优秀的日志设计的,一个叫 zap 的日志库,它主要特性是对性能和内存分配都做到了极致的优化。
下面先放一下比较唬人的 benchmark ,给大家提供一下看下去的动力:
| Package | Time | Time % to zap | Objects Allocated |
|---|---|---|---|
| ⚡ zap | 862 ns/op | +0% | 5 allocs/op |
| ⚡ zap (sugared) | 1250 ns/op | +45% | 11 allocs/op |
| zerolog | 4021 ns/op | +366% | 76 allocs/op |
| go-kit | 4542 ns/op | +427% | 105 allocs/op |
| apex/log | 26785 ns/op | +3007% | 115 allocs/op |
| logrus | 29501 ns/op | +3322% | 125 allocs/op |
| log15 | 29906 ns/op | +3369% | 122 allocs/op |
1. zap 设计
log 的实例化
在开始使用的时候,我们可以通过官方的例子来了解 zap 内部的组件:
log := zap.NewExample()
NewExample 函数里面展示了要通过 NewCore 来创建一个 Core 结构体,根据名字我们应该也能猜到这个结构体是 zap 的核心。
对于一个日志库来说,最主要是无非是这三类:
- 对于输入的数据需要如何序列化;
- 将输入的数据序列化后存放到哪里,是控制台还是文件,还是别的地方;
- 然后就是日志的级别,是 Debug、Info 亦或是 Error;
同理 zap 也是这样,在使用 NewCore 创建 Core 结构体的时候需要传入的三个参数分别对应的就是:输入数据的编码器 Encoder、日志数据的目的地 WriteSyncer,以及日志级别 LevelEnabler。
除了 NewExample 这个构造方法以外,zap 还提供了 NewProduction、NewDevelopment 来构造日志实例:
log, _ := zap.NewProduction()log, _ := zap.NewDevelopment()
这两个函数会通过构建一个 zap.Config 结构体然后调用 Build 方法来创建调用 NewCore 所需要的参数,然后实例化日志实例。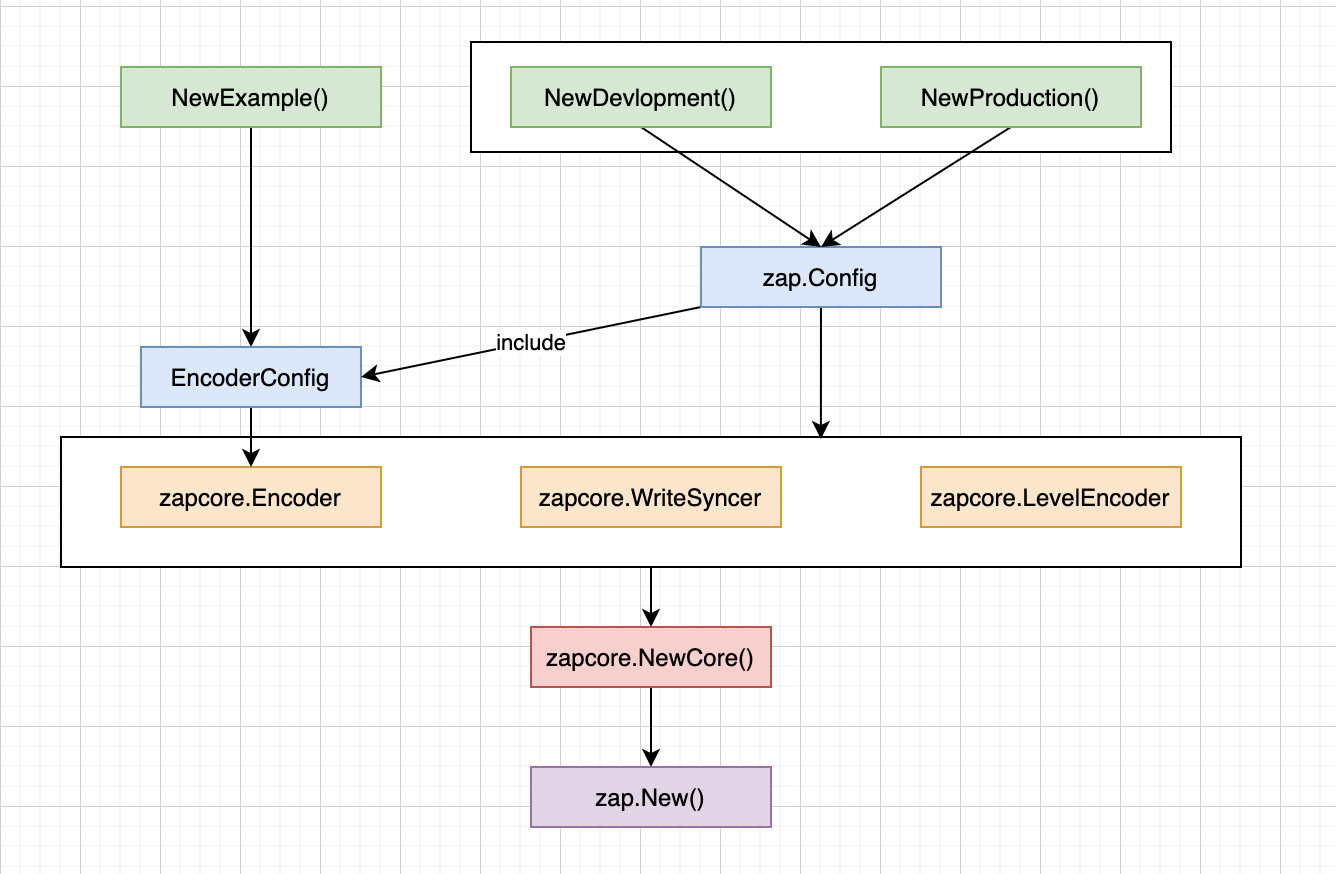
日志数据的输出
在初始化 log 实例之后,可以用 Info、Debug、Error等方法打印日志:
logger := zap.NewExample()logger.Info("222",zap.String("a", "b"),zap.Any("any", "ssss"))logger.Warn("222", zap.String("a", "b"))logger.Error("222", zap.String("a", "b"))
我们再来看一下 zap 打印一条结构化的日志的实现步骤:
- 首先会校验一下日志配置的等级,例如 Error 日志配置等级肯定是不能输出 Debug 日志出来;
- 然后会将日志数据封装成一个 Entry 实例;
- 因为在 zap 中可以传入 multiCore,所以会把多个 Core 添加到 CheckedEntry 实例中;
- 遍历 CheckedEntry 实例中 Cores,
- 根据 Core 中的 Encoder 来序列化日志数据到 Buffer 中;
- 再由 WriteSyncer 将 Buffer 的日志数据进行输出;
2. 接口与框架设计
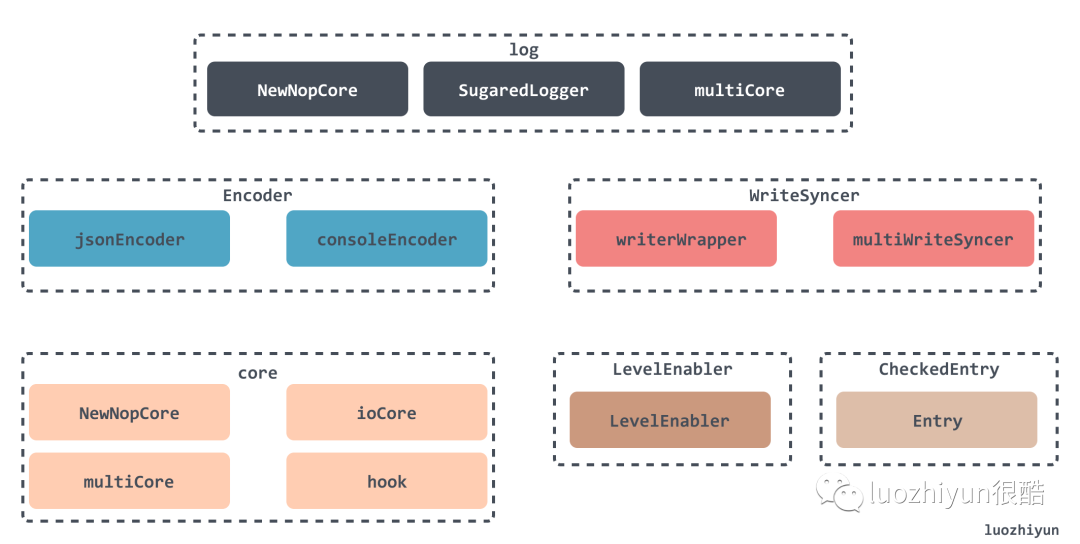
在代码结构设计上,通过简单的接口封装,实现了多种样式的配置组合,从而满足各种需求。在最上层的设计上实现了三种 log 用来实现不同的功能:
- Logger:使用较为繁琐,只能使用结构化输出,但是性能更好;
- SugaredLogger:可以使用 Printf 来输出日志,性能较 Logger 相比差 40% 左右;
- zapgrpc:用做 grpc 的日志输出;在设计上 Logger 可以很方便的转化为 SugaredLogger 和 zapgrpc。这几个 Logger 需要传入一个 Core 接口的实现类才能创建。
- Core 接口:zap 也提供了多种实现的选择:NewNopCore 、ioCore、multiCore 、hook。
最常用的是 ioCore、multiCore ,从名字便可看出来 multiCore 是可以包含多个 ioCore 的一种配置,比方说可以让 Error 日志输出一种日志格式以及设置一个日志输出目的地,让 Info 日志以另一种日志格式输出到别的地方。
在上面也说了,对于 Core 的实现类 ioCore 来说它需要传入三个对象:输入数据的编码器 Encoder、日志数据的目的地 WriteSyncer,以及日志级别 LevelEnabler。
- Encoder 接口:zap 提供了 consoleEncoder、jsonEncoder 的实现,分别提供了 console 格式与 JSON 格式日志输出,这些 Encoder 都有自己的序列化实现,这样可以更快的格式化代码;
- EncoderConfig:上面所说的 Encoder 还可以根据 EncoderConfig 的配置允许使用者灵活的配置日志的输出格式,从日志消息的键名、日志等级名称,到时间格式输出的定义,方法名的定义都可以通过它灵活配置。
- WriteSyncer 接口:zap 提供了 writerWrapper 的单日志输出实现,以及可以将日志输出到多个地方的 multiWriteSyncer 实现;
- Entry :配置说完了,到了日志数据的封装。首先日志数据会封装成一个 Entry,包含了日志名、日志时间、日志等级,以及日志数据等信息,没有 Field 信息,然后经验 Core 的 Check 方法对日志等级校验通过之后会生成一个 CheckedEntry 实例。CheckedEntry 包含了日志数据所有信息,包括上面提到的 Entry、调用栈信息等。
3. 性能游湖
使用对象池
zap 通过 sync.Pool 提供的对象池,复用了大量可以复用的对象,如果对 sync.Pool 不是很了解的同学,可以看这篇文章:《多图详解Go的sync.Pool源码 https://www.luozhiyun.com/archives/416 》。
zap 在实例化 CheckedEntry 、Buffer、Encoder 等对象的时候,会直接从对象池中获取,而不是直接实例化一个新的,这样复用对象可以降低 GC 的压力,减少内存分配。
避免反射
如果我们使用官方的 log 库,像这样输出日志:
log.Printf("%s login, age:%d", "luoluo", 19)
log 调用的 Printf 函数实际上会调用 fmt.Sprintf函数来格式化日志数据,然后进行输出:
func Printf(format string, v ...interface{}) {std.Output(2, fmt.Sprintf(format, v...))}
但是fmt.Sprintf效率实际上是很低的,通过查看fmt.Sprintf源码, 可以看出效率低有两个原因:
fmt.Sprintf接受的类型是 interface{},内部使用了反射;fmt.Sprintf的用途是格式化字符串,需要去解析格式串,比如%s、%d之类的,增加了解析的耗时。
但是在 zap 中,使用的是内建的 Encoder,它会通过内部的 Buffer 以 byte 的形式来拼接日志数据,减少反射所带来性能损失;以及 zap 是使用的结构化的日志,所以没有 %s、 %d之类的标识符需要解析,也是一个性能提升点。
更高效且灵活的序列化器
在 zap 中自己实现了 consoleEncoder、jsonEncoder 两个序列化器,这两个序列化器都可以根据传入的 EncoderConfig 来实现日志格式的灵活配置,这个灵活配置不只是日志输出的 key 的名称,而是通过在 EncoderConfig 中传入函数来调用到用户自定义的 Encoder 实现。
而像 logrus 在序列化 JSON 的时候使用的是标准库的序列化工具,效率也是更低。
4. 自用封装
5. 源码解析

若有收获,就点个赞吧
0 人点赞
