https://mp.weixin.qq.com/s/rGqM1wMlqQEoJSgyrgZNLg
SliceHeader
SliceHeader 如其名,Slice + Header,看上去很直观,实际上是 Go Slice(切片)的运行时表现。
SliceHeader 的定义如下:
type SliceHeader struct {Data uintptrLen intCap int}
- Data:指向具体的底层数组。
- Len:代表切片的长度。
- Cap:代表切片的容量。
既然知道了切片的运行时表现,那是不是就意味着我们可以自己造一个?
在日常程序中,可以利用标准库 reflect 提供的 SliceHeader 结构体造一个:
func main() {// 初始化底层数组s := [4]string{"脑子", "进", "煎鱼", "了"}s1 := s[0:1]s2 := s[:]// 构造 SliceHeadersh1 := (*reflect.SliceHeader)(unsafe.Pointer(&s1))sh2 := (*reflect.SliceHeader)(unsafe.Pointer(&s2))fmt.Println(sh1.Len, sh1.Cap, sh1.Data)fmt.Println(sh2.Len, sh2.Cap, sh2.Data)}
你认为输出结果是什么,这两个新切片会指向同一个底层数组的内存地址吗?
输出结果:
1 4 8246343309364 4 824634330936
两个切片的 Data 属性所指向的底层数组是一致的,Len 属性的值不一样,sh1 和 sh2 分别是两个切片。
疑问
为什么两个新切片所指向的 Data 是同一个地址的呢?
这其实是 Go 语言本身为了减少内存占用,提高整体的性能才这么设计的。
将切片复制到任意函数的时候,对底层数组大小都不会影响。复制时只会复制切片本身(值传递),不会涉及底层数组。
也就是在函数间传递切片,其只拷贝 24 个字节(指针字段 8 个字节,长度和容量分别需要 8 个字节),效率很高。
坑
这种设计也引出了新的问题,在平时通过 s[i:j] 所生成的新切片,两个切片底层指向的是同一个底层数组。
假设在没有超过容量(cap)的情况下,对第二个切片操作会影响第一个切片。
这是很多 Go 开发常会碰到的一个大 “坑”,不清楚的排查了很久的都不得而终。
StringHeader
除了 SliceHeader 外,Go 语言中还有一个典型代表,那就是字符串(string)的运行时表现。
StringHeader 的定义如下:
type StringHeader struct {Data uintptrLen int}
- Data:存放指针,其指向具体的存储数据的内存区域。
- Len:字符串的长度。
可得知 “Hello” 字符串的底层数据如下:
var data = [...]byte{'h', 'e', 'l', 'l', 'o',}
底层的存储示意图如下:
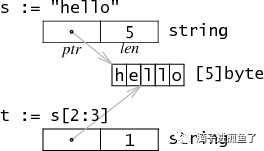
真实演示例子如下:
func main() {s := "脑子进煎鱼了"s1 := "脑子进煎鱼了"s2 := "脑子进煎鱼了"[7:]fmt.Printf("%d \n", (*reflect.StringHeader)(unsafe.Pointer(&s)).Data)fmt.Printf("%d \n", (*reflect.StringHeader)(unsafe.Pointer(&s1)).Data)fmt.Printf("%d \n", (*reflect.StringHeader)(unsafe.Pointer(&s2)).Data)}
你认为输出结果是什么,变量 s 和 s1、s2 会指向同一个底层内存空间吗?
输出结果:
176082271760822717608234
从输出结果来看,变量 s 和 s1 指向同一个内存地址。变量 s2 虽稍有偏差,但本质上也是指向同一块。
因为其是字符串的切片操作,是从第 7 位索引开始,因此正好的 17608234-17608227 = 7。也就是三个变量都是指向同一块内存空间,这是为什么呢?
这是因为在 Go 语言中,字符串都是只读的,为了节省内存,相同字面量的字符串通常对应于同一字符串常量,因此指向同一个底层数组。
0 拷贝转换
为什么会有人关注到 SliceHeader、StringHeader 这类运行时细节呢,一大部分原因是业内会有开发者,希望利用其实现零拷贝的 string 到 bytes 的转换。
常见转换代码如下:
func string2bytes(s string) []byte {stringHeader := (*reflect.StringHeader)(unsafe.Pointer(&s))bh := reflect.SliceHeader{Data: stringHeader.Data,Len: stringHeader.Len,Cap: stringHeader.Len,}return *(*[]byte)(unsafe.Pointer(&bh))}
但这其实是错误的,官方明确表示:
the Data field is not sufficient to guarantee the data it references will not be garbage collected, so programs must keep a separate, correctly typed pointer to the underlying data.
SliceHeader、StringHeader 的 Data 字段是一个 uintptr 类型。由于 Go 语言只有值传递。
因此在上述代码中会出现将 Data 作为值拷贝的情况,这就会导致无法保证它所引用的数据不会被垃圾回收(GC)。
应该使用如下转换方式:
func main() {s := "脑子进煎鱼了"v := string2bytes1(s)fmt.Println(v)}func string2bytes1(s string) []byte {stringHeader := (*reflect.StringHeader)(unsafe.Pointer(&s))var b []bytepbytes := (*reflect.SliceHeader)(unsafe.Pointer(&b))pbytes.Data = stringHeader.Datapbytes.Len = stringHeader.Lenpbytes.Cap = stringHeader.Lenreturn b}
在程序必须保留一个单独的、正确类型的指向底层数据的指针。
在性能方面,若只是期望单纯的转换,对容量(cap)等字段值不敏感,也可以使用以下方式:
func string2bytes2(s string) []byte {return *(*[]byte)(unsafe.Pointer(&s))}
性能对比:
string2bytes1-1000-4 3.746 ns/op 0 allocs/opstring2bytes1-1000-4 3.713 ns/op 0 allocs/opstring2bytes1-1000-4 3.969 ns/op 0 allocs/opstring2bytes2-1000-4 2.445 ns/op 0 allocs/opstring2bytes2-1000-4 2.451 ns/op 0 allocs/opstring2bytes2-1000-4 2.455 ns/op 0 allocs/op
会相当标准的转换性能会稍快一些,这种强转也会导致一个小问题。
代码如下:
func main() {s := "脑子进煎鱼了"v := string2bytes2(s)println(len(v), cap(v))}func string2bytes2(s string) []byte {return *(*[]byte)(unsafe.Pointer(&s))}
输出结果:
18 824633927632
这种强转其会导致 byte 的切片容量非常大,需要特别注意。一般还是推荐使用标准的 SliceHeader、StringHeader 方式就好了,也便于后来的维护者理解。
总结
在这篇文章中,我们介绍了字符串(string)和切片(slice)的两个运行时表现,分别是 StringHeader 和 SliceHeader。
同时了解到其运行时表现后,我们还针对其两者的地址指向,常见坑进行了说明。
最后我们进一步深入,面向 0 拷贝转换的场景进行了介绍和性能分析。
你平时有没有遇到过这块的疑惑或问题呢,欢迎大家一起讨论!

若有收获,就点个赞吧
0 人点赞
