1. 编码和解码
我们都知道人有人的语言,计算机有计算机的语言,就是机器语言,所谓的二进制,0和1,1代表有一个信号,0表示没有信号。那怎么把人的语言翻译成机器语言呢,就需要一个字典,字典就是ASCII,如下图,左边是机器可以识别的ASCII码,右面是代表的字符,比如 00100001 代表 “!”, 从左到右转换就是解码 (decode),从右到左就是编码 (encode)。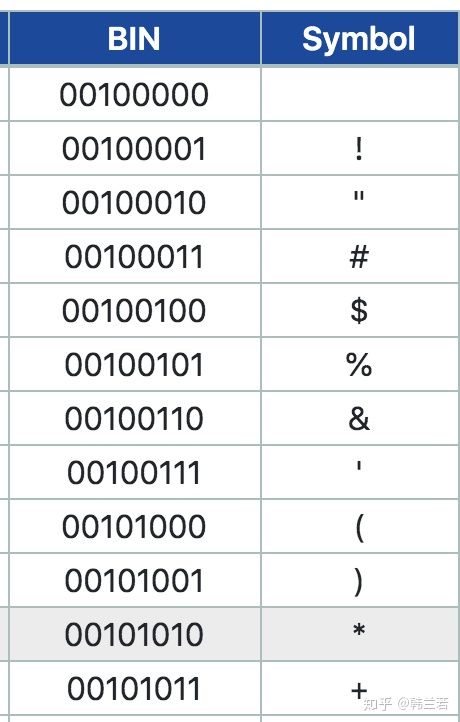
因为ASIIC码有8位数,每位是一个比特 (bit),8位就是一个字节 (byte)。除了第一位是0, 其他7位都可以有0 或者 1 两个选择,所以ASCII 一共可以表示 2^7 ,也就是128个字符。包括a-z 大小写,0-9 数字 和一些标点符号等。其中真正可读的只有95 个字符,其他的都是一些控制符,比如NUL,代表NULL。
对于英语来说, ASCII 包括所有的字母了,但是对于其他的语言来说,比如汉语,当然95个字符远远不够。有人说ASCII的第一位只能是0很浪费,如果也可以是1 的话, 就会多128个组合,一共256个。然而这样也不够。所以我们有多字节编码.
2. 多字节编码
上述编码是单字节编码, 也就是只有8个比特。如果想匹配多于256个字符的语言,一个字节显然不够,用两个字节的话,16比特,可以编码65536个字符,BIG-5就是一个双字节编码方式,它包括大多数中文繁体字,GB18030 则包括繁体和简体。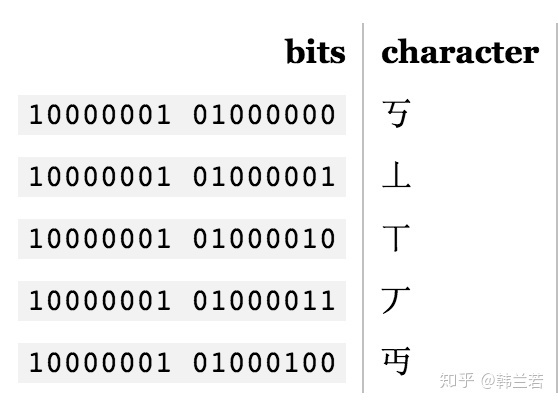
这样每种语言可能都有他们的编码体系,用着不同的字节,对于人和机器来说,这样都很容易混乱。所以我们有统一编码 Unicode.
3. 统一编码 Unicode
像上文说的,对于一些语言单字节编码不够,所以采用双字节,双字节也不够的时候可以采用三字节,甚至四字节,字节是不是越多越好呢?并不是,因为字节用的越多,那些用单字节就能表示的字符会增加很多个0, 浪费很多容量。比如 A 可能就是00000000 00000000 00000000 01000001, 这样就没有必要了。
如果一个人想写不同的语言,那他最好使用Unicode。 Unicode 用多少个字节呢?答案是0个。
因为Unicode其实不是一种编码, 而是定义了一个表, 表中为世界上每种语言中的每个字符设定了统一并且唯一的码位 (code point),以满足跨语言、跨平台进行文本转换的要求。在表示一个Unicode的字符时,通常会用“U+”然后紧接着一组十六进制的数字来表示这一个字符。如下图。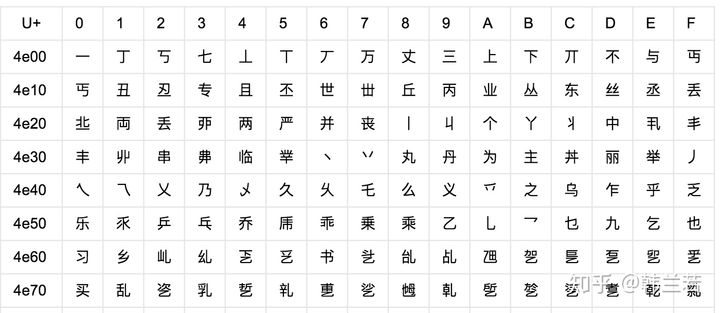
比如一个人想写一篇文章,包括英语和日语,单字节编码可以表示英语,但是显然不能满足他写日语,因为他需要3个字节才能表示一个『あ』,也就是11100011 10000001 10000010。 他可以用双字节编码,这样他只需要一个双字节,也就是00110000 01000010。所以他可以选择语言最高所需要的编码,也就是UTF-16. 如果他只需要写英语, 那UTF-8就可以。
4. UTF-8
UTF-8的特点是对不同范围的字符使用不同长度的编码。
上表表示如何从一个从Unicode 转化到UTF-8 , 对于前0x7F的字符,UTF-8编码和ASCII码是一一对应的。如果一个字符在000800-00FFFF 之间,那转化到UTF-8 需要用三字节模板,使用16个码位,每个x 就是一个码位。
比如『汉』这个字的Unicode编码是0x6C49。0x6C49在0x0800-0xFFFF之间,使用3字节模板:1110xxxx 10xxxxxx 10xxxxxx。将0x6C49写成二进制是:0110 1100 0100 1001, 用这个比特流依次代替模板中的x,得到:11100110 10110001 10001001。
当然如果用16位更节约空间。对于中文而言,Unicode 16编码里面已经包含了GB18030里面的所有汉字(27484个字)。

若有收获,就点个赞吧
0 人点赞
