《阿里巴巴Java开发手册》关于 Object 的 clone 问题的描述 :
【推荐】慎用 Object 的 clone 方法来拷贝对象。
说明:对象 clone 方法默认是浅拷贝,若想实现深拷贝需覆写 clone 方法实现域对象的深度遍历式拷贝。
1. 什么是拷贝?
对象的拷贝,就是根据原来的对象 “复制” 一份属性、状态一致的新的对象。
2. 为什么需要拷贝
- 为了复制一个已经存在的对象,通过修改部分属性的值可以快速得到一个新的对象
- 降低创建对象的复杂度,不需要从头开始去创建对象
- 降低了创建对象带来的性能消耗
- 多线程环境下,可以每个线程操作不同的对象拷贝,互相不影响
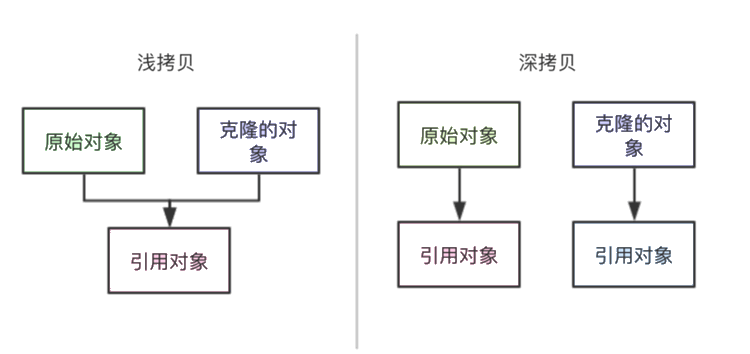
3. 什么是浅拷贝?浅拷贝和深拷贝的区别是什么?
Object的clone函数默认是浅拷贝。
浅拷贝:对于基本数据类型复制的是值,对于引用类型复制的是引用,而不是对象本身。protected native Object clone() throws CloneNotSupportedException;
深拷贝:无论是基本数据类型还是引用类型,都是对对象值的拷贝。Java 中的数据类型分为基本数据类型和引用数据类型。对于这两种数据类型,在进行赋值操作、用作方法参数或返回值时,会有值传递和引用(地址)传递的差别。
4. Java 拷贝需要实现接口Cloneable
- 如果调用
clone函数的类没有实现Cloneable接口将会抛出CloneNotSupportedException。因此要实现Cloneable接口。 - 重写
clone函数是为了供外部使用,因此定义为public。 -
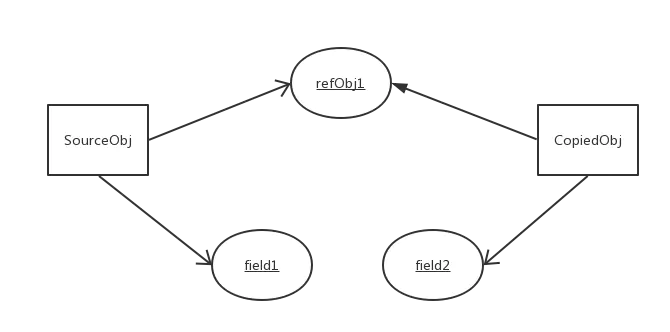
5. 浅拷贝特点
对于基本数据类型的成员对象,因为基础数据类型是值传递的,所以是直接将属性值赋值给新的对象。基础类型的拷贝,其中一个对象修改该值,不会影响另外一个。
对于引用类型,比如数组或者类对象,因为引用类型是引用传递,所以浅拷贝只是把内存地址赋值给了成员变量,它们指向了同一内存空间。改变其中一个,会对另外一个也产生影响。
6. 浅拷贝的实现
实现对象拷贝的类,需要实现
Cloneable接口,并覆写clone()方法。public class Subject {private String name;public Subject(String name) {this.name = name;}public String getName() {return name;}public void setName(String name) {this.name = name;}@Overridepublic String toString() {return "[Subject: " + this.hashCode() + ",name:" + name + "]";}}
public class Student implements Cloneable {//引用类型private Subject subject;//基本数据类型private String name;private int age;//getter/setter/*** 重写clone()方法*/@Overridepublic Object clone() {try {// 直接调用父类的clone()方法 浅拷贝return super.clone();} catch (CloneNotSupportedException e) {return null;}}@Overridepublic String toString() {return "[Student hashcode: " + this.hashCode() + ",subject:" + subject +",name:" + name + ",age:" + age + "]";}}
public class ShallowCopy {public static void main(String[] args) {Subject subject = new Subject("yuwen");Student studentA = new Student();studentA.setSubject(subject);studentA.setName("Lynn");studentA.setAge(20);//拷贝一个对象Student studentB = (Student) studentA.clone();studentB.setName("Lily");studentB.setAge(18);Subject subjectB = studentB.getSubject();subjectB.setName("lishi");System.out.println("studentA:" + studentA.toString());System.out.println("studentB:" + studentB.toString());}}
studentA:[Student hashcode: 1554874502,subject:[Subject: 1846274136,name:lishi],name:Lynn,age:20]studentB:[Student hashcode: 1639705018,subject:[Subject: 1846274136,name:lishi],name:Lily,age:18]
由输出的结果可见,通过
studentA.clone()拷贝对象后得到的studentB,和studentA是两个不同的对象。studentA和studentB的基础数据类型的修改互不影响,而引用类型subject修改后是会有影响的。7. 深拷贝介绍
通过上面的例子可以看到,浅拷贝会带来数据安全方面的隐患,例如我们只是想修改了
studentB的subject,但是studentA的subject也被修改了,因为它们都是指向的同一个地址。所以,此种情况下,我们需要用到深拷贝。
深拷贝,在拷贝引用类型成员变量时,为引用类型的数据成员另辟了一个独立的内存空间,实现真正内容上的拷贝。
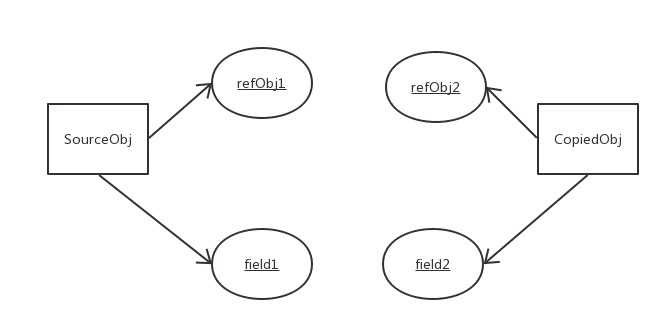
8. 深拷贝特点
- 对于基本数据类型的成员对象,因为基础数据类型是值传递的,所以是直接将属性值赋值给新的对象。基础类型的拷贝,其中一个对象修改该值,不会影响另外一个(和浅拷贝一样)。
- 对于引用类型,比如数组或者类对象,深拷贝会新建一个对象空间,然后拷贝里面的内容,所以它们指向了不同的内存空间。改变其中一个,不会对另外一个也产生影响。
- 对于有多层对象的,每个对象都需要实现
Cloneable并重写clone()方法,进而实现了对象的串行层层拷贝。 深拷贝相比于浅拷贝速度较慢并且花销较大。
9. 深拷贝的实现
对于
Student的引用类型的成员变量Subject,需要实现Cloneable并重写clone()方法。public class Subject implements Cloneable {private String name;public Subject(String name) {this.name = name;}public String getName() {return name;}public void setName(String name) {this.name = name;}@Overrideprotected Object clone() throws CloneNotSupportedException {//Subject 如果也有引用类型的成员属性,也应该和 Student 类一样实现return super.clone();}@Overridepublic String toString() {return "[Subject: " + this.hashCode() + ",name:" + name + "]";}}
在
Student的clone()方法中,需要拿到拷贝自己后产生的新的对象,然后对新的对象的引用类型再调用拷贝操作,实现对引用类型成员变量的深拷贝。public class Student implements Cloneable {//引用类型private Subject subject;//基础数据类型private String name;private int age;/*** 重写clone()方法* @return*/@Overridepublic Object clone() {//深拷贝try {// 直接调用父类的clone()方法Student student = (Student) super.clone();student.subject = (Subject) subject.clone();return student;} catch (CloneNotSupportedException e) {return null;}}@Overridepublic String toString() {return "[Student: " + this.hashCode() + ",subject:" + subject + ",name:"+ name + ",age:" + age + "]";}}
public class ShallowCopy {public static void main(String[] args) {Subject subject = new Subject("yuwen");Student studentA = new Student();studentA.setSubject(subject);studentA.setName("Lynn");studentA.setAge(20);Student studentB = (Student) studentA.clone();studentB.setName("Lily");studentB.setAge(18);Subject subjectB = studentB.getSubject();subjectB.setName("lishi");System.out.println("studentA:" + studentA.toString());System.out.println("studentB:" + studentB.toString());}}
studentA:[Student: 460141958,subject:[Subject: 1163157884,name:yuwen],name:Lynn,age:20]studentB:[Student: 1956725890,subject:[Subject: 356573597,name:lishi],name:Lily,age:18]
由输出结果可见,深拷贝后,不管是基础数据类型还是引用类型的成员变量,修改其值都不会相互造成影响。
10. 序列化方式实现深拷贝
序列化通过将原始对象转化为字节流,再从字节流重建新的 Java 对象,因此原始对象和反序列化后的对象修改互不影响。因此可以使用之前讲到的序列化和反序列化方式来实现深拷贝。
10.1 自定义序列化工具函数
/*** JDK序列化方式深拷贝*/public static <T> T deepClone(T origin) throws IOException, ClassNotFoundException {ByteArrayOutputStream outputStream = new ByteArrayOutputStream();try (ObjectOutputStream objectOutputStream = new ObjectOutputStream(outputStream);) {objectOutputStream.writeObject(origin);objectOutputStream.flush();}byte[] bytes = outputStream.toByteArray();try (ByteArrayInputStream inputStream = new ByteArrayInputStream(bytes);) {return JdkSerialUtil.readObject(inputStream);}}
10.2 commons-lang3 的序列化工具类
可以使用 commons-lang3 (3.7 版本)的序列化工具类:
org.apache.commons.lang3.SerializationUtils#clone。@Testpublic void serialUtil() {Order order = OrderMocker.mock();// 使用方式Order cloneOrder = SerializationUtils.clone(order);assertFalse(order == cloneOrder);assertFalse(order.getItemList() == cloneOrder.getItemList());}
序列化的对象和嵌套的对象都要实现序列化接口Serializable。
10.3 JSON序列化
我们还可以通过 JSON 序列化方式实现深拷贝。
下面我们利用 Google 的 Gson 库(2.8.5 版本),实现基于 JSON 的深拷贝:
首先我们将深拷贝方法封装到拷贝工具类中:/*** Gson方式实现深拷贝*/public static <T> T deepCloneByGson(T origin, Class<T> clazz) {Gson gson = new Gson();return gson.fromJson(gson.toJson(origin), clazz);}
使用时直接调用封装的工具方法即可:
@Testpublic void withGson() {Order order = OrderMocker.mock();// gson序列化方式Order cloneOrder = CloneUtil.deepCloneByGson(order, Order.class);assertFalse(order == cloneOrder);assertFalse(order.getItemList() == cloneOrder.getItemList());}
使用 JSON 序列化方式实现深拷贝的好处是,性能比 Java 序列化方式更好,更重要的是不要求序列化对象以及成员属性(嵌套)都要实现序列化接口。

若有收获,就点个赞吧
0 人点赞
