Go内存管理与内存清理 https://mp.weixin.qq.com/s/gTk2UcVCv4a0xuP44oqZhg
介绍
了解操作系统对内存的管理机制后,现在可以去看下 Go 语言是如何利用底层的这些特性来优化内存的。Go 的内存管理基本上参考 tcmalloc 来实现的,只是细节上根据自身的需要做了一些小的优化调整。
Go 的内存是自动管理的,我们可以随意定义变量直接使用,不需要考虑变量背后的内存申请和释放的问题。本文意在搞清楚 Go 在方面帮我们做了什么,使我们不用关心那些复杂内存的问题,还依旧能写出较为高效的程序。
本篇只介绍 Go 的内存管理模型,与其相关的还有逃逸分析和垃圾回收内容,因为篇幅的关系,打算后面找时间各自整理出一篇。
池
程序动态申请内存空间,是要使用系统调用的,比如 Linux 系统上是调用 mmap 方法实现的。但对于大型系统服务来说,直接调用 mmap 申请内存,会有一定的代价。比如:
- 系统调用会导致程序进入内核态,内核分配完内存后(也就是上篇所讲的,对虚拟地址和物理地址进行映射等操作),再返回到用户态。
- 频繁申请很小的内存空间,容易出现大量内存碎片,增大操作系统整理碎片的压力。
- 为了保证内存访问具有良好的局部性,开发者需要投入大量的精力去做优化,这是一个很重的负担。
如何解决上面的问题呢?有经验的人,可能很快就想到解决方案,那就是我们常说的对象池(也可以说是缓存)。
假设系统需要频繁动态申请内存来存放一个数据结构,比如 [10]int。那么我们完全可以在程序启动之初,一次性申请几百甚至上千个 [10]int。这样完美的解决了上面遇到的问题:
- 不需要频繁申请内存了,而是从对象池里拿,程序不会频繁进入内核态
- 因为一次性申请一个连续的大空间,对象池会被重复利用,不会出现碎片。
- 程序频繁访问的就是对象池背后的同一块内存空间,局部性良好。
这样做会造成一定的内存浪费,我们可以定时检测对象池的大小,保证可用对象的数量在一个合理的范围,少了就提前申请,多了就自动释放。
如果某种资源的申请和回收是昂贵的,我们都可以通过建立资源池的方式来解决,其他比如连接池,内存池等等,都是一个思路。
Golang 内存管理
Golang 的内存管理本质上就是一个内存池,只不过内部做了很多的优化。比如自动伸缩内存池大小,合理的切割内存块等等。
内存池 mheap
Golang 的程序在启动之初,会一次性从操作系统那里申请一大块内存作为内存池。这块内存空间会放在一个叫 mheap 的 struct 中管理,mheap 负责将这一整块内存切割成不同的区域,并将其中一部分的内存切割成合适的大小,分配给用户使用。
我们需要先知道几个重要的概念:
**page**: 内存页,一块8K大小的内存空间。Go 与操作系统之间的内存申请和释放,都是以page为单位的。**span**: 内存块,一个或多个连续的page组成一个span。如果把page比喻成工人,span可看成是小队,工人被分成若干个队伍,不同的队伍干不同的活。**sizeclass**: 空间规格,每个span都带有一个sizeclass,标记着该span中的page应该如何使用。使用上面的比喻,就是sizeclass标志着span是一个什么样的队伍。**object**: 对象,用来存储一个变量数据内存空间,一个span在初始化时,会被切割成一堆等大的object。假设object的大小是16B,span大小是8K,那么就会把span中的page就会被初始化8K / 16B = 512个object。所谓内存分配,就是分配一个object出去。
示意图: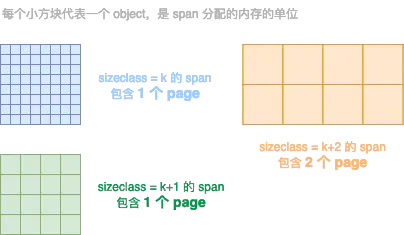
上图中,不同颜色代表不同的 span,不同 span 的 sizeclass 不同,表示里面的 page 将会按照不同的规格切割成一个个等大的 object 用作分配。
使用 Go1.11.5 版本测试了下初始堆内存应该是 64M 左右,低版本会少点。
测试代码:
package mainimport "runtime"var stat runtime.MemStatsfunc main() {runtime.ReadMemStats(&stat)println(stat.HeapSys)}
内部的整体内存布局如下图所示: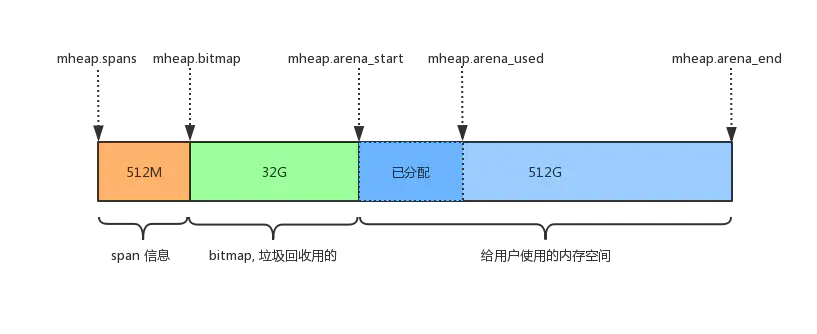
mheap.spans:用来存储page和span信息,比如一个 span 的起始地址是多少,有几个 page,已使用了多大等等。mheap.bitmap存储着各个span中对象的标记信息,比如对象是否可回收等等。mheap.arena_start: 将要分配给应用程序使用的空间。
再说明下,图中的空间大小,是 Go 向操作系统申请的虚拟内存地址空间,操作系统会将该段地址空间预留出来不做它用;而不是真的创建出这么大的虚拟内存,在页表中创建出这么大的映射关系。
mcentral
用途相同的 span 会以链表的形式组织在一起。 这里的用途用 sizeclass 来表示,就是指该 span 用来存储哪种大小的对象。比如当分配一块大小为 n 的内存时,系统计算 n 应该使用哪种 sizeclass,然后根据 sizeclass 的值去找到一个可用的 span 来用作分配。其中 sizeclass 一共有 67 种(Go1.5 版本,后续版本可能会不会改变不好说),如图所示: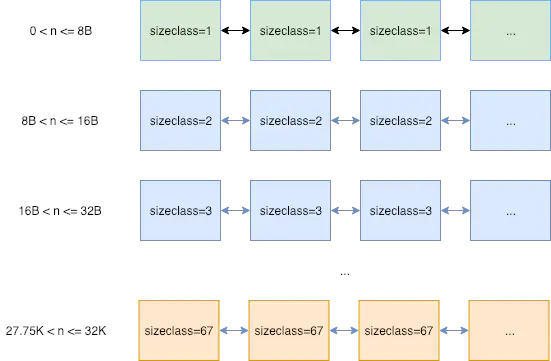
找到合适的 span 后,会从中取一个 object 返回给上层使用。这些 span 被放在一个叫做 mcentral 的结构中管理。
mheap 将从 OS 那里申请过来的内存初始化成一个大 span(sizeclass=0)。然后根据需要从这个大 span 中切出小 span,放在 mcentral 中来管理。大 span 由 mheap.freelarge 和 mheap.busylarge 等管理。如果 mcentral 中的 span 不够用了,会从 mheap.freelarge 上再切一块,如果 mheap.freelarge 空间不够,会再次从 OS 那里申请内存重复上述步骤。下面是 mheap 和 mcentral 的数据结构:
type mheap struct {// other fieldslock mutexfree [_MaxMHeapList]mspan // free lists of given length, 1M 以下freelarge mspan // free lists length >= _MaxMHeapList, >= 1Mbusy [_MaxMHeapList]mspan // busy lists of large objects of given lengthbusylarge mspan // busy lists of large objects length >= _MaxMHeapListcentral [_NumSizeClasses]struct { // _NumSizeClasses = 67mcentral mcentral// other fields}// other fields}// Central list of free objects of a given size.type mcentral struct {lock mutex // 分配时需要加锁sizeclass int32 // 哪种 sizeclassnonempty mspan // 还有可用的空间的 span 链表empty mspan // 没有可用的空间的 span 列表}
这种方式可以避免出现外部碎片(文章最后面有外部碎片的介绍),因为同一个 span 是按照固定大小分配和回收的,不会出现不可利用的一小块内存把内存分割掉。这个设计方式与现代操作系统中的伙伴系统有点类似。
mcache
如果你阅读的比较仔细,会发现上面的 mcentral 结构中有一个 lock 字段;因为并发情况下,很有可能多个线程同时从 mcentral 那里申请内存的,必须要用锁来避免冲突。
但锁是低效的,在高并发的服务中,它会使内存申请成为整个系统的瓶颈;所以在 mcentral 的前面又增加了一层 mcache。
每一个 mcache 和每一个处理器(P) 是一一对应的,也就是说每一个 P 都有一个 mcache 成员。 Goroutine 申请内存时,首先从其所在的 P 的 mcache 中分配,如果 mcache 没有可用 span,再从 mcentral 中获取,并填充到 mcache 中。
从 mcache 上分配内存空间是不需要加锁的,因为在同一时间里,一个 P 只有一个线程在其上面运行,不可能出现竞争。没有了锁的限制,大大加速了内存分配。
所以整体的内存分配模型大致如下图所示: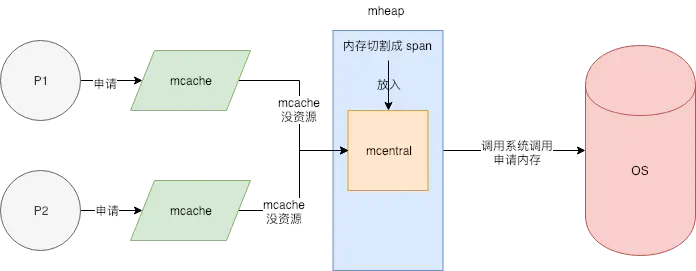
其他优化
zero size
有一些对象所需的内存大小是0,比如 [0]int, struct{},这种类型的数据根本就不需要内存,所以没必要走上面那么复杂的逻辑。
系统会直接返回一个固定的内存地址。源码如下:
func mallocgc(size uintptr, typ *_type, flags uint32) unsafe.Pointer {// 申请的 0 大小空间的内存if size == 0 {return unsafe.Pointer(&zerobase)}//.....}
测试代码:
package mainimport ("fmt")func main() {var (a struct{}b [0]intc [100]struct{}d = make([]struct{}, 1024))fmt.Printf("%p\n", &a)fmt.Printf("%p\n", &b)fmt.Printf("%p\n", &c)fmt.Printf("%p\n", &(d[0]))fmt.Printf("%p\n", &(d[1]))fmt.Printf("%p\n", &(d[1000]))}// 运行结果,6 个变量的内存地址是相同的:0x1180f880x1180f880x1180f880x1180f880x1180f880x1180f88
Tiny对象
上面提到的 sizeclass=1 的 span,用来给 <= 8B 的对象使用,所以像 int32, byte, bool 以及小字符串等常用的微小对象,都会使用 sizeclass=1 的 span,但分配给他们 8B 的空间,大部分是用不上的。并且这些类型使用频率非常高,就会导致出现大量的内部碎片。
所以 Go 尽量不使用 sizeclass=1 的 span, 而是将 < 16B 的对象为统一视为 tiny 对象(tinysize)。分配时,从 sizeclass=2 的 span 中获取一个 16B 的 object 用以分配。如果存储的对象小于 16B,这个空间会被暂时保存起来 (mcache.tiny 字段),下次分配时会复用这个空间,直到这个 object 用完为止。
如图所示: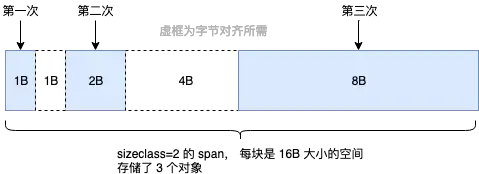
以上图为例,这样的方式空间利用率是 (1+2+8) / 16 * 100% = 68.75%,而如果按照原始的管理方式,利用率是 (1+2+8) / (8 * 3) = 45.83%。
源码中注释描述,说是对 tiny 对象的特殊处理,平均会节省 20% 左右的内存。
如果要存储的数据里有指针,即使 <= 8B 也不会作为 tiny 对象对待,而是正常使用 sizeclass=1 的 span。
大对象
如上面所述,最大的 sizeclass 最大只能存放 32K 的对象。如果一次性申请超过 32K 的内存,系统会直接绕过 mcache 和 mcentral,直接从 mheap 上获取,mheap 中有一个 freelarge 字段管理着超大 span。
总结
内存的释放过程,没什么特别之处。就是分配的返过程,当 mcache 中存在较多空闲 span 时,会归还给 mcentral;而 mcentral 中存在较多空闲 span 时,会归还给 mheap;mheap 再归还给操作系统。这里就不详细介绍了。
总结一下,这种设计之所以快,主要有以下几个优势:
- 内存分配大多时候都是在用户态完成的,不需要频繁进入内核态。
- 每个 P 都有独立的 span cache,多个 CPU 不会并发读写同一块内存,进而减少 CPU L1 cache 的 cacheline 出现 dirty 情况,增大 cpu cache 命中率。
- 内存碎片的问题,Go 是自己在用户态管理的,在 OS 层面看是没有碎片的,使得操作系统层面对碎片的管理压力也会降低。
- mcache 的存在使得内存分配不需要加锁。
当然这不是没有代价的,Go 需要预申请大块内存,这必然会出现一定的浪费,不过好在现在内存比较廉价,不用太在意。
总体上来看,Go 内存管理也是一个金字塔结构: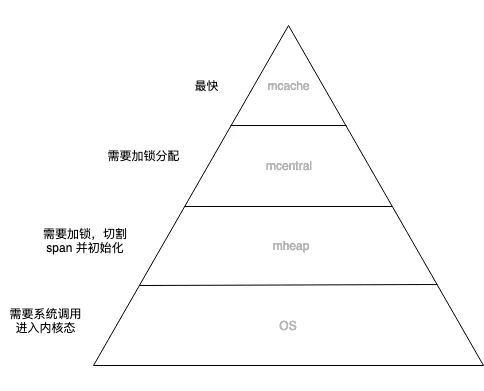
这种设计比较通用,比如现在常见的 web 服务设计,为提升系统性能,一般都会设计成 客户端 cache -> 服务端 cache -> 服务端 db 这几层(当然也可能会加入更多层),也是金字塔结构。
将有限的计算资源布局成金字塔结构,再将数据从热到冷分为几个层级,放置在金字塔结构上。调度器不断做调整,将热数据放在金字塔顶层,冷数据放在金字塔底层。
这种设计利用了计算的局部性特征,认为冷热数据的交替是缓慢的。所以最怕的就是,数据访问出现冷热骤变。在操作系统上我们称这种现象为内存颠簸,系统架构上通常被说成是缓存穿透。其实都是一个意思,就是过度的使用了金字塔低端的资源。
这套内部机制,使得开发高性能服务容易很多,通俗来讲就是坑少了。一般情况下你随便写写性能都不会太差。我遇到过的导致内存分配出现压力的主要有 2 中情况:
- 频繁申请大对象,常见于文本处理,比如写一个海量日志分析的服务,很多日志内容都很长。这种情况建议自己维护一个对象([]byte)池,避免每次都要去 mheap 上分配。
- 滥用指针,指针的存在不仅容易造成内存浪费,对 GC 也会造成额外的压力,所以尽量不要使用指针。
附
内存碎片
内存碎片是系统在内存管理过程中,会不可避免的出现一块块无法被使用的内存空间,这是内存管理的产物。内部碎片
一般都是因为字节对齐,如上面介绍 Tiny 对象分配的部分;为了字节对齐,会导致一部分内存空间直接被放弃掉,不做分配使用。
再比如申请 28B 大小的内存空间,系统会分配 32B 的空间给它,这也导致了其中 4B 空间是被浪费掉的。这就是内部碎片。外部碎片
一般是因为内存的不断分配释放,导致一些释放的小内存块分散在内存各处,无法被用以分配。如图:
上面的 8B 和 16B 的小空间,很难再被利用起来。不过 Go 的内存管理机制不会引起大量外部碎片。源代码调用流程图
针对 Go1.5 源码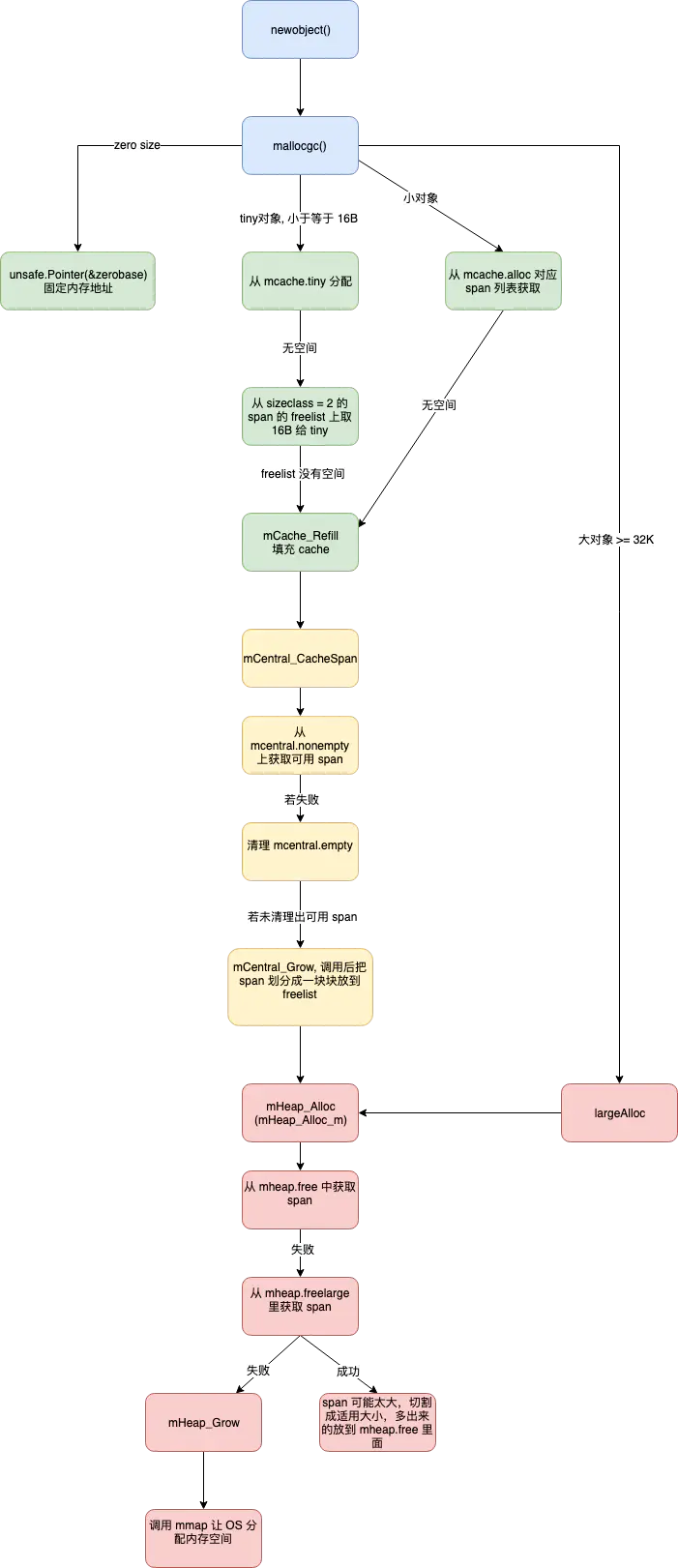
runtime.MemStats 部分注释
type MemStats struct {// heap 分配出去的字节总数,和 HeapAlloc 值相同Alloc uint64// TotalAlloc 是 heap 累计分配出去字节数,每次分配// 都会累加这个值,但是释放时候不会减少TotalAlloc uint64// Sys 是指程序从 OS 那里一共申请了多少内存// 因为除了 heap,程序栈及其他内部结构都使用着从 OS 申请过来的内存Sys uint64// Mallocs heap 累积分配出去的对象数// 活动中的对象总数,即是 Mallocs - FreesMallocs uint64// Frees 值 heap 累积释放掉的对象总数Frees uint64// HeapAlloc 是分配出去的堆对象总和大小,单位字节// object 的声明周期是 待分配 -> 分配使用 -> 待回收 -> 待分配// 只要不是待分配的状态,都会加到 HeapAlloc 中// 它和 HeapInuse 不同,HeapInuse 算的是使用中的 span,// 使用中的 span 里面可能还有很多 object 闲置HeapAlloc uint64// HeapSys 是 heap 从 OS 那里申请来的堆内存大小,单位字节// 指的是虚拟内存的大小,不是物理内存,物理内存大小 Go 语言层面是看不到的。// 等于 HeapIdle + HeapInuseHeapSys uint64// HeapIdle 表示所有 span 中还有多少内存是没使用的// 这些 span 上面没有 object,也就是完全闲置的,可以随时归还给 OS// 也可以用于堆栈分配HeapIdle uint64// HeapInuse 是处在使用中的所有 span 中的总字节数// 只要一个 span 中有至少一个对象,那么就表示它被使用了// HeapInuse - HeapAlloc 就表示已经被切割成固定 sizeclass 的 span 里HeapInuse uint64// HeapReleased 是返回给操作系统的物理内存总数HeapReleased uint64// HeapObjects 是分配出去的对象总数// 如同 HeapAlloc 一样,分配时增加,被清理或被释放时减少HeapObjects uint64// NextGC is the target heap size of the next GC cycle.// NextGC 表示当 HeapAlloc 增长到这个值时,会执行一次 GC// 垃圾回收的目标是保持 HeapAlloc ≤ NextGC,每次 GC 结束// 下次 GC 的目标,是根据当前可达数据和 GOGC 参数计算得来的NextGC uint64// LastGC 是最近一次垃圾回收结束的时间 (the UNIX epoch).LastGC uint64// PauseTotalNs 是自程序启动起, GC 造成 STW 暂停的累积纳秒值// STW 期间,所有的 goroutine 都会被暂停,只有 GC 的 goroutine 可以运行PauseTotalNs uint64// PauseNs 是循环队列,记录着 GC 引起的 STW 总时间//// 一次 GC 循环,可能会出现多次暂停,这里每项记录的是一次 GC 循环里多次暂停的综合。// 最近一次 GC 的数据所在的位置是 PauseNs[NumGC%256]PauseNs [256]uint64// PauseEnd 是一个循环队列,记录着最近 256 次 GC 结束的时间戳,单位是纳秒。//// 它和 PauseNs 的存储方式一样。一次 GC 可能会引发多次暂停,这里只记录一次 GC 最后一次暂停的时间PauseEnd [256]uint64// NumGC 指完成 GC 的次数NumGC uint32// NumForcedGC 是指应用调用了 runtime.GC() 进行强制 GC 的次数NumForcedGC uint32// BySize 统计各个 sizeclass 分配和释放的对象的个数//// BySize[N] 统计的是对象大小 S,满足 BySize[N-1].Size < S ≤ BySize[N].Size 的对象// 这里不记录大于 BySize[60].Size 的对象分配BySize [61]struct {// Size 表示该 sizeclass 的每个对象的空间大小// size class.Size uint32// Mallocs 是该 sizeclass 分配出去的对象的累积总数// Size * Mallocs 就是累积分配出去的字节总数// Mallocs - Frees 就是当前正在使用中的对象总数Mallocs uint64// Frees 是该 sizeclass 累积释放对象总数Frees uint64}}
作者:达菲格
链接:https://www.jianshu.com/p/7405b4e11ee2
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

若有收获,就点个赞吧
0 人点赞
