-
- 为什么大多数编程语言中,数组要从 0 开始编号,而不是从 1 开始呢?
从数组存储的内存模型上来看,“下标”最确切的定义应该是“偏移(offset)”。前面也讲到,如果用 a 来表示数组的首地址,a[0]就是偏移为 0 的位置,也就是首地址,a[k]就表示偏移 k 个 type_size 的位置,所以计算 a[k]的内存地址只需要用这个公式:a[k]_address = base_address + k type_size但是,如果数组从 1 开始计数,那我们计算数组元素 a[k]的内存地址就会变为:a[k]_address = base_address + (k-1)type_size对比两个公式,我们不难发现,从 1 开始编号,每次随机访问数组元素都多了一次减法运算,对于 CPU 来说,就是多了一次减法指令。
- 散列表
散裂冲突?
- 开放寻执法
- 线性寻找
- 二次寻找
- 二次散裂
- 链表法 - bucket
- 分治算法是一种处理问题的思想,递归是一种编程技巧。
实际上,分治算法一般都比较适合用递归来实现。分治算法的递归实现中,每一层递归都会涉及这样三个操作:
- 分解:将原问题分解成一系列子问题
- 解决:递归地求解各个子问题,若子问题足够小,则直接求解
- 合并:将子问题的结果合并成原问题。
Math & Bit
不用加号的加法 & ^ <<
class Solution:def add(self, a: int, b: int) -> int:while b:a, b = a& 0xFFFFFFFF ^ b& 0xFFFFFFFF, (a&b)<<1 & 0xFFFFFFFFreturn a if a < 0x80000000 else ~(a^0xFFFFFFFF)
埃拉托斯特尼筛法求素数
import mathdef prime(L):arr = list(range(2,L))for i in range(math.ceil(math.sqrt(len(arr)))+1):if arr[i] == 0:continuefor j in range(i+1, len(arr)):if arr[j]!= 0 and arr[j]%arr[i]==0:arr[j]=0return [i for i in arr if i!=0]
一个一个筛选,能整除的肯定不是素数
- 当n是2的次幂, 那么 x%n == x & (n-1) 用位运算代替求模运算,可以提升效率
- 异或运算可以用来找出唯一不重复的数字
- & 1 可以用来做奇偶判断
- pow(x,n)可以把n转换为二进制,每次& 1来连乘
剑指 Offer 56 - I. 数组中数字出现的次数
https://leetcode-cn.com/problems/shu-zu-zhong-shu-zi-chu-xian-de-ci-shu-lcof/class Solution:def singleNumbers(self, nums: List[int]) -> List[int]:res = 0for num in nums:res ^= nummask = 1while res & mask == 0:mask <<= 1a, b = 0, 0for num in nums:if num & mask:a ^= numelse:b ^= numreturn [a,b]
169. 多数元素
https://leetcode-cn.com/problems/majority-element/class Solution {public:int majorityElement(vector<int>& nums) {int res = 0;for(int i = 0 ; i < 32; ++i){int ones = 0;for(int n : nums)ones += (n >> i) & 1; //位运算法统计每个位置上1出现的次数,每次出现则ones+1res += (ones > nums.size()/2) << i; //如果1出现次数大于1/2数组的长度,1即为这个位置的目标数字}return res;}};
Sort
冒泡排序
每次都从数组最开始循环, 遇到前一个大于后一个的, 就把大的挪到后面, 所以一次循环之后,最大的元素会被放到最后def bubbleSort(arr):for i in range(len(arr)):for j in range(len(arr)-1-i):if arr[j] > arr[j+1]:arr[j], arr[j+1] = arr[j+1], arr[j]return arr
选择排序
每次循环找到最小的那个元素的index, 然后把它放到最前面def select(arr):for i in range(len(arr)):min_idx = ifor j in range(i+1, len(arr)):if arr[j] < arr[min_idx]:min_idx = jif min_idx != i:arr[min_idx], arr[i] = arr[i], arr[min_idx]return arr
插入排序
每次循环从当前元素往前找, 把它插入到合适的位置def insert_sort(arr):for i in range(len(arr)):j = iwhile j > 0:if arr[j] < arr[j-1]:arr[j], arr[j-1] = arr[j-1], arr[j]j -= 1return arr
快速排序
分两部分
递归函数是quick sort自身, 提供一个array, 提供一个low一个high, 把这个范围里的做个divide, 然后一边小于pivot, 一边大于pivot, 这个事情具体由partition函数来做, shuffle之后, 取第一个元素为pivot (也可以是最后一个,也可以是随机找的一个), 循环, 双指针: 如果小于pivot, 不操作, 左指针++, 如果大于pivot, 左右指针指向的元素调换, 右指针— ```python def partition(arr, low, high): pivot = arr[low] i = low + 1 j = high while i <= j: if arr[i] < pivot: i += 1 else: arr[i], arr[j] = arr[j], arr[i] j -= 1 arr[low], arr[j] = arr[j], arr[low] return j
def quick_sort(arr, low, high): if low < high: pivot = partition(arr, low, high) quick_sort(arr, low, pivot-1) quick_sort(arr, pivot+1, high) return arr
<a name="XHPP9"></a>### 堆排序- 堆排序是利用 **堆**进行排序的- **堆**是一种完全二叉树- **堆**有两种类型: **大根堆** **小根堆**- 两种类型的概念如下:<br />大根堆:每个结点的值都大于或等于左右孩子结点<br />小根堆:每个结点的值都小于或等于左右孩子结点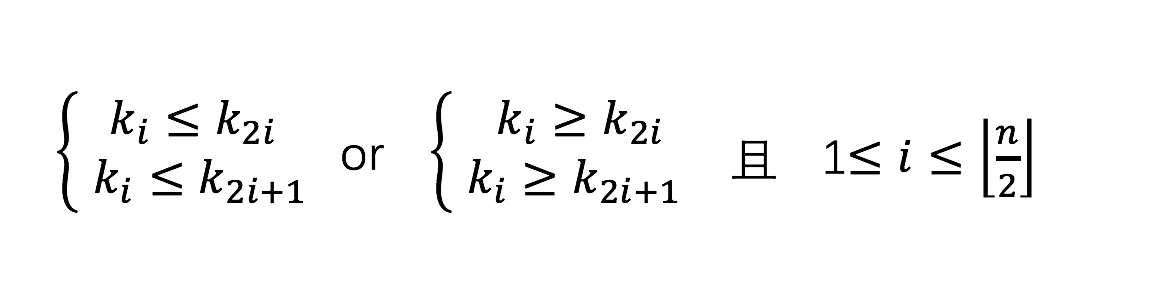<br />Find the maximum element and place the maximum element at the end.<br />a binary heap is a complete binary tree.1. build a max heap from the input data1. at this point, the largest item is stored at the root of the heap, replace it with the last item of the heap followed by reducing the size of heap by 1. finally heapify the root of the tree.1. repeat step 2 while size of heap is greater than 1.```pythonimport timedef heapify(arr,n, i):largest = il = i*2 + 1r = i*2 + 2if l < n and arr[largest] < arr[l]:largest = lif r < n and arr[largest] < arr[r]:largest = rif largest!=i:arr[largest], arr[i] = arr[i], arr[largest]heapify(arr,n,largest)def heapSort(arr):n = len(arr)for i in range(n//2-1, -1, -1):heapify(arr, n, i)for i in range(n-1, 0,-1):arr[i], arr[0] = arr[0], arr[i]# heapify until i, because the rest have been sorted and removed from the heapheapify(arr,i,0)return arr
Sliding Window
2021-02是滑动窗口月, 开一篇单独的题解来记录二月份的滑动窗口
480. 滑动窗口中位数
https://leetcode-cn.com/problems/sliding-window-median/
相比滑动窗口的最大值, 维护一个当前窗口的最大值, 这道题就变成了要维护一个有序数组(因为要找中位数), 然后用二分法进行查找.
import bisectclass Solution:def medianSlidingWindow(self, nums: List[int], k: int) -> List[float]:res = []window = []left = 0for right in range(len(nums)):bisect.insort(window, nums[right])if right >= k-1:if k & 1:res.append(window[k//2])else:res.append((window[k//2]+window[(k-1)//2])/2.0)window.pop(bisect.bisect_left(window, nums[left]))left += 1return res
上面的题解主要是关于bisect的使用, 但是由于window.pop()的操作时间复杂度依然为O(k)
Design
146. LRU 缓存机制
https://leetcode-cn.com/problems/lru-cache/
关键点在于每次的挪动,删除,增加的操作要记得同时更新哈希表和链表
LRU:
- key-value的保存,O(1) search, then HashMap - > key-ListNode(value)
- Double LinkedList, first in will be put in the front
- add a node at the end ( the latest used one and new coming)
- delete a node from the front ( full capacity)
- move a random node at the end ( refresh a node)
What do we need?
- class LinkedList - > key, value, next, prev
- a HashMap -> key - ListNode(key,value)
- def get - > if not in HashMap, return -1, if in HashMap, (1) refresh the corresponding key’s value in the HashMap (2) move the key to the tail of LinkedList, at the end return the value
- def put ->
if in HashMap -> move it to the tail of LinkedList,
if not in HashMap -> if capacity full, remove head.next from HashMap and remove head.next from LinkedList, then add the new one to HashMap, add the new one to the tail of LinkedList ```python class ListNode: def init(self,key=None, val=None):self.key=keyself.val=valself.next = Noneself.prev = None
class LRUCache:
def __init__(self, capacity: int):self.HashMap = {}self.capacity = capacityself.head = ListNode()self.tail = ListNode()self.head.next, self.tail.prev = self.tail, self.headdef move_to_tail(self, key):# 从自己所在位置拿出来node = self.HashMap[key]node.prev.next = node.nextnode.next.prev = node.prev# 放到tail之前self.add_to_tail(node)def remove_from_head(self):# delete from HashMap# 链表里存了key就为了这个时候反向定位,从hashmap弹出self.HashMap.pop(self.head.next.key)# delete from the LinkListself.head.next = self.head.next.nextself.head.next.prev = self.headdef add_to_tail(self, node):# node 的前后node.prev = self.tail.prevnode.next = self.tail# assign node to its prev's next and next's prevself.tail.prev.next = nodeself.tail.prev = nodedef get(self, key: int) -> int:if key not in self.HashMap:return -1else:self.move_to_tail(key)return self.HashMap[key].valdef put(self, key: int, value: int) -> None:if key in self.HashMap:self.HashMap[key].val = value # update HashMapself.move_to_tail(key) # update the LinkedListelse:if len(self.HashMap)==self.capacity: # check capacityself.remove_from_head()newNode = ListNode(key,value)self.HashMap[key]=newNodeself.add_to_tail(newNode)
<a name="5CKDu"></a>#### [716. 最大栈](https://leetcode-cn.com/problems/max-stack/)[https://leetcode-cn.com/problems/max-stack/](https://leetcode-cn.com/problems/max-stack/)<br />两个栈解决,time complexity O(n)<br />每次两个栈都压入,区别是max_stack是用来存放当前stack里最大value的,如果push的value大于max_stack[-1],那么压入value, 如果小于,那么把max_stack[-1]再压入一次```pythonclass MaxStack:def __init__(self):"""initialize your data structure here."""self.stack = []self.max_stack = []def push(self, x: int) -> None:self.stack.append(x)if not self.max_stack:self.max_stack.append(x)else:self.max_stack.append(max(self.max_stack[-1],x))def pop(self) -> int:if self.stack:self.max_stack.pop()return self.stack.pop()else:return -1def top(self) -> int:return self.stack[-1]def peekMax(self) -> int:return self.max_stack[-1]def popMax(self) -> int:tmp = []while self.stack and self.stack[-1]!=self.max_stack[-1]:tmp.append(self.stack.pop())self.max_stack.pop()res = self.stack.pop()self.max_stack.pop()while tmp:self.push(tmp.pop())return res
难点在于popMax(), O(logN)需要用到二叉搜索树+双向链表
实现哈希表
https://leetcode-cn.com/problems/design-hashmap/
class LinkedNode:def __init__(self, key=0,val=0, next=None):self.key = keyself.val = valself.next = nextclass HashMap:def __init__(self):self.capacity = 1<<3self.loader_factor = 0.75self.arr = [None]*self.capacityself.count = 0def reset(self):self.capacity = self.capacity << 1self.tmp_arr = self.arr[:]self.arr = [None]*self.capacityfor node in self.tmp_arr:while node:self.put(node.key, node.value)node = node.nextdef get(self,key):hash_key = self.get_hash_key(key)if self.arr[hash_key]:head = self.arr[hash_key]while head:if head.key == key:return head.valhead = head.next# if not findreturndef get_hash_key(self, key):return key & (self.capacity -1)def put(self,key,value):if self.count > self.capacity*self.loader_factor:self.reset()hash_key = self.get_hash_key(key)if not self.arr[hash_key]:self.arr[hash_key] = LinkedNode(key=key,val=value)self.count+=1else:head = self.arr[hash_key]while head:if head.key == key:head.val = valuebreakif not head.next:head.next = LinkedNode(key=key,val=value)self.count+=1head = head.next
Stack
面试题 03.02. 栈的最小值
https://leetcode-cn.com/problems/min-stack-lcci/
维护一个最小值stack,每个元素对应当前位置下往前所有元素的最小值
class MinStack:def __init__(self):"""initialize your data structure here."""self.stack = []self.sorted_stack = []self.min_value = float('inf')def push(self, x: int) -> None:self.stack.append(x)if x < self.min_value:self.sorted_stack.append(x)self.min_value=xelse:self.sorted_stack.append(self.min_value)def pop(self) -> None:if not self.stack:return Noneres = self.stack.pop()self.sorted_stack.pop()if res == self.min_value:self.min_value = float('inf') if not self.sorted_stack else self.sorted_stack[-1]return resdef top(self) -> int:if self.stack:return self.stack[-1]else:return Nonedef getMin(self) -> int:if self.sorted_stack:return self.sorted_stack[-1]else:return None
剑指 Offer 59 - II. 队列的最大值
https://leetcode-cn.com/problems/dui-lie-de-zui-da-zhi-lcof/
from queue import Queue,dequeclass MaxQueue:def __init__(self):self.queue = Queue()self.deque = deque()def max_value(self) -> int:if self.deque:return self.deque[0]else:return -1def push_back(self, value: int) -> None:while self.deque and self.deque[-1]<value:self.deque.pop()self.deque.append(value)self.queue.put(value)def pop_front(self) -> int:if not self.deque:return -1res = self.queue.get()if res == self.deque[0]:self.deque.popleft()return res
剑指 Offer 31. 栈的压入、弹出序列
https://leetcode-cn.com/problems/zhan-de-ya-ru-dan-chu-xu-lie-lcof/
场景还原:
新建一个临时stack,按照压栈顺序压入,每次压入后判断临时stack的最后一位和出栈序列的第一位是否相等,相等的话说明该弹出了,就持续弹出符合条件的元素,等循环结束后,如果临时stack和弹出序列都是空,那么就说明符合
class Solution:def validateStackSequences(self, pushed: List[int], popped: List[int]) -> bool:if not pushed and not popped:return Truestack = list()while pushed:num = pushed.pop(0)stack.append(num)while stack and popped:if stack[-1] == popped[0]:popped.pop(0)stack.pop()else:breakreturn not popped and not stack
331. 验证二叉树的前序序列化
https://leetcode-cn.com/problems/verify-preorder-serialization-of-a-binary-tree/
栈的消消乐
class Solution:def isValidSerialization(self, preorder: str) -> bool:stack = []for node in preorder.split(","):stack.append(node)while len(stack) > 2 and stack[-1]=='#' and stack[-2]=='#' and stack[-3].isdigit():for i in range(3):stack.pop()stack.append('#')return True if stack ==['#'] else False
UnionFind
放两个模板
模版一:
初始化状态下,每个节点都不在子集合里,根节点的parent是None
class UnionFind:def __init__(self):"""记录每个节点的父节点"""self.father = {}def find(self,x):"""查找根节点路径压缩"""root = xwhile self.father[root] != None:root = self.father[root]# 路径压缩while x != root:original_father = self.father[x]self.father[x] = rootx = original_fatherreturn rootdef merge(self,x,y,val):"""合并两个节点"""root_x,root_y = self.find(x),self.find(y)if root_x != root_y:self.father[root_x] = root_ydef is_connected(self,x,y):"""判断两节点是否相连"""return self.find(x) == self.find(y)def add(self,x):"""添加新节点"""if x not in self.father:self.father[x] = None
模板二:
初始状态下所有节点的parent是他自己,所有没有了add函数,而且在find root函数里判断条件不是parent为None,而是parent为自身
1202. 交换字符串中的元素
class UnionFind:def __init__(self,n):self.parent = [i for i in range(n)]def find(self, x):root = xwhile self.parent[root]!=root:root = self.parent[root]while x!=root:self.parent[x],x, = root ,self.parent[x]return rootdef union(self,x,y):root_x, root_y = self.find(x), self.find(y)if root_x!=root_y:self.parent[root_x]=root_yfrom collections import defaultdictclass Solution:def smallestStringWithSwaps(self, s: str, pairs: List[List[int]]) -> str:uf = UnionFind(len(s))for i,j in pairs:uf.union(i,j)children = defaultdict(lambda: set())for i,j in pairs:root = children[uf.find(i)]root.add(i)root.add(j)arr = list(s)for v in children.values():for i,j in zip(sorted(v),sorted([arr[i] for i in v])):arr[i]=jreturn "".join(arr)
200. 岛屿数量
https://leetcode-cn.com/problems/number-of-islands/
岛屿的数量还是用DFS写起来好理解一些
1319. 连通网络的操作次数
https://leetcode-cn.com/problems/number-of-operations-to-make-network-connected/
- n台计算机至少需要n-1条线才能全部联通
- 用并查集计算有多少个cluster,那么至少需要cluster-1条多余的连接线才可以做到全连通
如何计算多余的线? 其实并不需要计算,因为如果两个cluster之间没有足够的线把他们链接起来,那么就已经不满足第一个条件了
class UnionFind:def __init__(self, n):self.family = [i for i in range(n)]self.redundant = 0def find(self,x):root = xwhile self.family[root]!=root:root = self.family[root]while root!=x:self.family[x], x = root, self.family[x]return rootdef union(self,x,y):root_x, root_y = self.find(x), self.find(y)if root_x!=root_y:self.family[root_x] = root_ydef is_connected(self,x,y):return self.find(x) == self.find(y)class Solution:def makeConnected(self, n: int, connections: List[List[int]]) -> int:if len(connections) < n-1:return -1uf = UnionFind(n)for a,b in connections:if uf.is_connected(a,b):uf.redundant+=1uf.union(a, b)clusters = 0for i in range(n):if uf.family[i]==i:clusters+=1if uf.redundant < clusters-1:return -1else:return clusters-1
LinkedList
24. 两两交换链表中的节点
https://leetcode-cn.com/problems/swap-nodes-in-pairs/
链表操作时尽量使用dummy节点
注意post节点更新的时机class Solution:def swapPairs(self, head: ListNode) -> ListNode:if not head or not head.next:return headdummy = ListNode(-1)dummy.next = headpre = dummywhile head and head.next:post = head.next# swaphead.next = post.nextpost.next = headpre.next = post# update pointerpre = headhead = head.nextreturn dummy.next
206. 反转链表
https://leetcode-cn.com/problems/reverse-linked-list/
迭代class Solution:def reverseList(self, head: ListNode) -> ListNode:cur = Nonewhile head:tmp = head.nexthead.next = curcur = headhead = tmpreturn cur
递归
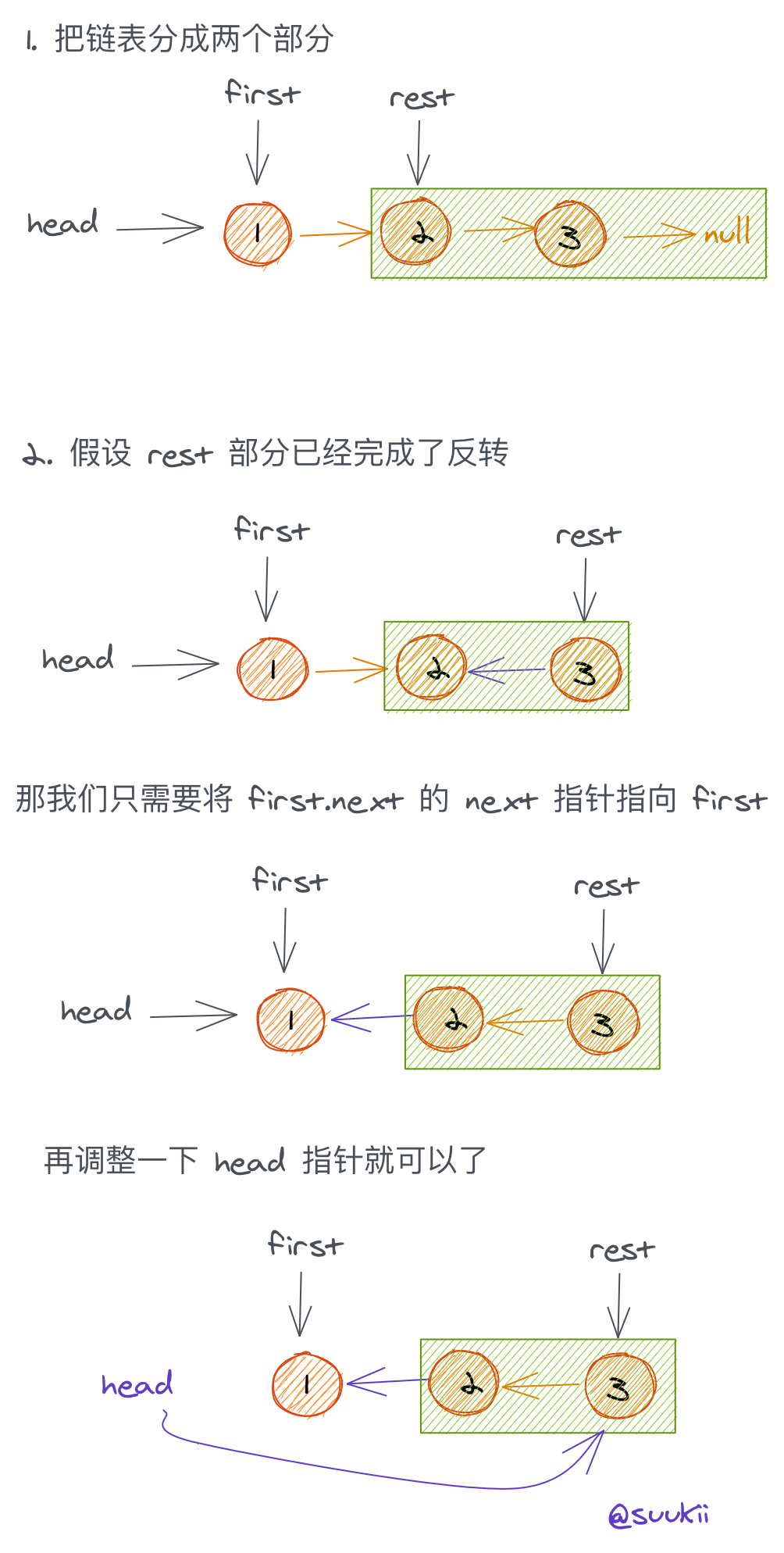
class Solution:def reverseList(self, head: ListNode) -> ListNode:if not head or not head.next:return headnewHead = self.reverseList(head.next)head.next.next = headhead.next = Nonereturn newHead
92. 反转链表 II
https://leetcode-cn.com/problems/reverse-linked-list-ii/
第一个版本写的比较丑,一个指针指向m的pre,一个指针指向n,一直把pre_m.next移动到n的后面就可以了
这种情况需要特殊考虑当m是1的时候,也就是要从第头指针开始反转的情况
第二种: 其实没有必要找到n点,只需要每次把m.next挪到m之前, pre_m之后即可# Definition for singly-linked list.# class ListNode:# def __init__(self, val=0, next=None):# self.val = val# self.next = nextclass Solution:def reverseBetween(self, head: ListNode, m: int, n: int) -> ListNode:if m == n:return headdummy = ListNode(-1)dummy.next = headpre = dummyi = 0while i < m-1:pre = pre.nexti += 1pre_m = prewhile i < n:pre = pre.nexti += 1node_n = prei = 0while i < n - m :# 从前面拿出来node = pre_m.nextpre_m.next = pre_m.next.next# 放到后面去tmp = node_n.nextnode_n.next = nodenode.next = tmpi += 1return dummy.next
只需要找到反转的起始位置, 使用头插法
用一个守卫节点指向反转起始位置,设为g
起始位置为p, 每次将p.next放到g.next. 循环m-n次class Solution:def reverseBetween(self, head: ListNode, left: int, right: int) -> ListNode:if left == right:return headdummy = ListNode(-1)dummy.next = headpre = dummyi = 0while i < left-1:pre = pre.nexti += 1g = prep = g.nextfor i in range(right-left):tmp = p.nextp.next = tmp.nexttmp.next = g.nextg.next = tmpreturn dummy.next
445. 两数相加 II
https://leetcode-cn.com/problems/add-two-numbers-ii/
class Solution:def addTwoNumbers(self, l1: ListNode, l2: ListNode) -> ListNode:stack_l1 = []stack_l2 = []while l1:stack_l1.append(l1.val)l1 = l1.nextwhile l2:stack_l2.append(l2.val)l2 = l2.nextcarry = 0while stack_l2 or stack_l1 or carry:a = stack_l2.pop() if stack_l2 else 0b = stack_l1.pop() if stack_l1 else 0summary = a+b+carrynode = ListNode(summary%10)carry = summary//10node.next = headhead = nodereturn head
21. 合并两个有序链表
https://leetcode-cn.com/problems/merge-two-sorted-lists/
迭代class Solution:def mergeTwoLists(self, l1: ListNode, l2: ListNode) -> ListNode:dummy = ListNode(-1)res = dummywhile l1 and l2:if l2.val<l1.val:res.next = l2l2 = l2.nextelse:res.next = l1l1 = l1.nextres = res.nextres.next = l1 if l1 else l2return dummy.next
递归
class Solution:def mergeTwoLists(self, l1: ListNode, l2: ListNode) -> ListNode:if not l1:return l2if not l2:return l1if l1.val<l2.val:l1.next = self.mergeTwoLists(l1.next, l2)return l1else:l2.next = self.mergeTwoLists(l1, l2.next)return l2
23. 合并K个升序链表
https://leetcode-cn.com/problems/merge-k-sorted-lists/
21的升级版循环遍历k个链表, python会TLE
class Solution:def mergeKLists(self, lists: List[ListNode]) -> ListNode:if not lists:returndummy = ListNode(0)res = dummysize = len(lists)while True:minNode = NoneminPointer = -1for i in range(len(lists)):if not lists[i]:continueif not minNode or lists[i].val < minNode.val:minNode = lists[i]minPointer = iif minPointer==-1:breakres.next = minNoderes = res.nextlists[minPointer] = lists[minPointer].nextreturn dummy.next
分治, 归并排序应用于链表
class Solution:def mergeKLists(self, lists: List[ListNode]) -> ListNode:if not lists:returndef mergeTwoLists(l1,l2):dummy = ListNode(-1)res = dummywhile l1 and l2:if l2.val<l1.val:res.next = l2l2 = l2.nextelse:res.next = l1l1 = l1.nextres = res.nextres.next = l1 if l1 else l2return dummy.nextdef merge(lists, lo, hi):if lo==hi:return lists[lo]mid = lo + (hi-lo)//2l1 = merge(lists, lo, mid)l2 = merge(lists, mid+1, hi)return mergeTwoLists(l1,l2)return merge(lists, 0 , len(lists)-1)
拍案叫绝,给ListNode class增加lt方法, 就可以用来比较大小
class Solution:def mergeKLists(self, lists: List[ListNode]) -> ListNode:def __lt__(self, other):return self.val < other.valListNode.__lt__ = __lt__import heapqheap = []dummy = ListNode(-1)p = dummyfor l in lists:if l:heapq.heappush(heap, l)while heap:node = heapq.heappop(heap)p.next = ListNode(node.val)p = p.nextif node.next:heapq.heappush(heap, node.next)return dummy.next
25. K 个一组翻转链表
https://leetcode-cn.com/problems/reverse-nodes-in-k-group/
一旦看到翻转顺序, 请第一时间先想到stack!160. 相交链表
https://leetcode-cn.com/problems/intersection-of-two-linked-lists/
我一开始想到的是用哈希表,两个链表都往哈希表里存,如果一个链表存的时候发现已经存在了,那么肯定是另外一个链表存进去的,此时返回这个节点
但是这样空间复杂度太高, 这道题可以用空间复杂度为0(1)的解法, 也就是长短链表拼接,假设两个链表相交,那么相交的部分长度是相等的,我们分为一个长链表一个短链表, 两个链表从表头开始循环,如果长的走完了,那么就走短的,如果短的走完了,那么就走长的; 如果有交点,那么他们会同时抵达交点,此刻走过的路程都是等于 长+短+相交, 顺序是 长+相交+短 和 短+相交+长。
这里最巧妙的地方在于边界条件的处理,要把最后一个节点之后的None也加到循环中来, 这样如果两个链表不相交,那么最终会在等于None的地方相交(满足退出条件)class Solution:def getIntersectionNode(self, headA: ListNode, headB: ListNode) -> ListNode:ha, hb = headA, headBwhile ha!=hb:ha = ha.next if ha else headBhb = hb.next if hb else headAreturn ha
138. 复制带随机指针的链表
https://leetcode-cn.com/problems/copy-list-with-random-pointer/ ```python “””
Definition for a Node.
class Node: def init(self, x: int, next: ‘Node’ = None, random: ‘Node’ = None):
self.val = int(x)self.next = nextself.random = random
“””
class Solution: def copyRandomList(self, head: ‘Node’) -> ‘Node’: lookup = {} if not head: return None p = head while p: lookup[p] = Node(p.val) p = p.next p = head while p: lookup[p].next = lookup[p.next] if p.next else None p = p.next p = head while p: lookup[p].random = lookup[p.random] if p.random else None p = p.next return lookup[head]
<a name="1lT4Q"></a>#### [234. 回文链表](https://leetcode-cn.com/problems/palindrome-linked-list/)[https://leetcode-cn.com/problems/palindrome-linked-list/](https://leetcode-cn.com/problems/palindrome-linked-list/)<br />简单的题不简单的做, 涉及快慢指针, 链表反转<br />用快慢指针找到链表的中间位置 ( 注意链表长度的奇偶分别判断)<br />反转链表后半部分<br />此时两个指针分别指向链表的开头 和 链表中间(后半部分已经翻转)<br />逐个对比, 判断回文```python# Definition for singly-linked list.# class ListNode:# def __init__(self, val=0, next=None):# self.val = val# self.next = nextclass Solution:def isPalindrome(self, head: ListNode) -> bool:if not head or not head.next:return Truefast,slow = head,head# fast pointer is twice faster than slow pointerwhile fast and fast.next:slow = slow.nextfast = fast.next.next# if fast pointer is not None, it means the length of linkedlist is oddif fast:slow = slow.next# reverse the linkedlist leading by slow pointerpre = ListNode(-1)pre.next = slowwhile slow.next:post = slow.nextslow.next = post.nextpost.next = pre.nextpre.next = postslow = pre.next# compare from headwhile head and slow:if head.val!=slow.val:return Falsehead = head.nextslow = slow.nextreturn True
DFS&BFS
200. 岛屿数量
https://leetcode-cn.com/problems/number-of-islands/
This question can be solved by DFS, BFS, Union-Find, I only practiced DFS and Union-Find
这道题也可以不用visited函数,在原来grid上修改,但是如果面试中,需要询问是否可以修改原数组
class Solution:def numIslands(self, grid: List[List[str]]) -> int:rows = len(grid)if rows==0:return 0cols = len(grid[0])visited = [[False for _ in range(cols)] for _ in range(rows)]DIRECTION = ((1,0),(-1,0),(0,1),(0,-1))count = 0def isArea(x,y):return x>=0 and y>=0 and x<=rows-1 and y<=cols-1def dfs(i,j):visited[i][j] = Truefor k in range(4):x = i + DIRECTION[k][0]y = j + DIRECTION[k][1]if isArea(x,y) and not visited[x][y] and grid[x][y]=='1':dfs(x,y)for i in range(rows):for j in range(cols):if not visited[i][j] and grid[i][j]=='1':dfs(i,j)count+=1return count
BFS
主函数差不多,遍历函数用一个队列来维护了和当前岛屿连接的岛屿,注意DFS只需要向下或者向右,BFS需要把上下左右都加进来查看
from collections import dequeclass Solution:def numIslands(self, grid: List[List[str]]) -> int:rows =len(grid)cols =len(grid[0])DIRECTION = ((1,0),(0,1),(-1,0),(0,-1))count=0def inArea(x,y):return x>=0 and y>=0 and x<rows and y<colsdef bfs(x,y):queue = deque()queue.append([x,y])while queue:i,j = queue.popleft()if inArea(i,j) and grid[i][j]=='1':grid[i][j]='0'for k in range(4):queue.append([i+DIRECTION[k][0],j+DIRECTION[k][1]])for i in range(rows):for j in range(cols):if grid[i][j]=='1':bfs(i,j)count+=1return count
22. 括号生成
https://leetcode-cn.com/problems/generate-parentheses/
left和right从n开始递减,表示还剩多少个括号留下没用
def generateParenthesis(self, n: int) -> List[str]:res = []cur_str = ''def dfs(cur_str, left, right):'''params:cur_str, the string from root to leafleft, how many left ( leftright, how many right ) left'''if left==0 and right==0:res.append(cur_str)returnif right<left:returnif left > 0:dfs(cur_str+'(', left-1,right)if right >0:dfs(cur_str+')', left, right-1)dfs(cur_str, n,n)return res
left和right从0开始,逐渐增加,注意判断条件变成了right要严格小于left,如果大于了就要return
def generateParenthesis(self, n: int) -> List[str]:res = []cur_str = ''def dfs(cur_str, left, right):'''params:cur_str, the string from root to leafleft, how many left ( leftright, how many right ) left'''if left==n and right==n:res.append(cur_str)returnif right>left:returnif left < n:dfs(cur_str+'(', left+1,right)if right < n:dfs(cur_str+')', left, right+1)dfs(cur_str, 0,0)return res
剑指 Offer 12. 矩阵中的路径
https://leetcode-cn.com/problems/ju-zhen-zhong-de-lu-jing-lcof/
329. 矩阵中的最长递增路径
https://leetcode-cn.com/problems/longest-increasing-path-in-a-matrix/
拓扑排序, 课程表是为了找环,如果有环,说明无法学完全部课程,因为有的课程互为先决条件,导致有环出现。
这道题以数字大小来作为出度入度,是肯定没有环的,要计算的最长路径,那么就是每次把入度为0的作为一层,将这一层点挪去之后,还剩下的入度为0的点就是下一次,加入队列进入下一次循环, 经过多少次循环后再也没有入度为0的点就得到了最长递增路径
from collections import dequeclass Solution:def longestIncreasingPath(self, matrix: List[List[int]]) -> int:if not matrix:return 0rows, cols = len(matrix), len(matrix[0])DIRECTION = ((1,0),(-1,0),(0,1),(0,-1))# indegrees每个坐标上的值,是matrix对应坐标位置的入度indegrees = [[0 for _ in range(cols)] for _ in range(rows)]def inArea(x,y):return x>=0 and y>=0 and x<rows and y<cols# calculate the indegreesfor i in range(rows):for j in range(cols):for k in range(4):new_x = i + DIRECTION[k][0]new_y = j + DIRECTION[k][1]if inArea(new_x, new_y) and matrix[i][j] > matrix[new_x][new_y]:indegrees[i][j]+=1queue = deque()# 入度为0的坐标进入队列for i in range(rows):for j in range(cols):if indegrees[i][j] == 0:queue.append((i,j))res = 0while queue:# 每一层遍历 res+1res += 1for _ in range(len(queue)):x, y = queue.popleft()for k in range(4):new_x = x + DIRECTION[k][0]new_y = y + DIRECTION[k][1]if inArea(new_x,new_y) and matrix[x][y] < matrix[new_x][new_y]:indegrees[new_x][new_y] -= 1if indegrees[new_x][new_y] == 0:queue.append((new_x,new_y))return res
从最小的数字开始,遍历每个点附近的四个点, 取这四个点里(1.没有出界,2.值比当前点小)的当前路径最长的,然后这个点的路径就是那个附近最长路径+1, 如果附近四个点都比当前点大,那么这个点就是一个起始点,最长路径为1
from collections import dequeclass Solution:def longestIncreasingPath(self, matrix: List[List[int]]) -> int:if not matrix:return 0rows, cols = len(matrix), len(matrix[0])DIRECTION = ((1,0),(-1,0),(0,1),(0,-1))dp = [[0]*cols for _ in range(rows)]def inArea(x,y):return x>=0 and y>=0 and x<rows and y<colspoints = sorted([[matrix[i][j], (i,j)] for i in range(rows) for j in range(cols)])res = 0for point in points:value = point[0]x, y = point[1]max_path = 0for k in range(4):new_x = x + DIRECTION[k][0]new_y = y + DIRECTION[k][1]if inArea(new_x, new_y) and matrix[new_x][new_y] < value:max_path = max(max_path, dp[new_x][new_y])dp[x][y] = max_path+1res = max(res, dp[x][y])return res
130. 被围绕的区域
https://leetcode-cn.com/problems/surrounded-regions/
和边界的O连接的o不变, 其他位置的o都是被围绕的,需要被设置为x
那么dfs bfs 和并查集都可以解决,思路是先处理边界位置的O, 把和边界相连的o都置为,比如#,结束遍历后再重新遍历一次board, 把#置为o,把o置为x
dfs是递归, bfs是用队列
class Solution:def solve(self, board: List[List[str]]) -> None:"""Do not return anything, modify board in-place instead."""if not board:return boardrows, cols = len(board), len(board[0])DIRECTION = ((0,1),(1,0),(0,-1),(-1,0))ans = []def inArea(x, y):return x >= 0 and y>=0 and x<rows and y<colsdef dfs(x, y):board[x][y] = '#'for k in range(4):new_x = x + DIRECTION[k][0]new_y = y + DIRECTION[k][1]if inArea(new_x, new_y) and board[new_x][new_y] == 'O':dfs(new_x, new_y)# up&bottom boaderfor j in range(cols):if board[0][j] == 'O':dfs(0,j)if board[rows-1][j] == 'O':dfs(rows-1, j)# left&right boaderfor i in range(rows):if board[i][0] == 'O':dfs(i,0)if board[i][cols-1] == 'O':dfs(i,cols-1)for i in range(rows):for j in range(cols):board[i][j] = 'O' if board[i][j] == '#' else 'X'return board
778. 水位上升的泳池中游泳
https://leetcode-cn.com/problems/swim-in-rising-water/
优先队列, Python的实现是二叉堆. 相当于flood fill, 类似bfs的思维. 不是贪心只关注当前点周围可以去到的最低的点, 而是当前走过的点里面去找最低的点. 比如一个点如果选择过, 那么这个点的→和↓就会变为可接触的点,并且进入二叉堆heap, 每次我们都选择这些可接触点的最小值,也就是二叉堆的堆顶
import heapqclass Solution:def swimInWater(self, grid: List[List[int]]) -> int:if not grid:return 0rows, cols = len(grid), len(grid[0])visited = [[False]*cols for _ in range(rows)]heap = []heapq.heappush(heap, (grid[0][0],(0,0)))high = float('-inf')DIRECTION = ((1,0), (0,1), (-1,0), (0,-1))while heap:height, loc = heapq.heappop(heap)high = max(high, height)x, y = locvisited[x][y] = Trueif x == rows-1 and y == cols-1:return highfor k in range(4):new_x = x + DIRECTION[k][0]new_y = y + DIRECTION[k][1]if 0<=new_x<rows and 0<=new_y<cols and not visited[new_x][new_y]:heapq.heappush(heap, (grid[new_x][new_y], (new_x, new_y)) )
BackTracking
回溯算法和深度优先遍历
「回溯算法」与「深度优先遍历」都有「不撞南墙不回头」的意思。我个人的理解是:「回溯算法」强调了「深度优先遍历」思想的用途,用一个 不断变化 的变量,在尝试各种可能的过程中,搜索需要的结果。强调了 回退 操作对于搜索的合理性。而「深度优先遍历」强调一种遍历的思想,与之对应的遍历思想是「广度优先遍历」
回溯算法用于搜索一个问题的所有的解,用到了DFS的思想
回溯和动态规划:
DP只需要知道最优解是什么,不关心怎么来的
回溯要列举出所有的可能性
排列问题
按顺序枚举每一位可能出现的情况,已经选择的数字在 当前 要选择的数字中不能出现。按照这种策略搜索就能够做到 不重不漏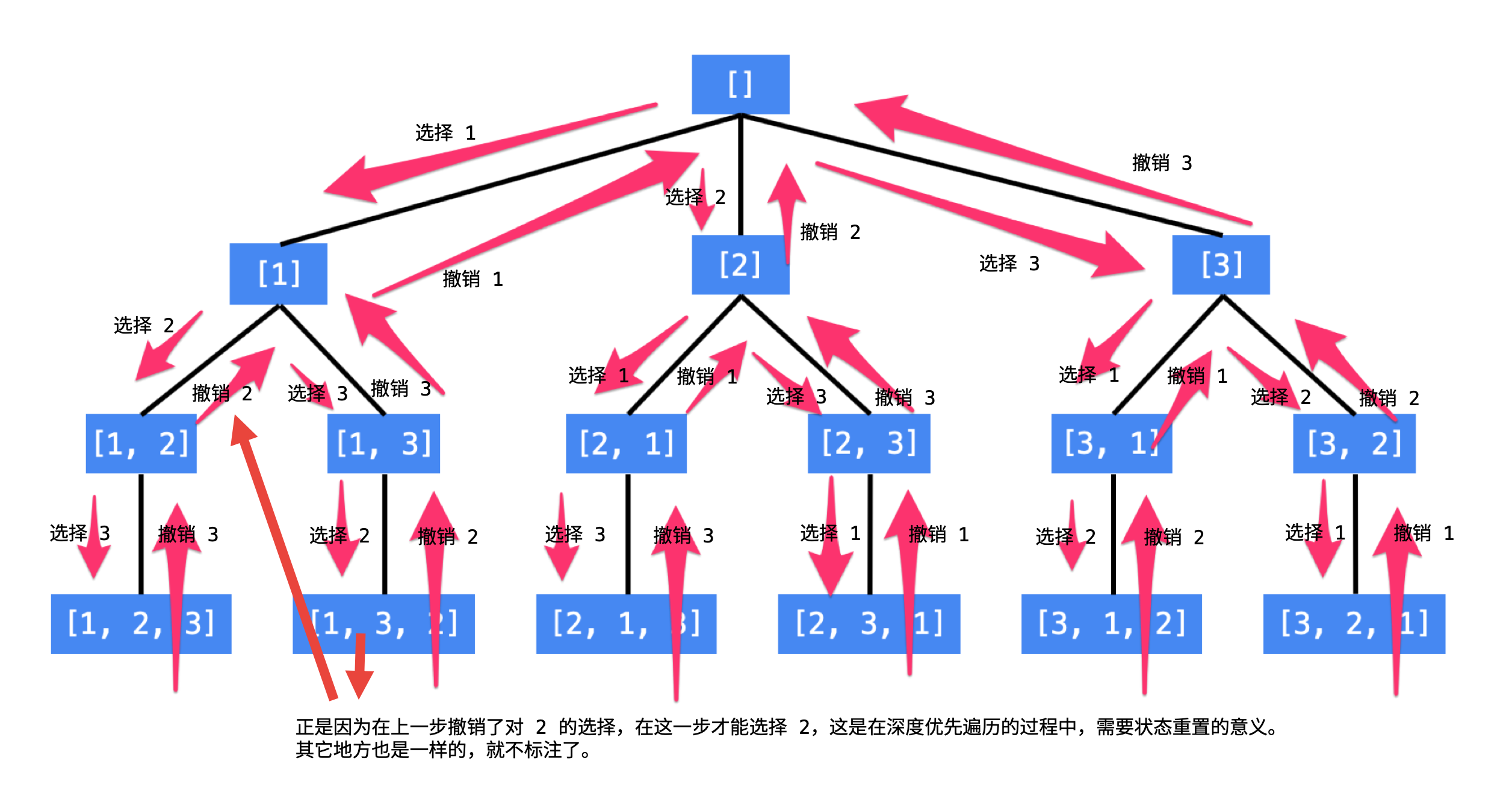
回溯和普通的DFS的区别在于,有回头的过程,且回头的时候需要把当前已经访问的节点状态重置
- 按引用传递状态
- 所有的状态修改在递归完成后回改
46. 全排列
https://leetcode-cn.com/problems/permutations/
# res = []# def backtracking(nums, tmp):# if not nums:# res.append(tmp)# return# for i in range(len(nums)):# backtracking(nums[:i]+nums[i+1:], tmp+[nums[i]])# backtracking(nums,[])# return resdepth = len(nums)visited = [False for _ in range(depth)]res = []def backtracking(temp_list, height):if height == depth:res.append(temp_list)returnfor i in range(depth):if not visited[i]:visited[i] = Truebacktracking(temp_list+[nums[i]],height+1)visited[i] = Falsebacktracking([],0)return res
47. 全排列 II
https://leetcode-cn.com/problems/permutations-ii/
主要是去重的判断条件.
- 排序, 保证相同的数字都相邻
不选择的情况有:
- 当前元素已经visited
i>0 且当前元素等于前一个元素 且 前一个元素已经被使用.
class Solution:def permuteUnique(self, nums: List[int]) -> List[List[int]]:n = len(nums)if n <2:return [nums]res = []nums.sort()visited = [False for _ in range(n)]def backtracking(temp_list, depth):if depth==n:res.append(temp_list)for i in range(n):if visited[i] or (i>0 and nums[i]==nums[i-1] and not visited[i-1]):continuevisited[i]=Truebacktracking(temp_list+[nums[i]], depth+1)visited[i]=Falsebacktracking([],0)return res
77. 组合
class Solution:def combine(self, n: int, k: int) -> List[List[int]]:res = []if k>n:return resif k == 0:return [res]def backtracking(nums,temp_list, index):if len(temp_list)==k:res.append(temp_list[:])returnfor i in range(index,n):temp_list.append(nums[i])backtracking(nums[index:],temp_list, i+1)temp_list.pop()nums = [i for i in range(1,n+1)]backtracking(nums,[],0)return res
39. 组合总和
https://leetcode-cn.com/problems/combination-sum/
什么时候使用 used/visited数组,什么时候使用 begin 变量
- 排列问题: 讲究顺序(即 [2, 2, 3] 与 [2, 3, 2] 视为不同列表时,需要记录哪些数字已经使用过,此时用 used 数组;
- 组合问题:不讲究顺序(即 [2, 2, 3] 与 [2, 3, 2] 视为相同列表时,需要按照某种顺序搜索,此时使用 begin 变量。
注意:具体问题应该具体分析, 理解算法的设计思想 是至关重要的,请不要死记硬背。
class Solution:def combinationSum(self, candidates: List[int], target: int) -> List[List[int]]:candidates.sort()res = []length = len(candidates)def backtracking(temp_list, index, target):if target==0:res.append(temp_list[:])returnfor i in range(index, length):residue = target - candidates[i]if residue < 0:breakbacktracking(temp_list+[candidates[i]], i, residue)backtracking([],0,target)return res
40. 组合总和 II
https://leetcode-cn.com/problems/combination-sum-ii/
这道题的核心相比上一题在于去重,也就是代码备注的部分
https://leetcode-cn.com/problems/combination-sum-ii/solution/hui-su-suan-fa-jian-zhi-python-dai-ma-java-dai-m-3/
参考高赞评论
class Solution:def combinationSum2(self, candidates: List[int], target: int) -> List[List[int]]:size = len(candidates)res = []if size<1:return []def backtracking(temp_list, begin, target):if target == 0:res.append(temp_list[:])returnfor i in range(begin,size):residue = target - candidates[i]if residue<0:break#去重的核心在于这个判断# i>begin是为了保证同一层的第一个和上一级相同的数是允许的# i == i-1 是说同一层第二个及以后相同的数是不允许的if i > begin and candidates[i]==candidates[i-1]:continuebacktracking(temp_list+[candidates[i]],i+1, residue)candidates.sort()backtracking([],0,target)return res
17. 电话号码的字母组合
https://leetcode-cn.com/problems/letter-combinations-of-a-phone-number/
难得被回溯虐了一天半之后, 自己调试出来一道回溯的题
class Solution:def letterCombinations(self, digits: str) -> List[str]:lookup = {'2':'abc','3':'def','4':'ghi','5':'jkl','6':'mno','7':'pqrs','8':'tuv','9':'wxyz'}size = len(digits)res = []if size==0:return []def backtracking(temp_list, index):if len(temp_list) == size:res.append("".join(temp_list[:]))# 不要试图去构建递归的整个过程,理解两层循环所对应的不同的树的层级for i in range(index,size): # 这一层循环对应每个数字panel = lookup[digits[i]] # 每个数字对应3 or 4个字母for j in range(len(panel)): # 这个字母里选一个backtracking(temp_list+[panel[j]],i+1)backtracking([],0)return res
79. 单词搜索
https://leetcode-cn.com/problems/word-search/
一开始我按照岛屿问题的方法写,发现返回不到想要的结果。
line16标记,line22退回, 因为一个矩阵里,可能有多个相同的字母,有时候从一个位置出发不行,但从另一个位置出发是可以的
class Solution:def exist(self, board: List[List[str]], word: str) -> bool:if not board:return Falserows = len(board)cols = len(board[0])DIRECTION = ((1,0),(-1,0),(0,1),(0,-1))visited=[[False for _ in range(cols)] for _ in range(rows)]def inArea(x,y):return x>=0 and y>=0 and x<rows and y<colsdef dfs(index,x,y):if index == len(word)-1:return board[x][y]==word[index]if board[x][y]==word[index]:visited[x][y]=Truefor k in range(4):new_x = x + DIRECTION[k][0]new_y = y + DIRECTION[k][1]if inArea(new_x,new_y) and not visited[new_x][new_y] and dfs(index+1,new_x,new_y):return Truevisited[x][y]=Falsefor i in range(rows):for j in range(cols):if dfs(0,i,j):return Truereturn False
Array
189. 旋转数组
https://leetcode-cn.com/problems/rotate-array/
我自己能想到的就是python的slicingclass Solution:def rotate(self, nums: List[int], k: int) -> None:"""Do not return anything, modify nums in-place instead."""if len(nums) < 2:return numsk = k%len(nums)nums[k:],nums[:k] = nums[:-k],nums[-k:]return nums
这个题看到比较有趣的一个办法就是三次反转法
先把[0, n - k - 1]翻转
然后把[n - k, n - 1]翻转
最后把[0, n - 1]翻转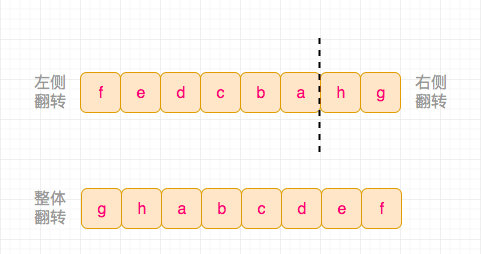
剑指 Offer 29. 顺时针打印矩阵
https://leetcode-cn.com/problems/shun-shi-zhen-da-yin-ju-zhen-lcof/
先来个普通的常规的思路class Solution:def spiralOrder(self, matrix: List[List[int]]) -> List[int]:if not matrix:return []left,right,top,bottom = 0, len(matrix[0])-1, 0, len(matrix)-1res = []while True:for i in range(left,right+1):res.append(matrix[top][i])top+=1if top > bottom:breakfor i in range(top, bottom+1):res.append(matrix[i][right])right-=1if left > right:breakfor i in range(right,left-1,-1):res.append(matrix[bottom][i])bottom-=1if top > bottom:breakfor i in range(bottom,top-1,-1):res.append(matrix[i][left])left+=1if left > right:breakreturn res
再来一个牛逼plus的思路:拿着矩阵每次就从左向右输出最上面的一行,然后逆时针翻转90度,这样下一排刚输出的元素就又到了矩阵的第一行,且顺序是从左向右
class Solution:def spiralOrder(self, matrix: List[List[int]]) -> List[int]:res = []while matrix:res += matrix.pop(0)matrix = list(zip(*matrix))[::-1]return res
剑指 Offer 59 - I. 滑动窗口的最大值
https://leetcode-cn.com/problems/hua-dong-chuang-kou-de-zui-da-zhi-lcof/

215. 数组中的第K个最大元素
https://leetcode-cn.com/problems/kth-largest-element-in-an-array/
import randomclass Solution:def findKthLargest(self, nums: List[int], k: int) -> int:def partition(nums,lo,hi):random_no = random.randint(lo,hi)nums[hi], nums[random_no] = nums[random_no], nums[hi]pivot = nums[hi]left = lofor i in range(lo,hi):if nums[i] < pivot:nums[i], nums[left] = nums[left], nums[i]left+=1nums[left], nums[hi] = nums[hi], nums[left]return leftlow = 0high = len(nums)-1k = len(nums)-kwhile True:j = partition(nums,low, high)if j<k:low=j+1elif j>k:high=j-1else:return nums[j]
692. 前K个高频单词
https://leetcode-cn.com/problems/top-k-frequent-words/
比215稍微复杂一下,除了比较数字,还需要比较对应的字符串的大小,注意用到cmp_to_key的功能
48. 旋转图像
https://leetcode-cn.com/problems/rotate-image/
可以先逐行翻转,再沿着斜对角翻转
也可以先沿对角线翻转,再逐行翻转 (这个方式代码写起来简单一些)
419. 甲板上的战舰
https://leetcode-cn.com/problems/battleships-in-a-board/
用战舰的头来判断数量
- 如果是第一行或者第一列为x, 那么计算一列战舰
- 如果在中间出现x,而这个点的左边或者上边是x,那么这肯定是战舰中部,这列战舰在遇到头部的时候已经计算过了,无需再重复计算
class Solution:def countBattleships(self, board: List[List[str]]) -> int:count = 0for i in range(len(board)):for j in range(len(board[0])):if board[i][j] == '.': continueif i > 0 and board[i-1][j] == 'X': continueif j > 0 and board[i][j-1] == 'X': continuecount+=1return count
1314. 矩阵区域和
https://leetcode-cn.com/problems/matrix-block-sum/
所有的前缀和,都需要额外加个0前缀和,用来给第一个元素的前缀和用
前缀和,注意包括和不包括的情况, 前缀和矩阵里的[rows,cols]是开区间,意思到[rows-1,cols-1]之间所有元素的和
所以在计算answer的时候max_x需要+1,因为max_x的位置需要包括;而min_x的地方不+1class Solution:def matrixBlockSum(self, mat: List[List[int]], K: int) -> List[List[int]]:rows, cols = len(mat), len(mat[0])k = Kanswer = [[0 for _ in range(cols)] for _ in range(rows)]pre_sum = [[0 for _ in range(cols+1)] for _ in range(rows+1)]for i in range(1, rows+1):for j in range(1, cols+1):pre_sum[i][j] = pre_sum[i-1][j] + pre_sum[i][j-1] - pre_sum[i-1][j-1]+mat[i-1][j-1]for i in range(rows):for j in range(cols):min_rows = i-k if i-k>=0 else 0max_rows = i+k if i+k<rows else rows-1min_cols = j-k if j-k>=0 else 0max_cols = j+k if j+k<cols else cols-1answer[i][j] = pre_sum[max_rows+1][max_cols+1] - pre_sum[min_rows][max_cols+1] - pre_sum[max_rows+1][min_cols] + pre_sum[min_rows][min_cols]return answer
Dynamic Programming
152. 乘积最大子数组
https://leetcode-cn.com/problems/maximum-product-subarray/
如果都是正整数,那整个array都乘下来就是最大的,需要考虑的特殊情况是:
- 负整数, 会让结果从很大变成很小,但如果再来一个负整数,结果又会重新变的很大,所以需要同时保留一个最大的正数和最小的负数。
- 因为一旦array里包括0,那么整个数字都为0,所以如果出现0,应当排除,这就是为什么LINE 9max和min里加上了当前的num,这样不至于让current_max和current_min一直是0



class Solution:def maxProduct(self, nums: List[int]) -> int:if not nums:return -1current_pos = nums[0]current_neg = nums[0]final_max = nums[0]for num in nums[1:]:current_pos, current_neg = max(current_pos*num,current_neg*num,num), min(current_pos*num,current_neg*num,num)if current_pos > final_max:final_max = current_posreturn final_max
剑指 Offer 49. 丑数
https://leetcode-cn.com/problems/chou-shu-lcof/
关于是下一个丑数一定是前面某个数乘2或者乘3或者乘5得到的,而且是这三个乘积里最小的一个,因为是要求紧接着的那个丑数。
从第一个开始,每当下一个丑数是用2,3,5某一个乘到的,那么2,3,5对应的point就应该加一个
class Solution:def nthUglyNumber(self, n: int) -> int:dp = [1] * na ,b,c = 0,0,0for i in range(1,n):n2,n3,n5 = dp[a]*2,dp[b]*3,dp[c]*5dp[i] = min(n2,n3,n5)if dp[i] == n2: a+=1if dp[i] == n3: b+=1if dp[i] == n5: c+=1return dp[-1]
10. 正则表达式匹配
https://leetcode-cn.com/problems/regular-expression-matching/
class Solution:def isMatch(self, s: str, p: str) -> bool:'''s : 等待匹配p : regex'''if not p: return not sif not s and len(p)==1: return False# 数组长度多加一个是为了匹配字符串为空的情况# 所以数组的下标-1才是字符串的下标rows = len(s)+1cols = len(p)+1dp = [[False for _ in range(cols)] for _ in range(rows)]# initializationdp[0][0]=True # s and p are all empty, matchdp[0][1]=False # s is empty, p only have one char, not matchfor c in range(2,cols): # s is empty, p longer than 2j = c-1 # j for the index in stringif p[j]=='*':dp[0][c] = dp[0][c-2]for x in range(1,rows): # s string be matchedi = x-1for y in range(1,cols): # regex patternj=y-1if s[i]==p[j] or p[j]=='.':dp[x][y]=dp[x-1][y-1]elif p[j]=='*':if p[j-1]==s[i] or p[j-1]=='.':dp[x][y]=dp[x][y-2] or dp[x-1][y]else:dp[x][y]=dp[x][y-2]else:dp[x][y]=Falsereturn dp[rows-1][cols-1]
5. 最长回文子串
https://leetcode-cn.com/problems/longest-palindromic-substring/
class Solution:def longestPalindrome(self, s: str) -> str:m = len(s)# row is i, column is jdp = [[False for _ in range(m)] for _ in range(m)]max_len = 1start = 0for j in range(m):for i in range(j+1):if s[i]==s[j]:if j -i < 3:dp[i][j] = Trueelse:dp[i][j] = dp[i+1][j-1]else:dp[i][j] = Falseif dp[i][j] and j - i + 1 > max_len:max_len = j - i +1start = ireturn s[start: start+max_len]
42. 接雨水
https://leetcode-cn.com/problems/trapping-rain-water/
动态规划的内存消耗比较高, 注意最左边的max_left是自己,最右边的max_right是自己
class Solution:def trap(self, height: List[int]) -> int:if not height:return 0length = len(height)max_left, max_right = [0]*length, [0]*lengthmax_left[0] = height[0]max_right[-1] = height[-1]for i in range(1,length):max_left[i] = max(max_left[i-1], height[i-1])for i in range(length-2, -1, -1):max_right[i] = max(max_right[i+1], height[i+1])res = 0for i in range(length):low_bound = min(max_left[i],max_right[i])res += max(0, low_bound-height[i])return res
双指针解法:
从两边往中间扫,如果left_max > right_max就处理左边的列, 反之则处理右边的列
class Solution:def trap(self, height: List[int]) -> int:if not height:return 0left_max, right_max = 0, 0res = 0left = 0right = len(height)-1while left<=right:if left_max < right_max:res += max(0, left_max-height[left])left_max = max(left_max,height[left])left+=1else:res += max(0, right_max-height[right])right_max = max(right_max, height[right])right-=1return res
数学解法, 不需要额外空间
如下图,从左往右遍历,不管是雨水还是柱子,都计算在有效面积内,并且每次累加的值根据遇到的最高的柱子逐步上升。面积记为S1。
从左往右遍历得S1,每步S1+=max1且max1逐步增大
同样地,从右往左遍历可得S2。
从右往左遍历得S2,每步S2+=max2且max2逐步增大
于是我们有如下发现,S1 + S2会覆盖整个矩形,并且:重复面积 = 柱子面积 + 积水面积
最终, 积水面积 = S1 + S2 - 矩形面积 - 柱子面积
class Solution:def trap(self, height: List[int]) -> int:if not height:return 0max_height = 0left_area = 0for h in height:max_height = max(max_height, h)left_area += max_heightmax_height = 0right_area = 0for i in range(len(height)-1, -1, -1):max_height = max(max_height, height[i])right_area += max_heightreturn left_area + right_area - (max_height*len(height))- sum(height)
139. 单词拆分
https://leetcode-cn.com/problems/word-break/
如果用递归写,需要把结果memorized
from functools import lru_cacheclass Solution:def wordBreak(self, s: str, wordDict: List[str]) -> bool:@lru_cachedef backtrack(s):if not s:return Trueres = Falsefor i in range(1, len(s)+1):if s[:i] in wordDict:res = backtrack(s[i:]) or resreturn resreturn backtrack(s)
动态规划:
判断一个字符串s的某个位置i是否可以被wordDict来表示,可以拆分为i之前某个位置j可以被wordDict表示,而且j:i之间的string在wordDict里
这里有一些优化方式和注意的点,比如
- base case, dp[0]=True, 所以数组长度是len(s)+1
- i不用从1开始遍历, 可以从单词长度最短的一个开始
当i长度大于最长的单词的时候,j也不用从0开始遍历,可以从最长单词的位置之后开始遍历,因为我们从最短单词长度开始遍历的,所以此时的j最为最长单词的位置,肯定是true的
class Solution:def wordBreak(self, s: str, wordDict: List[str]) -> bool:if wordDict:wordDict = sorted(wordDict, key=len)min_len, max_len = len(wordDict[0]), len(wordDict[-1])else:min_len = max_len = 0dp = [True] + [False] * len(s)for i in range(min_len, len(s)+1):for j in range(max(0,i-max_len), i):if dp[j] and s[j:i] in wordDict:dp[i] = Truebreakreturn dp[-1]
887. 鸡蛋掉落
https://leetcode-cn.com/problems/super-egg-drop/
根据基本状态转移方程先写一个超时的基本解class Solution:def superEggDrop(self, K: int, N: int) -> int:'''dp[i][j], i floors, have j eggsfloors is row, eggs is column'''dp = [[999 for _ in range(K+1)] for _ in range(N+1)]for i in range(N+1):dp[i][0] = 0dp[i][1] = ifor j in range(2,K+1):dp[0][j] = 0dp[1][j]=1for i in range(2,N+1):for j in range(2, K+1):for k in range(1,i+1):dp[i][j] = min(dp[i][j], max(dp[k-1][j-1], dp[i-k][j]) + 1)return dp[N][K]
91. 解码方法
https://leetcode-cn.com/problems/decode-ways/
class Solution:def numDecodings(self, s: str) -> int:if s.startswith('0'):return 0dp = [0] * (len(s) + 1)dp[0], dp[1] = 1,1for i in range(2,len(s)+1):if s[i-1] == '0' and s[i-2] not in '12':return 0elif s[i-2:i] in ['10','20']:dp[i] = dp[i-2]elif '10' < s[i-2:i] < '27':dp[i] = dp[i-1] + dp[i-2]else:dp[i] = dp[i-1]return dp[-1]
322. 零钱兑换
https://leetcode-cn.com/problems/coin-change/
比较容易想到的动态规划class Solution:def coinChange(self, coins: List[int], amount: int) -> int:dp = [0] + [amount+1]*amountfor i in range(1,amount+1):for c in coins:if i < c:continueelse:dp[i] = min(dp[i], dp[i-c]+1)return dp[amount] if dp[amount] != amount+1 else -1
绝了的
class Solution:def coinChange(self, coins: List[int], amount: int) -> int:n = len(coins)coins.sort(reverse=True) # 先给硬币排序,降序self.res = float("inf") # 定义最小的使用硬币的数量为self.resdef dfs(index,target,count): # 定义深度优先搜索算法coin = coins[index]if math.ceil(target/coin)+count>=self.res:returnif target%coin==0:self.res = count+target//coinif index==n-1:returnfor j in range(target//coin,-1,-1):dfs(index+1,target-j*coin,count+j)dfs(0,amount,0)return int(self.res) if self.res!=float("inf") else -1
300. 最长递增子序列
https://leetcode-cn.com/problems/longest-increasing-subsequence/
为了保证计算子问题能够按照顺序、不重复地进行,动态规划要求已经求解的子问题不受后续阶段的影响。这个条件也被叫做「无后效性」。换言之,动态规划对状态空间的遍历构成一张有向无环图,遍历就是该有向无环图的一个拓扑序。有向无环图中的节点对应问题中的「状态」,图中的边则对应状态之间的「转移」,转移的选取就是动态规划中的「决策」。
状态方程 dp[i]为加上nums[i]的时候的最长递增子序列, 所以dp[i]为 0class Solution:def lengthOfLIS(self, nums: List[int]) -> int:if not nums:return 0dp = [1 for _ in range(len(nums))]max_final = 1for i in range(len(nums)):max_sub = 0for j in range(i):if nums[j] < nums[i]:max_sub = max(max_sub, dp[j])dp[i] = max_sub+1max_final = max(max_final, dp[i])return max_final
优化时间复杂度, 引入贪心和二分查找
class Solution:def lengthOfLIS(self, nums: List[int]) -> int:if not nums:return 0tail = [nums[0]]for i in range(1, len(nums)):if nums[i] > tail[-1]:tail.append(nums[i])else:left = 0right = len(tail)-1while left < right:mid = left + (right-left)//2if tail[mid] < nums[i]:left = mid +1else:right = midtail[left] = nums[i]return len(tail)
198. 打家劫舍
https://leetcode-cn.com/problems/house-robber/
打家劫舍系列经典动态规划问题, 从第一题开始.
dp[i] 表示在前i间房子满足条件的情况下可以偷到的最大金额
对于第i间房子来说, 分两种情况, 1) 不偷, 则dp[i]=dp[i-1] 2)偷,那么第i-1是不能偷的 则dp[i] = dp[i-2] + nums[i]
所以转移方程是:
dp[n+1] = max(dp(n), dp(n-1)+nums[n+1])
dp[0] = 0 代表前0间房子, 动态规划中有很多时候, dp数组需要比输入数组长度+1
因为dp[n]只和dp[n-1],dp[n-2]相关, 所以我们可以引入两个变量pre和cur,将空间复杂度降低到O(1)
Greedy
135. 分发糖果
https://leetcode-cn.com/problems/candy/
从前往后遍历,每次和前面一个元素比。
从后往前遍历,每次和后面一个元素比
class Solution:def candy(self, ratings: List[int]) -> int:res = [1]*len(ratings)for i in range(1,len(ratings)):if ratings[i] > ratings[i-1]:res[i]=res[i-1] + 1for i in range(len(ratings)-2,-1,-1):if ratings[i] > ratings[i+1] and res[i]<=res[i+1]:res[i]=res[i+1] + 1return sum(res)
435. 无重叠区间
https://leetcode-cn.com/problems/non-overlapping-intervals/
这道题说的是算出需要移除区间的最少数量,那我们就要尽可能的把右边界小的区间留下来,如果区间交叉了,不更新边界,因为是用右边界排序的, 如果没有交叉,那更新目前无重叠区间的右边界
class Solution:def eraseOverlapIntervals(self, intervals: List[List[int]]) -> int:if len(intervals) < 2:return 0count = 0intervals = sorted(intervals, key = lambda a:a[1])end = intervals[0][1]for s,e in intervals[1:]:if s < end:count+=1else:end = ereturn count
Binary Search
69. x 的平方根
https://leetcode-cn.com/problems/sqrtx/
边界条件的判断是二分查找的唯一难点
start最终会留在平分刚好比x小的那个位置往右一点,也就是说 
class Solution:def mySqrt(self, x: int) -> int:if x < 2:return xstart = 0end = xwhile start <= end:midpoint = start + (end-start)//2if midpoint * midpoint < x:start = midpoint+1elif midpoint * midpoint > x:end = midpoint-1else:return midpointreturn start-1
153. 寻找旋转排序数组中的最小值
https://leetcode-cn.com/problems/find-minimum-in-rotated-sorted-array/
class Solution:def findMin(self, nums: List[int]) -> int:start = 0end = len(nums)-1while start<end:midpoint = start + (end-start)//2if nums[midpoint] > nums[end]:start = midpoint+1else:end = midpointreturn nums[end]
33. 搜索旋转排序数组
https://leetcode-cn.com/problems/search-in-rotated-sorted-array/
其实相对简单的办法还是先找到数组旋转点,也就是最小值在哪里,然后将数组分为两段,根据target和两段的关系来查找
注意等号的选择!
class Solution:def search(self, nums: List[int], target: int) -> int:left = 0right = len(nums)-1while left<=right:mid = left + (right-left)//2if nums[mid]==target:return midif nums[mid]>=nums[left]:if target>=nums[left] and target<nums[mid]:right = mid-1else:left = mid+1else:if target>nums[mid] and target<=nums[right]:left = mid+1else:right = mid-1return -1
1095. 山脉数组中查找目标值
https://leetcode-cn.com/problems/find-in-mountain-array/
有点类似在搜索旋转数组,但是这道题target有可能存在于左右两边各一个
关键在于先找到峰值,然后从峰值一分为二,在两侧都寻找
# """# This is MountainArray's API interface.# You should not implement it, or speculate about its implementation# """#class MountainArray:# def get(self, index: int) -> int:# def length(self) -> int:class Solution:def findMountainTop(self, mountain_arr: 'MountainArray') -> int:left = 0right = mountain_arr.length()-1while left < right:mid = left + (right-left)//2mid_val = mountain_arr.get(mid)if mid_val < mountain_arr.get(mid+1):left = mid+1else:right = midreturn leftdef binarySearch(self, arr, target, left, right, ascend=True):while left <= right:mid = left + (right-left)//2if arr.get(mid) == target:return midelif arr.get(mid) < target:if ascend:left = mid+1else:right = mid-1else:if ascend:right = mid-1else:left = mid+1return -1def findInMountainArray(self, target: int, mountain_arr: 'MountainArray') -> int:peek_idx = self.findMountainTop(mountain_arr)idx = self.binarySearch(mountain_arr, target, 0, peek_idx,True)if idx!=-1:return idxelse:return self.binarySearch(mountain_arr, target, peek_idx, mountain_arr.length()-1, False)
Merge Interval
Two Points
Binary Tree
Concepts
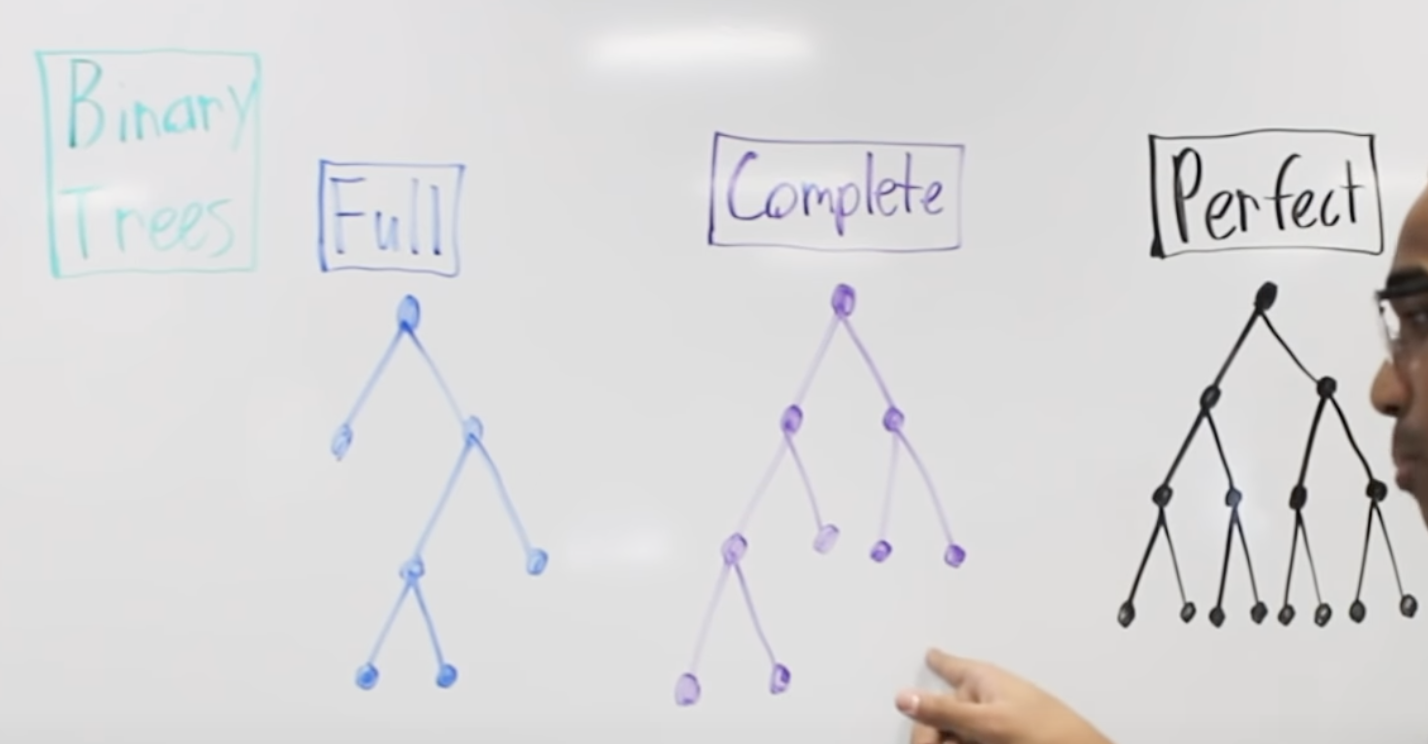
Full: 每个node只有0个或2个children
complete: 从上到下,从左到右
perfect: 每一层都是满的 2**k-1
Focus on a Node! 不要去想递归的过程,不要去想整棵树,就想这一个node要做什么!
What needs to happen at this node?
中序遍历中的一些点
successor, 后驱节点,紧跟着当前节点比当前小的那个节点,先取root.right(如果root.right存在),然后一直取左子树
def succeesor(root):root = root.rightwhile root.left:root = root.leftreturn root
prece, 前驱,比当前节点大一个位置的节点
def predecessor(root):root = root.leftwhile root.right:root = root.rightreturn root
94. 二叉树的中序遍历
https://leetcode-cn.com/problems/binary-tree-inorder-traversal/submissions/
# Definition for a binary tree node.# class TreeNode:# def __init__(self, val=0, left=None, right=None):# self.val = val# self.left = left# self.right = rightclass Solution:def inorderTraversal(self, root: TreeNode) -> List[int]:stack = list()arr = list()while root or stack:while root:stack.append(root)root = root.leftroot = stack.pop()arr.append(root.val)root = root.rightreturn arr
230.二叉搜索树中第K小的元素
https://leetcode-cn.com/problems/kth-smallest-element-in-a-bst/
class Solution:def kthSmallest(self, root: TreeNode, k: int) -> int:stack = list()while root or stack:while root:stack.append(root)root = root.leftroot = stack.pop()k -= 1if not k:return root.valelse:root = root.right
同理找第K大的
class Solution:def kthLargest(self, root: TreeNode, k: int) -> int:stack = list()while root or stack:while root:stack.append(root)root = root.rightroot = stack.pop()k-=1if k==0:return root.valroot = root.leftreturn
98. 验证二叉搜索树
https://leetcode-cn.com/problems/validate-binary-search-tree/
Iteration
class Solution:def isValidBST(self, root: TreeNode) -> bool:if not root:return Falsestack = list()pre = Nonewhile root or stack:while root:stack.append(root)root = root.leftroot = stack.pop()if pre and root.val<=pre.val:return Falsepre = rootroot = root.rightreturn True
Recursion
在纸上画一画,理解一下这个preNode的含义,出现的位置,preNode是如何保证整个左子树小于root,整个右子树都大于root的。

若有收获,就点个赞吧
0 人点赞
