很多人对多列索引的理解都不够。一个常见的错误就是,为每个列创建独立的索引。
看一个例子,从SHOW CREATE TABLE中很容易看到这种情况:
CREATE TABLE t(c1 INT,c2 INT,c3 INT,KEY(c1),KEY(c2),KEY(c3));
这样一来最好的情况下也只能是“一星”索引,其性能比起真正的最优的索引可能差几个数量级。有时如果无法设计一个“三星”索引,那么不如忽略掉WHERE子句,集中精力优化索引列的顺序,或者创建一个全覆盖的索引。
在多个列上建立独立的单列索引大部分情况下并不能提高MySQL的查询性能。MySQL5.0和更新版本引入了一种叫“索引合并”(index merge)的策略,一定程度上可以使用表上的多个单列索引来定位指定的行。更早版本的MySQL只能使用其中某一个单列索引,然而在这种情况下没有哪一个独立的单列索引是非常有效的。例如,表file_actor在字段film_id和actor_id上各有一个单列索引。但对于下面这个查询WHERE条件,这两个单列索引都不是好的选择:
SELECT film_id,actor_id FROM sakila.film_actor
WHERE actor_id OR film_id = 1;
在老的MySQL版本中,MySQL对这个查询会使用全表扫描。除非改写成如下的两个查询UNION的方式:
SELECT film_id,actor_id FROM sakila.film_actor
WHERE actor_id
UNION ALL
SELECT film_id,actor_id FROM sakila.film_actor
WHERE film_id = 1 AND actor_id <> 1;
但在MySQL5.0和更新的版本中,查询能够同时使用这两个单列索引进行扫描,并将结果进行合并。这种算法有三个变种:OR条件的联合(union),AND条件的相交(intersection),组合前两种情况的联合及相交。下面的查询就是使用了两个索引扫描的联合,通过EXPLAIN中的Extra列可以看到这点: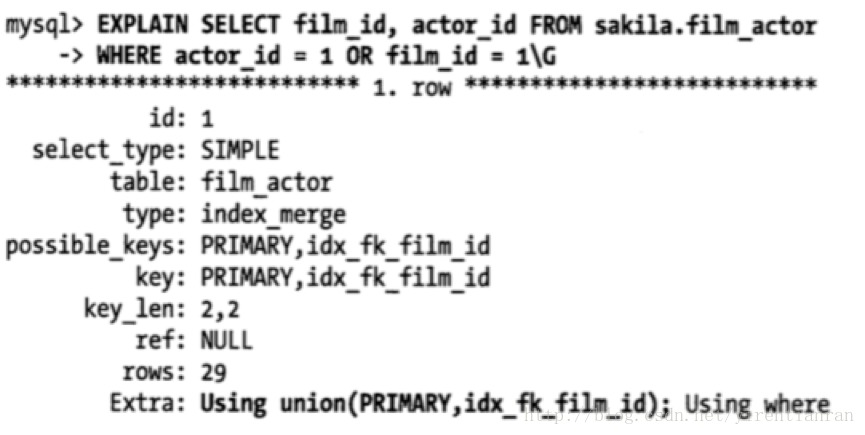
MySQL会使用这类技术优化复杂查询,所以在某些语句的Extra列中还可以看到嵌套操作。
索引合并策略有时候是一种优化的结果,但实际上更多时候说明了表上的索引建得很糟糕:
- 当出现服务器对多个索引做相交操作(通常有多个AND条件),通常意味着需要一个包含所有相关列的多列索引,而不是多个独立的单列索引。
- 当服务器需要对多个索引做联合操作时(通常有多个OR条件),通常需要耗费大量CPU和内存资源在算法的缓存、排列和合并操作上。特别是当其中有些索引的选择性不高,需要合并扫描返回的大量数据的时候。
- 更重要的是,优化器不会把这些计算到“查询成本”(cost)中,优化器只关心随机页面读取。这会使得查询的成本被“低估”,导致该计划还不如直接走全表扫描。这样做不但会消耗更多的CPU和内存资源,还可能会影响查询的并发性,但如果是单独运行这样的查询则往往会忽略对并发性的影响。通常来说,还不如像在MySQL4.1或者更早的时代一样,将查询改写成UNION的方式往往更好。
如果在EXPLAIN中看到有索引合并,应该好好检查一下查询和表的结构,看是不是已经是最优的。也可以通过参数optimizer_switch来关闭索引合并功能。也可以使用IGNORE INDEX提示让优化器忽略掉某些索引。
作者:一任天然
来源:CSDN
原文:https://blog.csdn.net/yirentianran/article/details/79377303
版权声明:本文为博主原创文章,转载请附上博文链接!

若有收获,就点个赞吧
0 人点赞
