引言
上一篇文章我们讲解了String的不同创建方式,每种创建方式背后隐藏的机制以及字符串常量池等内容。实际上,在java文件中创建的字符串对象可能会被编译器默认优化,这篇文章就讲一下哪些情况下编译器会做出优化以及会做出哪些优化。
使用字符串常量表达式的方式
还记得在上一篇文章中,我们在介绍字符串字面量方式创建字符串时,提到过一个常量表达式的概念吗?不仅字符串字面常量被通过String.intern()方法限定了,更一般的情况是,表示常量表达式的值的字符串,就是被限定的。我们这里介绍一下字符串常量表达式。
常量表达式
《java语言规范》中对常量表达式的定义如下:常量表达式是表示简单类型值或String对象的表达式,它不会猝然结束,并且只由下面的成分构成:
- 简单类型的字面常量和String类型的字面常量。
- 到简单类型的强制类型转换和到String类型的强制类型转换。
- 一元操作符+、-、~和!(但不包括++和—)
- 乘除操作符*、/和%。
- 加减操作符+和-。
- 移位操作符<<、>>和>>>。
- 关系操作符<、<=、>和>=。
- 判等操作符==和!=。
- 按位操作符&、^和|。
- 条件与操作符&&和条件或操作符||。
- 三元条件操作符?:。
- 带括号的表达式,其包含的表达式是常量表达式。
- 引用常量变量的简单名。
- 引用常量变量的TypeName.Identifier形式的限定名。
其中,涉及到字符串的常量表达式有两种是比较重要的:
最简单的字符串字面常量String a = “abc”;
将多个字符串字面常量通过+操作符连接形成的常量表达式:String abc = “a” + “b” + “c”;
前者我们在上一篇文章中已经介绍过,这里重点讲第二种:
一元操作符+产生的常量表达式
当使用一元操作符+来连接字符串字面量时,会发生什么?
public static void main(String[] args) {String s = "abc" + "bcd";}
因为abc和bcd都是字符串字面常量,这两个会不会生成各自的字符串对象?然后再生成一个abcbcd的字符串对象呢?这个可以通过main方法的字节码来找到答案:
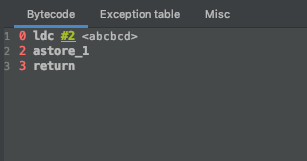
可以看到,第一个字节码是ldc,而参数是CONSTANT_String_info的常量,该常量指向的CONSTANT_utf8_info的值是abcbcd,并且整个常量池中没有代表abc或者bcd的常量,说明编译器对这个常量表达式进行了优化,直接用abcbcd替换掉了。所以最终的结果是在堆上创建一个字符串对象,这个字符串的内容为abcbcd,然后字符串常量池中有一个到该对象的引用,栈上的s同样是该引用。
也可以通过jad来生成反编译后的代码,这样看的更清楚:
public class StringCases{public StringCases(){}public static void main(String args[]){String s = "abcbcd";}}
我们的代码直接被替换成了 String s = “abc”。
这是编译器对使用+操作符形成的字符串常量表达式的优化。
使用非常量表达式的方式
简单的new表达式
String s = new String(“abc”);这种就是最简单的new关键字创建方式,这种方式的运行机制我们在上一篇文章也描述过了,这里不再赘述。
带有一元操作符+的非常量表达式
只要一元操作符+连接的不都是常量表达式,那么整个表达式就不能看做是一个常量表达式:
首先,看下面的例子:
public static void main(String[] args) {String s = new String("abc") + new String("bcd");}
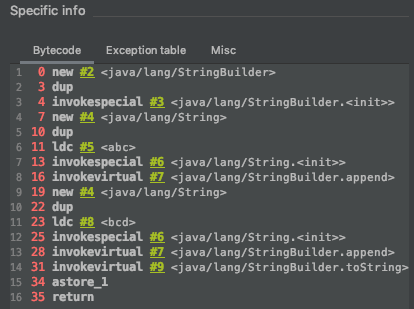
这个需要从字节码开始分析:
首先,我们看到先是执行了new指令,这个指令用来创建一个对象,参数是指向一个类的符号引用在常量池的索引值。一个此类的新实例会被分配在GC堆中,并且它所有的实例变量都初始化为相应类型的初始值。一个代表该对象实例的reference类型数据objectref将入栈到操作数栈中。
这里就是在堆上创建了一个StringBuilder的对象,但是实例变量都为相应类型的初始值,然后执行invokespecial指令来调用StringBuilder的构造方法,这里的构造方法是
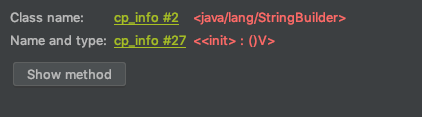
反映到StringBuilder的代码上是下面的:
/*** Constructs a string builder with no characters in it and an* initial capacity of 16 characters.*/public StringBuilder() {super(16);}
所以,这里的StringBuilder是创建的第一个对象。然后,由于abc是字面值常量,所以会在堆上创建一个字符串对象,并且字符串常量池中会有一个到这个字符串的引用,这个字符串对象在字节码中没有表现出来,实际上是编译器期进行的,而后面的7-13行才是new String(“abc”)的字节码表示,这里又在堆上创建了一个字符串对象,只是这个字符串的char[]引用指向的是前面创建的字符串对象的char[]。之后的16行调用StringBuilder的append方法来将abc拼接。后面对于bcd的操作与abc相同。最后的31行调用了StringBuilder的toString方法,这里又会创建一个新的String对象。所以个人猜测,这里创建了五个字符串对象:
StringBuilder的toString方法的实现如下:
@Overridepublic String toString() {// Create a copy, don't share the arrayreturn new String(value, 0, count);}
当然,使用jad反编译出来的代码,我们能看的更清楚:
public static void main(String args[]){String s = (new StringBuilder()).append(new String("abc")).append(new String("bcd")).toString();}
如果+连接的不是两个new关键字创建的字符串对象呢?看下面的例子:
public static void main(String[] args) {String s = "abc" + new String("bcd");}
还是看字节码: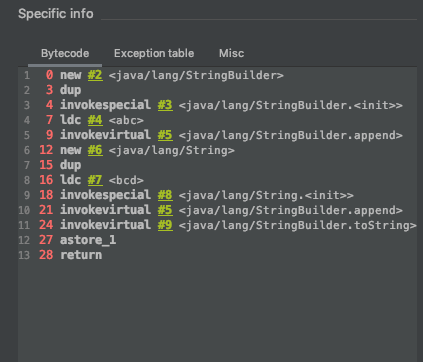
跟上一个相比,这里的主要区别在abc上面,对abc这个字面值常量,没有调用new字节码指令来创建对象,实际上在运行期之前,已经在堆上创建了这个字符串对象,并且字符串常量池中会有到这个字符串的引用。然后,+操作符同样被StringBuilder对象的append来替换掉了。
jad反编译后的代码如下:
public static void main(String args[]){String s = (new StringBuilder()).append("abc").append(new String("bcd")).toString();}
String源码中的注释中有这样的描述:
* String concatenation is implemented* through the {@code StringBuilder}(or {@code StringBuffer})* class and its {@code append} method.
String的拼接是使用StringBuilder或者StringBuffer的append方法来实现的,这与我们观察到的结果是一致的。
在循环中使用字符串拼接的问题
在循环中进行字符串拼接会有性能问题,我们来看一下编译器对循环字符串拼接的改动:
public static void main(String[] args) {String s = new String("hello,we have ");for(int i=0;i<1000;i++){s += " beautiful day " + i;}System.out.println(s);}
在这个例子中,我们在循环中使用+号对字符串进行拼接。我们看反编译后的代码:
public class StringConcatInLoop{public StringConcatInLoop(){}public static void main(String args[]){String s = new String("hello,we have ");for(int i = 0; i < 1000; i++)s = (new StringBuilder()).append(s).append(" beautiful day ").append(i).toString();System.out.println(s);}}
可以看到在循环体里面,每次都创建了一个新的StringBuilder对象,然后再调用append方法将先前的字符串拼接上。每次创建StringBuilder对象就会造成内存浪费。
为了解决这个问题,我们需要将StringBuilder拿到循环体外面,然后在循环体内显式调用append方法即可。
public static void main(String[] args) {StringBuilder stringBuilder = new StringBuilder("hello,we have ") ;for(int i=0;i<1000;i++){stringBuilder.append(" beautiful day ").append(i);}System.out.println(stringBuilder);}
小结
这篇文章,我们介绍了编译器对不同形式字符串的处理。其中,通过+操作符连接形成的常量表达式会直接被拼接后的字符串替换掉,非常量表达式的字符串的连接是通过StringBuilder的append方法来实现的。

若有收获,就点个赞吧
0 人点赞
