146. LRU 缓存机制
https://leetcode-cn.com/problems/lru-cache/
关键点在于每次的挪动,删除,增加的操作要记得同时更新哈希表和链表
LRU:
- key-value的保存,O(1) search, then HashMap - > key-ListNode(value)
- Double LinkedList, first in will be put in the front
- add a node at the end ( the latest used one and new coming)
- delete a node from the front ( full capacity)
- move a random node at the end ( refresh a node)
What do we need?
- class LinkedList - > key, value, next, prev
- a HashMap -> key - ListNode(key,value)
- def get - > if not in HashMap, return -1, if in HashMap, (1) refresh the corresponding key’s value in the HashMap (2) move the key to the tail of LinkedList, at the end return the value
- def put ->
if in HashMap -> move it to the tail of LinkedList,
if not in HashMap -> if capacity full, remove head.next from HashMap and remove head.next from LinkedList, then add the new one to HashMap, add the new one to the tail of LinkedList ```python class ListNode: def init(self,key=None, val=None):self.key=keyself.val=valself.next = Noneself.prev = None
class LRUCache:
def __init__(self, capacity: int):self.HashMap = {}self.capacity = capacityself.head = ListNode()self.tail = ListNode()self.head.next, self.tail.prev = self.tail, self.headdef move_to_tail(self, key):# 从自己所在位置拿出来node = self.HashMap[key]node.prev.next = node.nextnode.next.prev = node.prev# 放到tail之前self.add_to_tail(node)def remove_from_head(self):# delete from HashMap# 链表里存了key就为了这个时候反向定位,从hashmap弹出self.HashMap.pop(self.head.next.key)# delete from the LinkListself.head.next = self.head.next.nextself.head.next.prev = self.headdef add_to_tail(self, node):# node 的前后node.prev = self.tail.prevnode.next = self.tail# assign node to its prev's next and next's prevself.tail.prev.next = nodeself.tail.prev = nodedef get(self, key: int) -> int:if key not in self.HashMap:return -1else:self.move_to_tail(key)return self.HashMap[key].valdef put(self, key: int, value: int) -> None:if key in self.HashMap:self.HashMap[key].val = value # update HashMapself.move_to_tail(key) # update the LinkedListelse:if len(self.HashMap)==self.capacity: # check capacityself.remove_from_head()newNode = ListNode(key,value)self.HashMap[key]=newNodeself.add_to_tail(newNode)
<a name="5CKDu"></a>#### [716. 最大栈](https://leetcode-cn.com/problems/max-stack/)[https://leetcode-cn.com/problems/max-stack/](https://leetcode-cn.com/problems/max-stack/)<br />两个栈解决,time complexity O(n)<br />每次两个栈都压入,区别是max_stack是用来存放当前stack里最大value的,如果push的value大于max_stack[-1],那么压入value, 如果小于,那么把max_stack[-1]再压入一次```pythonclass MaxStack:def __init__(self):"""initialize your data structure here."""self.stack = []self.max_stack = []def push(self, x: int) -> None:self.stack.append(x)if not self.max_stack:self.max_stack.append(x)else:self.max_stack.append(max(self.max_stack[-1],x))def pop(self) -> int:if self.stack:self.max_stack.pop()return self.stack.pop()else:return -1def top(self) -> int:return self.stack[-1]def peekMax(self) -> int:return self.max_stack[-1]def popMax(self) -> int:tmp = []while self.stack and self.stack[-1]!=self.max_stack[-1]:tmp.append(self.stack.pop())self.max_stack.pop()res = self.stack.pop()self.max_stack.pop()while tmp:self.push(tmp.pop())return res
难点在于popMax(), O(logN)需要用到二叉搜索树+双向链表
实现哈希表
https://leetcode-cn.com/problems/design-hashmap/
class LinkedNode:def __init__(self, key=0,val=0, next=None):self.key = keyself.val = valself.next = nextclass HashMap:def __init__(self):self.capacity = 1<<3self.loader_factor = 0.75self.arr = [None]*self.capacityself.count = 0def reset(self):self.capacity = self.capacity << 1self.tmp_arr = self.arr[:]self.arr = [None]*self.capacityfor node in self.tmp_arr:while node:self.put(node.key, node.value)node = node.nextdef get(self,key):hash_key = self.get_hash_key(key)if self.arr[hash_key]:head = self.arr[hash_key]while head:if head.key == key:return head.valhead = head.next# if not findreturndef get_hash_key(self, key):return key & (self.capacity -1)def put(self,key,value):if self.count > self.capacity*self.loader_factor:self.reset()hash_key = self.get_hash_key(key)if not self.arr[hash_key]:self.arr[hash_key] = LinkedNode(key=key,val=value)self.count+=1else:head = self.arr[hash_key]while head:if head.key == key:head.val = valuebreakif not head.next:head.next = LinkedNode(key=key,val=value)self.count+=1head = head.next
实现堆排序
- 堆排序是利用 堆进行排序的
- 堆是一种完全二叉树
- 堆有两种类型: 大根堆 小根堆
- 两种类型的概念如下:
大根堆:每个结点的值都大于或等于左右孩子结点
小根堆:每个结点的值都小于或等于左右孩子结点
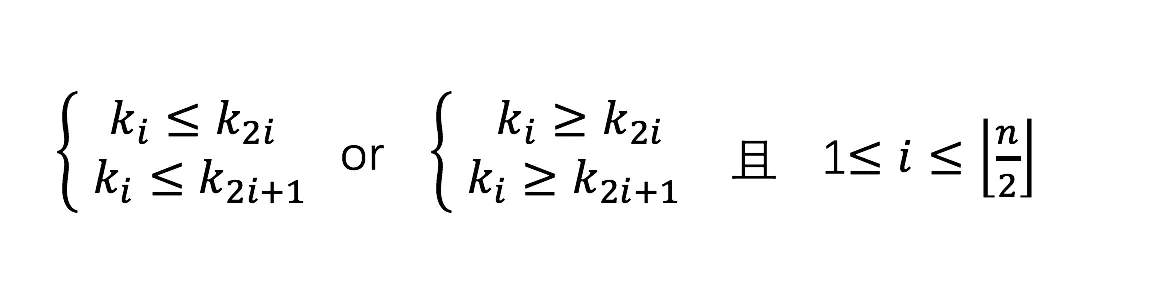
Find the maximum element and place the maximum element at the end.
a binary heap is a complete binary tree.
- build a max heap from the input data
- at this point, the largest item is stored at the root of the heap, replace it with the last item of the heap followed by reducing the size of heap by 1. finally heapify the root of the tree.
repeat step 2 while size of heap is greater than 1.
import timedef heapify(arr,n, i):largest = il = i*2 + 1r = i*2 + 2if l < n and arr[largest] < arr[l]:largest = lif r < n and arr[largest] < arr[r]:largest = rif largest!=i:arr[largest], arr[i] = arr[i], arr[largest]heapify(arr,n,largest)def heapSort(arr):n = len(arr)for i in range(n//2-1, -1, -1):heapify(arr, n, i)for i in range(n-1, 0,-1):arr[i], arr[0] = arr[0], arr[i]# heapify until i, because the rest have been sorted and removed from the heapheapify(arr,i,0)return arr

若有收获,就点个赞吧
0 人点赞
