MySQL逻辑架构
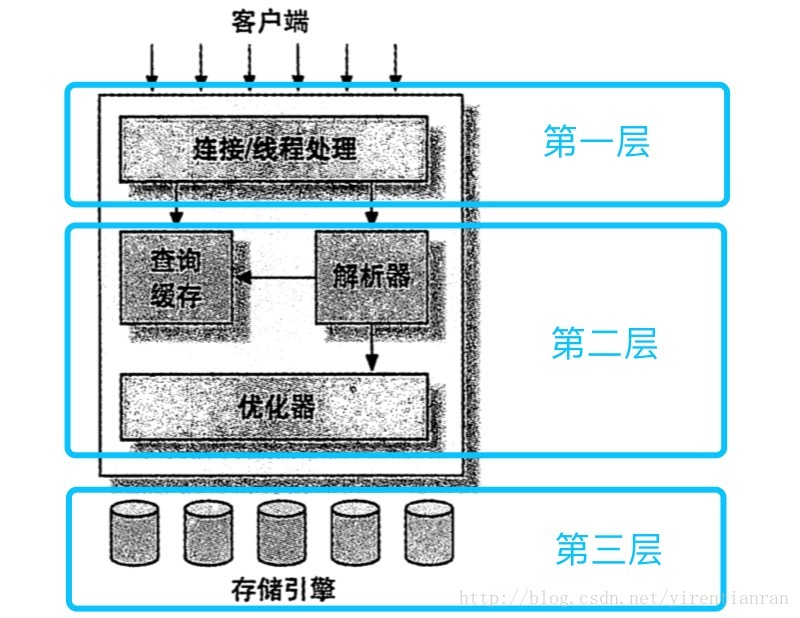
第一层
大多数基于网络的客户端/服务器的工具或者服务都有类似的架构。比如连接处理、授权认证、安全等等。
第二层
大多数MySQL的核心服务功能都在这一层,包括查询解析、分析、优化、缓存以及所有的内置函数(例如,日期、时间、数学和加密函数),所有跨存储引擎的功能都在这一层实现:存储过程、触发器、视图等。
第三层
包含了存储引擎。存储引擎负责MySQL中数据的存储和提取。和GNU/Linux下的各种文件系统一样,每个存储引擎都有它的优势和劣势。服务器通过API与存储引擎进行通信。这些接口屏蔽了不同存储引擎之间的差异,使得这些差异对上层的查询过程透明。存储引擎API包含一些底层函数,用于执行诸如“开始一个事务”或者“根据主键提取一行记录”等操作。但存储引擎不会去解析SQL,不同存储引擎之间也不会相互通信,而只是简单地响应上层服务器的请求。
连接管理
每个客户端连接都会在服务器进程中拥有一个线程,这个连接的查询只会在这个单独的线程中执行,该线程只能轮流在某个CPU核心或者CPU中运行。服务器会负责缓存线程,因此不需要为每一个新建的连接创建或者销毁线程(线程池Thread-Pooling)。
优化与执行
MySQL会解析查询,并创建内部数据结构(解析树),然后对其进行各种优化,包括重写查询、决定表的读取顺序,以及选择合适的索引等。用户可以通过特殊的关键字提示(hint)优化器,影响它的决策过程。也可以请求优化器解释(explain)优化过程的各个因素,使用户可以知道服务器是如何进行优化决策的,并提供一个参考基准,便于用户重构查询和schema、修改相关配置,使应用尽可能高效运行。
优化器并不关心表使用的是什么存储引擎,但存储引擎对于优化查询是有影响的。优化器会请求存储引擎提供容量或某个具体操作的开销信息,以及表数据的统计信息等。例如,某些存储引擎的某种索引,可能对一些特定的查询有优化。
对于SELECT语句,在解析查询之前,服务器会先检查查询缓存(Query Cache),如果能够在其中找到对应的查询,服务器就不必再执行查询解析、优化和执行的整个过程,而是直接返回查询缓存中的结果集。
总结
MySQL拥有分层的架构。上层的服务器层是服务和查询执行引擎,下层则是存储引擎。虽然有很多不同作用的插件API,但存储引擎API还是最重要的。如果能理解MySQL在存储引擎和服务层之间处理查询时如何通过API来回交互,就能抓住MySQL的核心基础架构的精髓。
MySQL最初基于ISAM构建(后来被MyISAM取代),其后陆续添加了更多的存储引擎和事务支持。MySQL有一些怪异的行为是由于历史遗留导致的。例如,在执行ALTER TABLE时,MySQL提交事务的方式是由于存储引擎的架构直接导致的,并且数据字典也保存在.frm文件中(这并不是说InnoDB会导致ALTER变成非事务型的。对于InnoDB来说,所有的操作都是事务)。
当然,存储引擎API的架构也有一些缺点。有时候选择多并非好事,而在MySQL5.0和MySQL5.1中有太多的存储引擎可以选择。 InnoDB对于95%以上的用户来说都是最佳的选择,所以其他的存储引擎可能只是让事情变更复杂难搞,当然也不可否认某些情况下某些存储引擎能更好的满足需求。
Oracle一开始收购了InnoDB,之后又收购了MySQL,在同一个屋檐下对于两者都是有利的。InnoDB和MySQL服务器之间可以更快的协同发展。MySQL依然基于GPL协议开放全部源代码,社区和客户都可以获得坚固而稳定的数据库,MySQL正在变得越来越可扩展和有用。
作者:一任天然
来源:CSDN
原文:https://blog.csdn.net/yirentianran/article/details/79220166
版权声明:本文为博主原创文章,转载请附上博文链接!

若有收获,就点个赞吧
0 人点赞
