我们遇到的最容易引起困惑的问题就是索引列的顺序。正确的顺序依赖于使用该索引的查询,并且同时需要考虑如何更好地满足排序和分组的需要(顺便说明,本节内容适用于B-Tree索引;哈希或者其他类型的索引并不会像B-Tree索引一样按顺序存储数据)。
在一个多列B-Tree索引中,索引列的顺序意味着索引首先按照最左列进行排序,其次是第二列,等等。所以,索引可以按照升序或者降序进行扫描,以满足精确符合列顺序的ORDER BY、GROUP BY和DISTINCT等子句的查询需求。
所以多列索引的顺序至关重要。在“三星索引”系统中,列顺序也决定了一个索引是否能够成为一个真正的“三星索引”。
对于如何选择索引的列顺序有一个经验法则:将选择性最高的列放到索引最前列。这个建议有用吗?在某些场景可能有帮助,但通常不如避免随机IO和排序那么重要,考虑问题需要更全面(场景不同则选择不同,没有一个放之四海皆准的法则。这里只是说明,这个经验法则可能没有你想象的重要)。
当不需要考虑排序和分组时,将选择性最高的列放在前面通常是很好的。这时候索引的作用只是用于优化WHERE条件的查找。在这种情况下,这样设计的索引确实能够最快地过滤出需要的行,对于WHERE子句中只使用了索引部分前缀列的查询来说选择性也更高。然而,性能不只是依赖于所有索引列的选择性(整体基数),也和查询条件的具体值有关,也就是和值的分布有关。这和选择前缀的长度需要考虑的地方一样。可能需要根据那些运行频率最高的查询来调整索引列的顺序,让这种情况下索引的选择性最高。
以下面的查询为例:
SELECT * FROM payment WHERE staff_id = 2AND customer_id = 584;
是应该创建一个(staff_id,customer_id)索引还是应该颠倒一下顺序?可以跑一些查询来确定在这个表中值的分布情况,并确定哪个列的选择性更高。先用下面的查询预测一下,看看各个WHERE条件的分支对应的数据基数有多大:
根据前面的经验法则,应该将索引列custom_id放到前面,因为对应条件值的customer_id数量更小。我们再来看看对于这个customer_id的条件值,对应的staff_id列的选择性如何:
这样做的一个地方需要注意,查询的结果非常依赖于选定的具体指。如果按上述办法优化,可能对其他一些条件值的查询不公平,服务器的整体性能可能变得更糟,或者其他某些查询的运行变得不如预期。
如果是从诸如pt-query-digest这样的工具的报告中提取“最差”查询,那么再按上述办法选定的索引顺序往往是非常高效的。如果没有类似的具体查询来运行,那么最好还是按经验法则来做,因为经验法则考虑的是全局基数和选择性,而不是某个具体查询: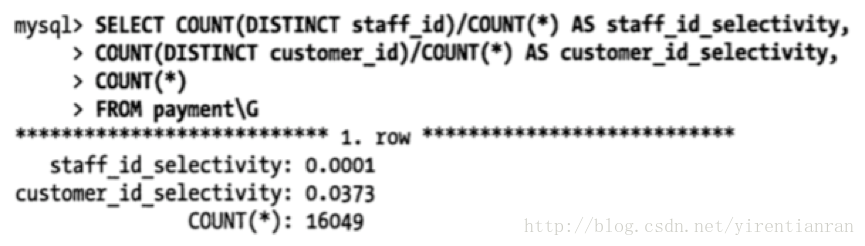
customer_id的选择性更高,所以答案是将其作为索引列的第一列:
ALTER TABLE payment ADD KEY(customer_id,staff_id);
当使用前缀索引的时候,在某些条件值的基数比正常值高的时候,问题就来了。例如,在某些应用程序中,对于没有登录的用户,都将其用户名记录为“guest”,在记录用户行为的会话(session)表和其他记录用户活动的表中“guest”就成为一个特殊用户ID。一旦查询涉及这个用户,那么和对于正常用户的查询就大不同了,因为通常有很多会话都是没有登录的。系统账号也会导致类似的问题。一个应用通常都有一个特殊的管理员账号,和普通账号不同,它并不是一个具体的用户,系统中所有的其他用户都是这个用户的好友,所有系统往往通过它向网站的所有用户发送状态通知和其他消息。这个账号的巨大的好友列表很容易导致网站出现服务器性能问题。
这实际上是一个非常典型的问题。任何异常用户,不仅仅是那些用于管理应用的设计糟糕的账号会有同样的问题;那些有用大量好友、图片、状态、收藏的用户,也会有前面提到的系统账号同样的问题。
在一个用户分享购买商品和购买经验的论坛上,这个特殊表上的查询运行的非常慢:
这个查询看似没有建立合适的索引。EXPLAIN的结果如下:
MySQL为这个查询选择了索引(groupId,userId),如果不考虑列的基数,这看起来是一个非常合理的选择。但如果考虑一下user ID和group ID条件匹配的行数,可能就会有不同的想法了:
从上面的结果来看符合组(groupId)条件几乎满足表中的所有行,符合用户(userId)条件的有130万条记录——也就是说索引基本上没什么用。因为这些数据是从其他应用中迁移过来的,迁移的时候把所有的消息都赋予了管理员组的用户。这个案例的解决办法是修改应用程序代码,区分这类特殊用户和组,禁止针对这类用户和组执行这个查询。从这个小案例可以看到经验法则和推论在多数情况是有用的,但要注意不要假设平均情况下的性能也能代表特殊情况下的性能,特殊情况可能会摧毁整个应用的性能。
最后,尽管关于选择性和基数的经验法则值得去研究和分析,但一定要记住别忘记WHERE子句中的排序、分组和范围条件等其他因素,这些因素可能对查询的性能造成非常大的影响。
作者:一任天然
来源:CSDN
原文:https://blog.csdn.net/yirentianran/article/details/79380068
版权声明:本文为博主原创文章,转载请附上博文链接!

若有收获,就点个赞吧
0 人点赞
