有时候需要索引很长的字符列,这会让索引变得大且慢。一个策略是前面提到过的模拟哈希索引。但有时候这样做还不够,还可以做些什么呢?
通常可以索引开始的部分字符,这样可以大大节约索引空间,从而提高索引效率。但这样也会降低索引的选择性。索引的选择性是指,不重复的索引值(也称为基数,cardinality)和数据库的记录总数(#T)的比值,范围从1/#T到1之间。索引的选择性越高则查询效率越高,因为选择性高的索引可以让MySQL在查找时过滤掉更多的行。唯一索引的选择性是1,这是最好的索引选择性,性能也是最好的。
一般情况下某个列前缀选择性也是足够高的,足以满足查询性能。对于BLOB、TEXT或者很长的VARCHAR类型的列,必须使用前缀索引,因为MySQL不允许索引这些列的完整长度。
诀窍在于要选择足够长的前缀以保证较高的选择性,同时有不能太长(以便节约空间)。前缀应该足够长,以使得前缀索引的选择性接近于索引整个列。换句话说,前缀的“基数”应该接近于完整列的“基数”。
为了决定前缀的合适长度,需要找到最常见的值的列表,然后和最常见的前缀列表进行比较。例如:
首先,我们找到最常见的城市列表:
注意到,上面每个值都出现了45~65次。现在查找到最频繁出现的城市前缀,先从3个前缀字母开始:
每个前缀都比原来的城市出现的次数更多,因此唯一前缀比唯一城市要少得多。然后我们增加前缀长度,直到这个前缀的选择性接近完整列的选择性。经过实验后发现前缀长度为7时比较合适:
计算合适的前缀长度的另外一个办法就是计算完整列的选择性,并使前缀的选择性接近于完整列的选择性。下面显示如何计算完整列的选择性:
通常来说(尽管也有例外情况),这个例子中如果前缀的选择性能够接近0.031,基本上就可用了。可以在一个查询中针对不同前缀长度进行计算,这对于大表非常有用。下面给出了如何在同一个查询中计算不同前缀长度的选择性: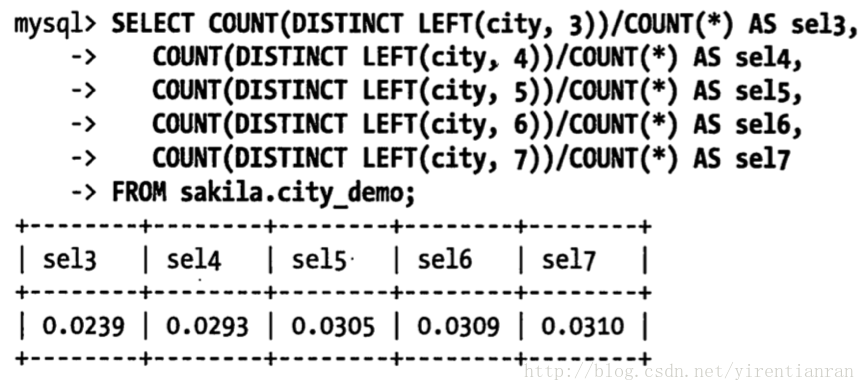
查询显示当前缀长度到达7的时候,再增加前缀长度,选择性提升的幅度已经很小了。只看平均选择性是不够的,也有例外的情况,需要考虑最坏情况下的选择性。平均选择性让你认为前缀长度为4或者5的索引已经足够了,但如果数据分布很不均匀,可能就会有陷阱。如果观察前缀为4的最常出现城市的次数,可以看到明显不均匀:
如果前缀是4个字节,在最常出现的前缀的出现次数比最常出现的城市的出现次数要大得多。即这些值的选择性比平均选择性要低。如果有比这个随机生成的示例更真实的数据,就更有可能看到这种现象。例如在真实的城市名上建一个长度为4个前缀索引,对于以“San”和“New”开头的城市的选择性就会非常糟糕,因为很多城市都以这两个词开头。
在上面的示例中,已经找到了合适的前缀长度,下面演示一下如何创建前缀索引:
前缀索引是一种能使索引更小、更快的有效办法,但另一方面也有其缺点:MySQL无法使用前缀做ORDER BY和GROUP BY,也无法使用前缀索引做覆盖扫描。
例如使用vBulletin或者其他基于MySQL的应用在存储网站的会话(SEESION)时,需要在一个很长的十六进制字符串上创建索引。此时如果采用长度为8的前缀索引通常能显著地提升性能,并且这种方法对上层应用完全透明。
作者:一任天然
来源:CSDN
原文:https://blog.csdn.net/yirentianran/article/details/79375053
版权声明:本文为博主原创文章,转载请附上博文链接!

若有收获,就点个赞吧
0 人点赞
