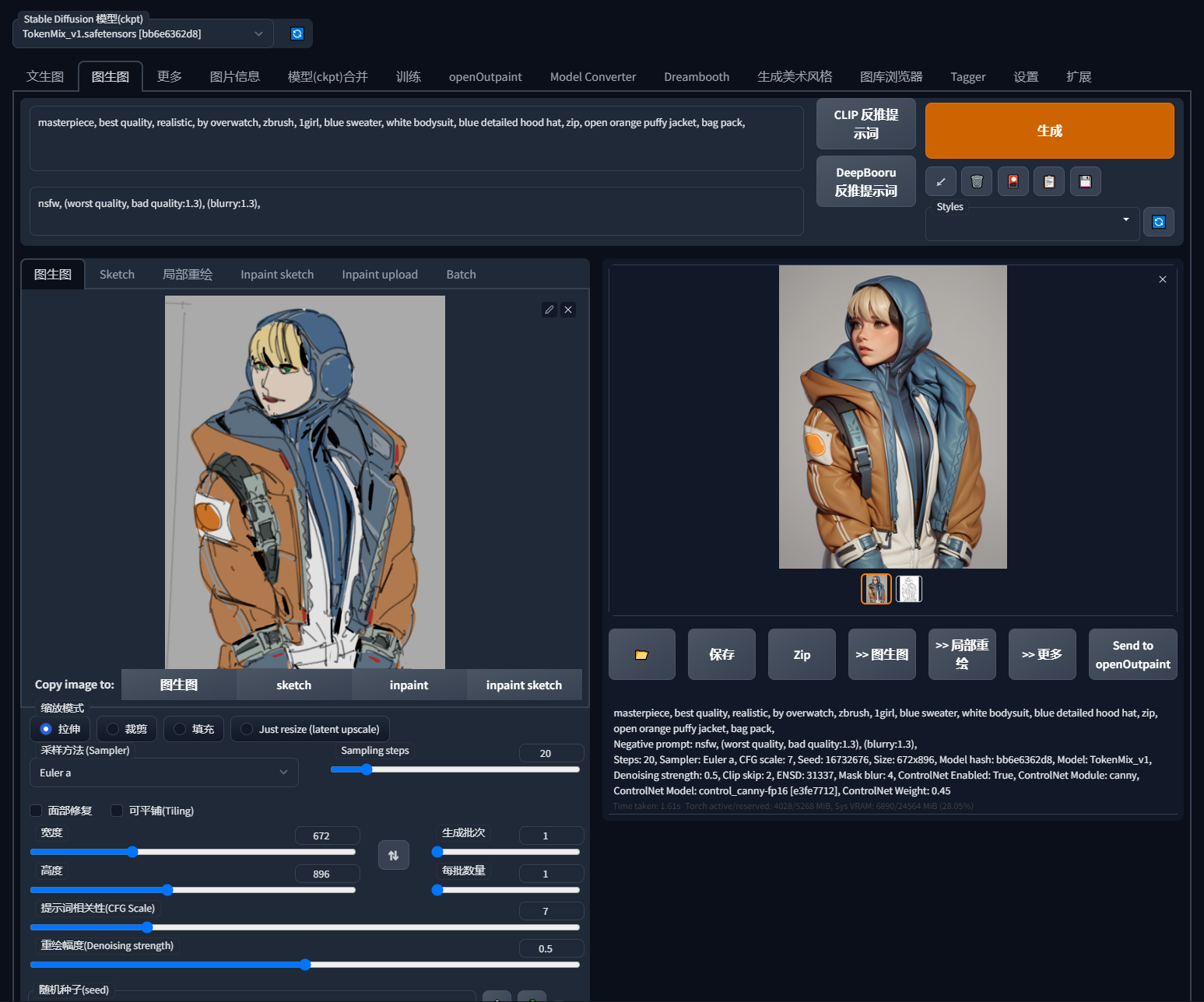
比如示意图的沃特森的提示词
- masterpiece, best quality, realistic, by overwatch, zbrush, 1girl, blue sweater, white bodysuit, blue detailed hood hat, zip, open orange puffy jacket, bag pack
- 杰作,最佳质量,写实,by守望先锋,zbrush,女孩,蓝色毛衣,白色连体衣,详细的蓝色兜帽,拉链,敞开的橙色蓬松外套,背包
提示词越详细效果就会越好,当然也不必太过细致,对于一些占比较大的关键元素进行描述即可,例如风格形式,主体,动作,关键性衣着和装备,环境描述
如果画面中出现你不想要的东西,在正面提示词中写你想要的东西的效果远大于在负面提示词中写你不想要的东西
输入图片
- 不能是带有透明像素的图片
- 图片尺寸不能太小,至少大于300*300左右,如果图片太小建议先放大一次
- 图片对比度不能太低,否则ai很难识别图片内容
尽可能把输入的图片的不必要部分提前裁剪,以减少运算时间和显存占用,但也不要完全贴合对象边缘裁剪,因为输入图片在图生图输出后主体边缘可能会有较大变化,需要提前留出空间
缩放模式
记得提前调节缩放模式,否则输出图片可能会在计算后出现压扁或者拉宽的情况
拉伸,会把原图拉伸成输出比例,也就是会压扁或拉宽
- 裁剪,最常用的模式,会根据输出比例进行裁剪,至少有一对边会顶到原图边缘,可以在调节宽高度的时候看到裁剪范围
- 填充,会尝试将原图置入输出图片中央,根据输出比例自补充图片上下或左右未覆盖的区域,实际使用并不稳定,一般不会用到
Just resize(latent upscale),和文生图的Hires.fix中的放大算法相同,可以理解为一种只能图生图使用的特殊采样器,不太常用
采样方法
一般会使用的采样方法和文生图一样,但是因为图生图会遇到一些超大输出分辨率的情况,所以会有点不同
如果输出分辨率较大(如1024*1024以上),重绘幅度较低(0.4以下),建议使用Euler a,可以大幅减少计算时间,也能降低图片因为细节过多而烂掉的概率
如果输出分辨率较小(如1024*1024以下),建议使用DPM++2S a Karras,DPM++ SDE Karras,DDIM,可以在小分辨率下容纳更多细节
采样步数
和文生图一样,20~30之间即可,决定画面质量的根本因素永远是分辨率大小,采样步数的作用有限
输出分辨率(宽度和高度)
输出大小
输出大小可以和原图大小不同,一般都是等于或大于原图大小,如果输出大小比原图大小大很多(如1.5倍以上),输出图片会有种朦胧感和涂抹感,所以在图生图之前都建议将原图放大一次再进行操作
输出大小会直接决定对原图细节的还原能力上限,对于比较精细的脸部,配件细节等都需要较大的输出大小去还原,如果发现脸部和配件还原不佳请调高输出大小输出比例
提示词相关性(CFG)
和文生图一样,想要更艳更腻就调高,想要更素更整就调低,注意配合模型类型进行调整
重绘幅度(Denoising strength)
重绘幅度直接决定了对输入图片的还原程度
在没有开启controlnet插件的前提下的临界点示例0,啥都不做,原图在调节分辨率后直出
- 0.3左右,仅仅调节质感和修改部分细节的临界点
- 0.5左右,修改部分细节和修改部分构成的临界点
- 0.7左右,修改部分构成和小幅重构原图的临界点
- 0.9左右,基本和原图无关了,仅大体颜色上会有一点参考
- 1,完全和原图无关,等于在图生图界面下进行文生图
关于重绘幅度有几点需要注意的

若有收获,就点个赞吧
0 人点赞
