https://www.bilibili.com/video/BV1gZ4y1x7p7
字符集
字符集(Character set)是多个字符的集合,字符集种类较多,每个字符集包含的字符个数不同,常见字符集名称:ASCII字符集、GB2312字符集、BIG5字符集、 GB18030字符集、Unicode字符集等。
码位:就是字符集中某个字符的唯一编号。
将每一个字符对应到一个专属的码位(code point),就可以表示这套字符集中的每一个字符。
ASCII字符集
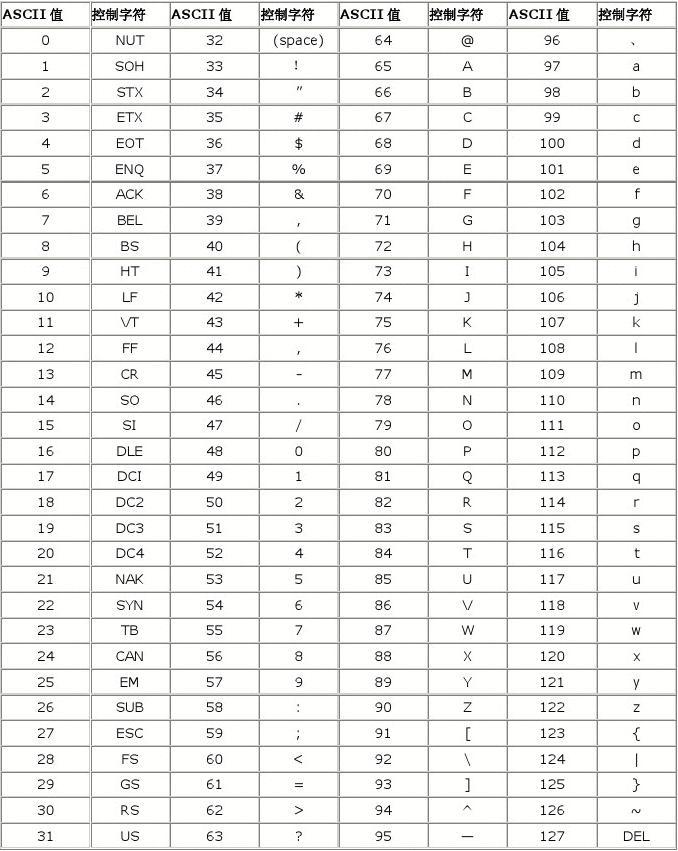
ASCII 总共128个字符,给每个字符一个编码,这个编码就是码位,表示128个码位只要一个字节就可以了。
ISO-8859-1
ISO-8859-1编码是单字节编码,向下兼容ASCII,其编码范围是0x00-0xFF,0x00-0x7F之间完全和ASCII一致,0x80-0x9F之间是控制字符,0xA0-0xFF之间是文字符号。
GB2312
分区表示
整个字符集分成94个区,每区有94个位,共8836个码位。每个区位上只有一个字符(汉字或符号),因此可用所在的区和位来对汉字进行编码,称为区位码。
01-09 区为特殊符号。除汉字以外的682个字符。
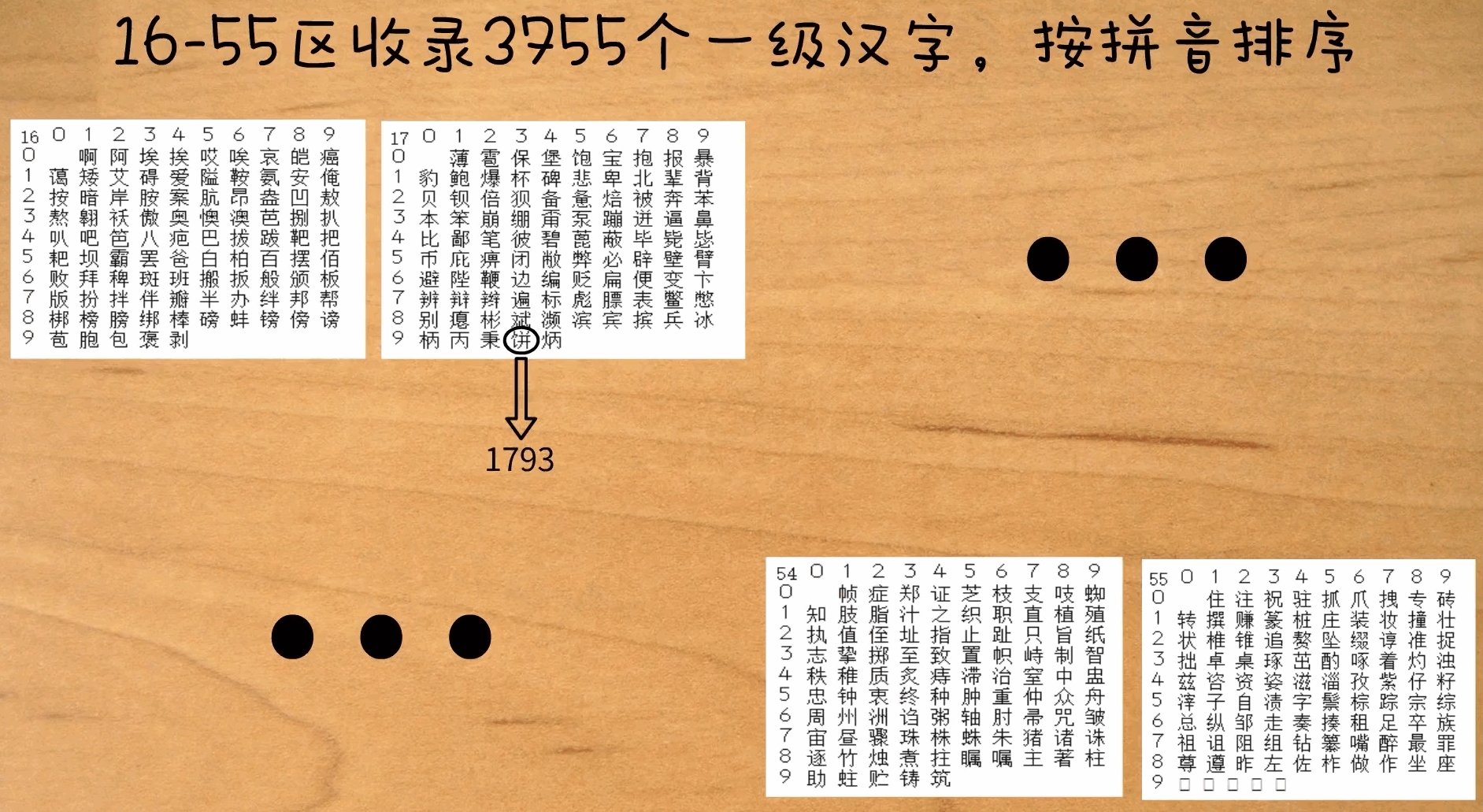
16-55 区为一级汉字,按拼音排序。
56-87 区为二级汉字,按部首/笔画排序。
10-15 区及88-94区则未有编码。
0389就是字符y的区位码。03 表示第3区,8和9确定具体位置。
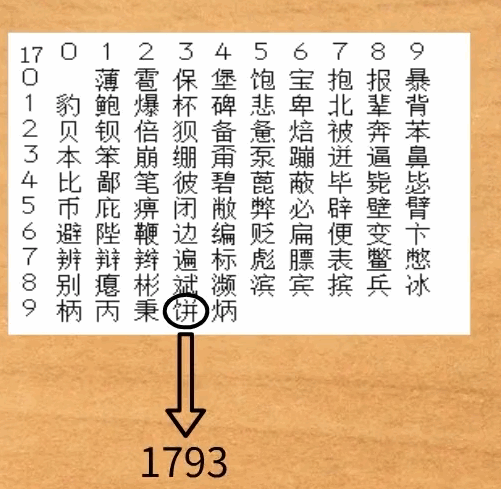
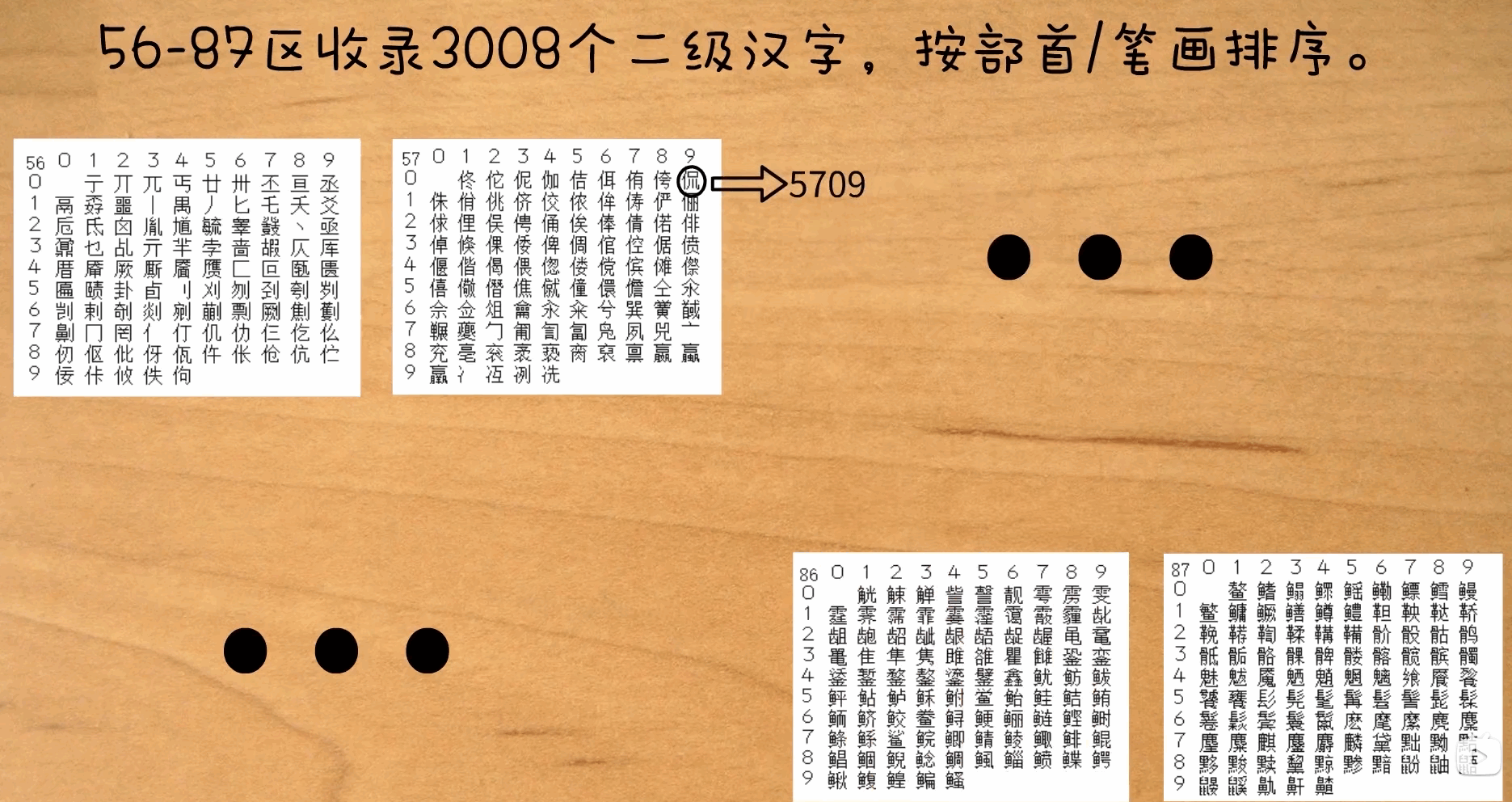
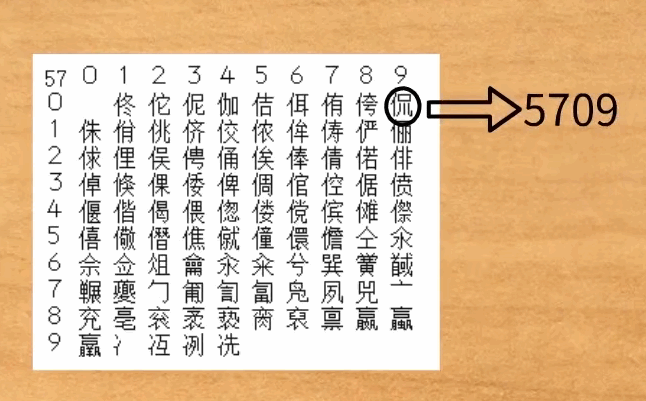

@Testpublic void test_3() throws UnsupportedEncodingException {byte[] gb2312s = "侃".getBytes("GB2312");System.out.println(Arrays.toString(gb2312s)); //[-39, -87]System.out.println(0xA0); // 160System.out.println(-39 - 0xA0); // -199 byte最小也只有-128System.out.println(-199 & 0xff); // 57System.out.println(-87 - 0xA0); // -247System.out.println(-247 & 0xff); // 9 -> 09}
@Testpublic void test_6() throws UnsupportedEncodingException {byte[] b = "侃".getBytes("gb2312");String ret = "";for (int i = 0; i < b.length; i++) {String hex = Integer.toHexString(b[i] & 0xFF);if (hex.length() == 1) {hex = '0' + hex;}ret += hex.toUpperCase();}System.out.println(ret); // D9A9}
特别注意:Java中byte转换int时与0xff进行与运算
@Testpublic void test_5() {byte b = -127;System.out.println(b); // -127 byte是一个字节 补码是 10000001int c = b & 0xff; // int 是4个字节 1111111111111111111111111 10000001 & 11111111 -> 00000000000000000000000 10000001 现在最高位是0,128+1 = 129System.out.println(c); // 129}
@Testpublic void test_4() {byte[] a = new byte[10];// 当将-127赋值给a[0]时候,a[0]作为一个byte类型,其计算机存储的补码是10000001(8位)。a[0] = -127;// 将a[0] 作为int类型向控制台输出的时候,jvm作了一个补位的处理,// 因为int类型是32位所以补位后的补码就是1111111111111111111111111 10000001(32位),这个32位二进制补码表示的也是-127.// 注意: 补位是补1 还是补0,取决于byte的最高位是1还是0//虽然byte->int计算机背后存储的二进制补码由10000001(8位)转化成了 1111111111111111111111111 10000001(32位)很显然这两个补码表示的十进制数字依然是相同的。System.out.println(a[0]); // -127 这个是10进制的结果没变 但是二进制表示变了//因为byte占1个字节,所以0xff刚还是一个字节,保证这一个字节的补码不变int c = a[0] & 0xff; // 1111111111111111111111111 10000001 & 11111111 -> 00000000000000000000000 10000001 现在最高位是0,128+1 = 129System.out.println(c); // 129 十进制表示的结果变了,但是二进制的表示没有变}
//获取传入字符串在gb2312字符集的区位码public static StringBuffer getQuweiCode(String str) throws Exception {StringBuffer sb = new StringBuffer();byte[] b = str.getBytes("gb2312");int[] quwei = new int[b.length / 2];for (int i = 0, k = b.length / 2; i < k; i++) {quwei[i] = (((b[2 * i] - 0xA0) & 0xff) * 100) + ((b[2 * i + 1] - 0xA0) & 0xff);}for (int i : quwei) {sb.append(i);}return sb;}
GBK
GBK是采用单双字节变长编码,英文使用单字节编码,完全兼容ASCII字符编码,中文部分采用双字节编码。
Unicode

UTF-8
UTF-8的特点是对不同范围的字符使用不同长度的编码。
简单来说:
- Unicode 是「字符集」
- UTF-8 是「编码规则」
字符集:为每一个「字符」分配一个唯一的 ID(学名为码位 / 码点 / Code Point)
编码规则:将「码位」转换为字节序列的规则(编码/解码 可以理解为 加密/解密 的过程)
广义的 Unicode 是一个标准,定义了一个字符集以及一系列的编码规则,即 Unicode 字符集和 UTF-8、UTF-16、UTF-32 等等编码。
Unicode 字符集为每一个字符分配一个码位,例如「知」的码位是 30693,记作 U+77E5(30693 的十六进制为 0x77E5)。
UTF-8 顾名思义,是一套以 8 位为一个编码单位的可变长编码。
将一个码位编码为 1 到 4 个字节:
U+ 0000 ~ U+ 007F: 0XXXXXXXU+ 0080 ~ U+ 07FF: 110XXXXX 10XXXXXXU+ 0800 ~ U+ FFFF: 1110XXXX 10XXXXXX 10XXXXXXU+10000 ~ U+10FFFF: 11110XXX 10XXXXXX 10XXXXXX 10XXXXXX
根据上表中的编码规则,之前的「知」字的码位 U+77E5 属于第三行的范围:
7 7 E 50111 0111 1110 0101 二进制的 77E5--------------------------0111 011111 100101 二进制的 77E51110XXXX 10XXXXXX 10XXXXXX 模版(上表第三行)11100111 10011111 10100101 代入模版E 7 9 F A 5
import java.nio.charset.Charset;import java.util.Arrays;public class Test2 {public static void main(String[] args) {// 获取JVM默认字符集System.out.println(Charset.defaultCharset()); //UTF-8//16进制 77E5 转为 10进制为 30693Integer x = Integer.valueOf("77E5", 16);System.out.println(x); // 30693String b = Integer.toBinaryString(x);System.out.println(b); // 0111 0111 1110 0101 (最高位补零)byte x1 = (byte) Integer.parseUnsignedInt("11100111", 2);byte x2 = (byte) Integer.parseUnsignedInt("10011111", 2);byte x3 = (byte) Integer.parseUnsignedInt("10100101", 2);System.out.println(String.format("x1=%s, x2=%s, x3=%s", x1, x2, x3));byte[] bytes = {x1, x2, x3};System.out.println(new String(bytes));System.out.println(Arrays.toString("知".getBytes()));}}
UTF-8 30693 111011111100101 x1=-25, x2=-97, x3=-91
知
[-25, -97, -91]
String 字符串提供了一个public int codePointAt(int index) 返回指定索引处的字符(Unicode代码点)
System.out.println("知".codePointAt(0)); //30693

比如『汉』这个字的Unicode编码是0x6C49。0x6C49在0x0800-0xFFFF之间,使用3字节模板:1110xxxx 10xxxxxx 10xxxxxx。将0x6C49写成二进制是:0110 1100 0100 1001, 用这个比特流依次代替模板中的x,得到:11100110 10110001 10001001。
比如【王】

若有收获,就点个赞吧
0 人点赞
