经过上面两篇讲解,我们应该明白了Java中函数式编程的实现方式,其实很简单,只要理解Lambda表达式和函数式接口以及它俩之间的关系即可。但是我们能用它来做什么?难道只能像下面这样来简化代码吗?
public static void main(String[] args) {Thread thread = new Thread(() -> System.out.println(Thread.currentThread().getName()));thread.start();}
那么意义就不是很大了。函数式接口,当然要函数式编程。实际上,Java 8 对java的集合类库的API进行了改进,同时引进了很重要的Stream。这使得我们可以站在更高的层次上使用函数式编程对集合进行操作。这篇文章我们就来看Stream的使用。
创建Stream
创建Stream的方法很多,不仅它本身提供了创建Stream的方法,数组以及集合的API,也增加了返回Stream的方法,我们这里先看Stream自身提供的方法:
public static<T> Stream<T> of(T t) {return StreamSupport.stream(new Streams.StreamBuilderImpl<>(t), false);}
@SafeVarargs@SuppressWarnings("varargs") // Creating a stream from an array is safepublic static<T> Stream<T> of(T... values) {return Arrays.stream(values);}
这两个都是静态方法第一个方法返回一个只包括一个元素的Stream,第二个方法返回可变数组中所有的元素的的Stream。可以看到第二个方法实际上是调用了Arrays. stream方法来实现的。我们用第二种方法创建一个Stream:
public static void main(String[] args) {Stream<String> stringStream = Stream.of("one","two","three","four","five");long count = stringStream.count();System.out.println(count);}
count方法可以返回Stream中元素的数量。这样我们就创建了一个元素类型是String的Stream。
后面我们会详细讲解其他创建Stream的方式。
有了Stream之后我们就可以调用它的方法来对集合进行操作了。可以看一下下图,Stream的大多数方法的参数都是函数式接口,也就是说,我们可以使用Lambda表达式作为它的方法参数来完成方法调用。
对元素进行过滤
filter方法用来对Stream中的元素进行筛选,它的参数是一个函数式接口Predicate:
Stream<T> filter(Predicate<? super T> predicate);
筛选,肯定要对某个条件进行判断,所以Predicate的抽象方法应该需要返回boolean类型,我们来看下: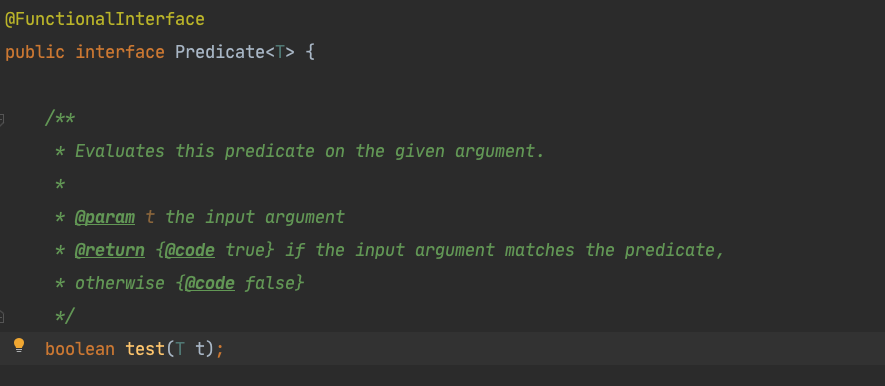
test方法即Predicate的抽象方法,果然返回的是boolean。那么我们就知道怎么用了,我们只需要给出test方法的实现就行了。
下面我们测试一下:
public static void main(String[] args) {Stream<String> stringStream = Stream.of("one","two","three","four","five");Stream<String> result = stringStream.filter(s -> s.length() == 3);System.out.println(result.count());}
我们给定的predicate是 s -> s.length() == 3这个lambda表达式,即过滤长度是3的元素,输出: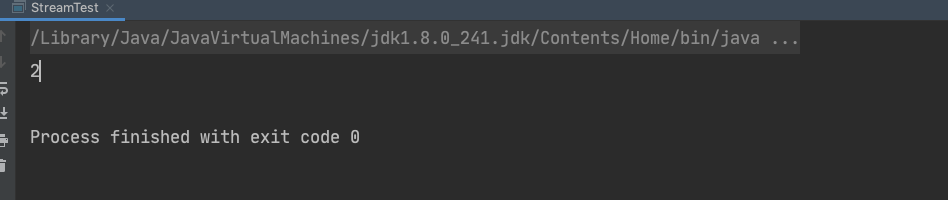
对元素进行转换
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
从方法的定义来看,Stream中的元素类型本来是T,返回值的Stream的元素类型是R,所以这个方法用来对Stream中的元素进行变换,这个方法的参数也是一个函数式接口,我们来看它的抽象方法: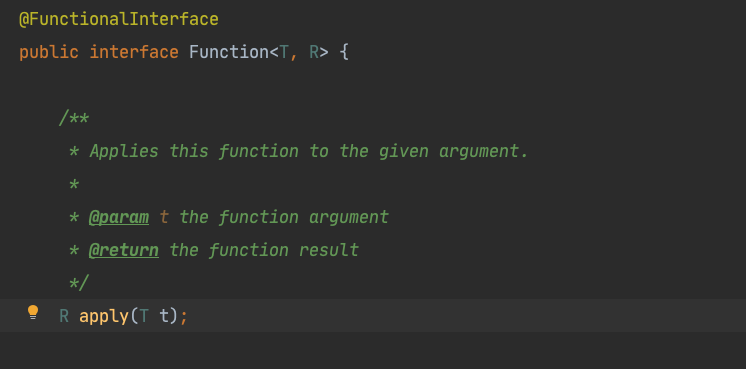
是这个apply方法,它接收T类型作为参数,返回R类型作为结果。我们来测试一下:
public static void main(String[] args) {Stream<String> stringStream = Stream.of("one","two","three","four","five");Stream<Integer> integerStream = stringStream.map(s -> s.length());System.out.println(Arrays.toString(integerStream.toArray()));}
我们用lambda表达式s->s.length()来作为Function接口,将原Stream中的每个元素转换为它的长度,即int类型看输出:
[3, 3, 5, 4, 4]
flatMap方法
这个方法就复杂点,我们看它的声明:
<R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper);
与map方法一样,它也接收一个Function函数接口作为参数,但是apply方法的参数是Stream
public static void main(String[] args) throws IOException {Stream<String> lines = Stream.of("this;is;string;one","this;is;string;two","this;is;string;three");Stream<String> stringStream = lines.flatMap(s -> Arrays.stream(s.split(";")));System.out.println(Arrays.toString(stringStream.toArray()));}
这个例子里,我们把lines的每个String类型的元素通过分号分隔获取一个string数组,然后将这个数组转换为一个Stream,看输出:
[this, is, string, one, this, is, string, two, this, is, string, three]
排序
Stream提供了两个sort方法来对Stream中的元素进行排序:
Stream<T> sorted();Stream<T> sorted(Comparator<? super T> comparator);
第一个方法没有参数,它默认为Stream中的元素T已经实现了Comparator,如果没有实现Comparator,就会抛出java.lang.ClassCastException异常。
第二个方法会使用一个Comparator作为参数,这也是一个函数式接口,它的抽象方法是
int compare(T o1, T o2);
所以我们只需要给出compare方法的实现即可,我们来测试一下:
public static void main(String[] args) throws IOException {Stream<Integer> integerStream = Stream.of(1,2,3,-1,9,6,7);Stream<Integer> result = integerStream.sorted((i1,i2) -> i1-i2);System.out.println(Arrays.toString(result.toArray()));}
输出:
[-1, 1, 2, 3, 6, 7, 9]
使用peek方法来增加额外操作
我们可以使用peek方法对Stream中的每个元素执行一个额外的操作,我们来看它的声明:
Stream<T> peek(Consumer<? super T> action);
它的参数是函数式接口Consumer,我们来看它的抽象方法:
这个方法没有返回值,它的含义就是对参数t执行方法体中的逻辑,我们来测试一下:
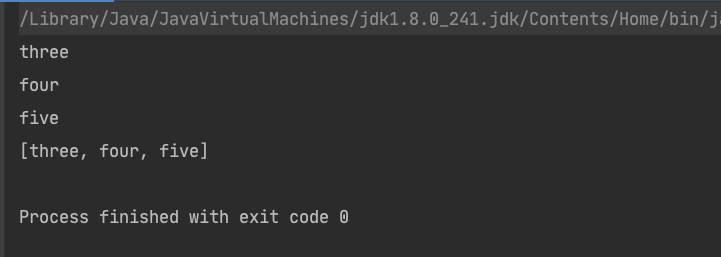
public static void main(String[] args) throws IOException {Stream<String> stringStream = Stream.of("one","two","three","four","five");stringStream = stringStream.filter(s -> s.length()>3).peek(s -> System.out.println(s));System.out.println(Arrays.toString(stringStream.toArray()));}
reduce方法
Stream提供了三个reduce方法:
T reduce(T identity, BinaryOperator<T> accumulator);Optional<T> reduce(BinaryOperator<T> accumulator);<U> U reduce(U identity,BiFunction<U, ? super T, U> accumulator,BinaryOperator<U> combiner);
reduce方法解释起来比较困难,我们先来看一个例子来看它能做什么:
public static void main(String[] args) throws IOException {Stream<Integer> integerStream = Stream.of(1, 2, 3, 4, 5, 6);Integer result = integerStream.reduce(100, (i1, i2) -> i1 + i2);System.out.println(result);}
输出结果:
这里是第一个方法的例子,从例子运行的结果来看,它像是在第一个参数的基础上,加上Stream中的每个元素,最后得到一个结果。
我们来分析它的参数,两个参数,第一个是Stream中元素类型的参数identity,第二个是一个BinaryOperator函数式接口,我们首先看BinaryOperator:
public interface BinaryOperator<T> extends BiFunction<T,T,T> {}
它继承了BiFunction这个接口,
public interface BiFunction<T, U, R>
它是将BiFunction中的三个泛型参数T,U和R都使用了同一类型。
抽象接口在这个接口里面:
/*** Applies this function to the given arguments.** @param t the first function argument* @param u the second function argument* @return the function result*/R apply(T t, U u);
这个方法接收一个T和一个U,返回一个R,那么对于BinaryOperator来说,就是接收两个T,返回一个T了,所以使用BinaryOperator,只需要给出apply方法的实现,也就是给出从两个T返回一个T的逻辑。
再回到我们开始的示例,我们是这样给出实现的:
(i1, i2) -> i1 + i2
也就是两个Integer相加返回一个Integer。
这样我们就理解了BinaryOperator,再回到整个reduce的逻辑,它的含义实际上是这样的:
T result = identity;for (T element : this stream)result = accumulator.apply(result, element)return result;
这样你应该就能明白了。
第二个方法与第一个方法的逻辑大致相同,我们就不详细讲解了。可以看出,这两个方法最后的返回类型都是T(或者Optional
<U> U reduce(U identity,BiFunction<U, ? super T, U> accumulator,BinaryOperator<U> combiner);
这个方法相对就比较复杂了,先看它的返回值和identity,都是U类型,不再是T类型了。我们来看一个例子:
public static void main(String[] args) throws IOException {Stream<String> stringStream = Stream.of("one","two","three");Integer result = stringStream.reduce(99, (i, s) -> i + s.length(), ((i1, i2) -> i1 + i2));System.out.println(result);}
我们通过(i,s) -> i + s.length()这个BiFunction实现了map的作用,即将String类型转换为Integer类型,同时也有reduce作用,那么实际上后面的combiner是没有用的,我直接用这个accmulator就能达到目的。实际上combiner会在并行计算中用到,这里就不再过多展开了。
min和max
min和max方法用来找出Stream中元素的最大值和最小值。
Optional<T> min(Comparator<? super T> comparator);Optional<T> max(Comparator<? super T> comparator);
它们的参数类型都是Comparator,用来对元素进行对比。我们直接来看例子:
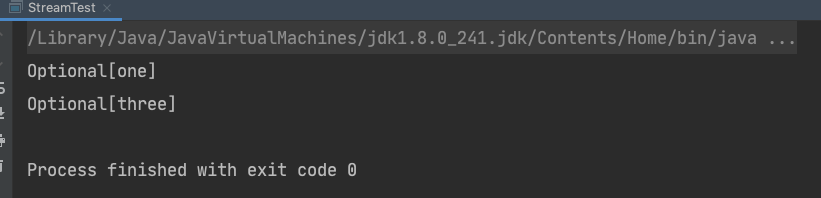
public static void main(String[] args) throws IOException {Stream<String> stringStream1 = Stream.of("one","two","three");Optional<String> min = stringStream1.min((s1, s2) -> s1.length() - s2.length());Stream<String> stringStream2 = Stream.of("one","two","three");Optional<String> max = stringStream2.max((s1, s2) -> s1.length() - s2.length());System.out.println(min);System.out.println(max);}
match类方法
match类方法用来对Stream中的元素进行条件匹配,有三个方法:
boolean anyMatch(Predicate<? super T> predicate);boolean allMatch(Predicate<? super T> predicate);boolean noneMatch(Predicate<? super T> predicate);
从名称可以大致看出每个方法的含义,第一个判断是否有任意一个匹配的,第二个判断是否全部匹配,第三个判断是否没有匹配。它们的参数都是Predicate。
public static void main(String[] args) throws IOException {Stream<String> stringStream1 = Stream.of("one","two","three");Stream<String> stringStream2 = Stream.of("one","two","three");Stream<String> stringStream3 = Stream.of("one","two","three");System.out.println(stringStream1.anyMatch(s -> s.length()==3));System.out.println(stringStream2.allMatch(s -> s.length()>=3));System.out.println(stringStream3.noneMatch(s -> s.length()==5));}

find类方法
find类方法用来对Stream中的元素进行查找:
Optional<T> findFirst();Optional<T> findAny();
从名字上也大概能理解它们的含义:第一查找Stream中的第一个元素,第二个方法查找Stream中的任意元素。这里就不再给出例子了。

若有收获,就点个赞吧
0 人点赞
