Go语言的并发通过goroutine实现。goroutine类似于线程,属于用户态的线程,我们可以根据需要创建成千上万个goroutine并发工作。goroutine是由Go语言的运行时(runtime)调度完成,而线程是由操作系统调度完成。
Go语言还提供channel在多个goroutine间进行通信。goroutine和channel是 Go 语言秉承的 CSP(Communicating Sequential Process)并发模式的重要实现基础。
主线程与协程
Go的主线程也可以理解为是进程,它可以起多个协程,而协程可以理解为是轻量级的线程。
主线程是一个物理线程,直接作用在CPU上,是重量级的,非常耗费资源。
协程是通过主线程开启的,是轻量级的线程,是逻辑态,是轻量级的,对资源消耗相对较少。
协程的主要特点有:
- 有自己独立的栈空间
- 共享程序的堆空间
- 协程由用户控制
- 协程是轻量级的线程
并发与并行
并发:同一时间段内同时执行多个任务;
并行:同一时刻同时执行多个任务;
并发的关键是具有处理多个任务的能力,并不要求要在同一时刻进行。并行的关键是同时具有处理多个任务处理的能力。
goroutine
在Go语言中,goroutine类似于线程,但是goroutine是由运行时runtime调度与管理。Go语言程序会智能的将goroutine中的任务合理的分配给每个CPU。
使用goroutine
在Go语言中使用goroutine只需要在调用函数的时候在前面加一个go关键字。如下:
func f1(){fmt.Println("Hello World")}func main(){go f1()}
一个goroutine必须对应一个函数,可以创建多个goroutine去执行相同的函数。如下:
func f1(){fmt.Println("Hello World")}func main(){go f1()go f1()}
上面介绍了启用goroutine的方法,下面通过一个例子来看启用goroutine与不启用goroutine执行程序所得的结果有什么不同。
先看如下代码:
package mainimport ("fmt")func hello(i int) {fmt.Println("hello", i)}func main() {for i := 0; i < 5; i++ {hello(i)}fmt.Println("hello")}
不执行代码,我们就可以知道这段代码的输出结果是顺序输出。如下:
hello 0hello 1hello 2hello 3hello 4hello
现在给调用hello()函数的时候加上goroutine,如下:
func main() {for i := 0; i < 5; i++ {go hello(i)}fmt.Println("hello")}
其输出结果如下:
hello
为啥只输出了hello呢,我们函数调用里的输出哪去了呢?
在Go语言中,main()函数是作为程序的入口函数,在它启动的时候,Go程序会默认为其添加一个goroutine,main()函数执行完后整个程序就结束了,所以上面的代码输出hello后整个程序就结束了。而没有输出hello() 方法中的程序是由于goroutine启动是需要一点时间的,而main()函数结束的又太快了,导致hello()函数都还没有来得及打印整个程序就结束了。
我们可以对其加一个time.Sleep()方法让main()稍等片刻,如下:
func main() {for i := 0; i < 5; i++ {go hello(i)}fmt.Println("hello")time.Sleep(time.Second)}
其执行结果如下:
hello 3hello 1hello 4hello 2hellohello 0
多次执行上面的代码,会发现每次打印的顺序都不一致。这是因为每个goroutine是并发执行的,而goroutine的调度是随机的。
上面的例子是我们用循环来启动了多个goroutine,我们为了得到goroutine所调用函数的结果使用了time.Sleep()函数,这种方法不好之处在于对于复杂的函数我们并不知道它到底需要多久才能执行完成,如果我们把时间设置过长则影响性能,如果我们设置过断则影响应用,非常不好去判断这个点。在Go语言中对于并行操作有一个更优雅的退出方式,那就是使用sync包中的WaitGroup。如下:
package mainimport ("fmt""sync")// 并发func hello(i int) {defer wg.Done()fmt.Println("hello", i)}var wg sync.WaitGroupfunc main() {for i := 0; i < 5; i++ {wg.Add(1)go hello(i)}fmt.Println("hello")wg.Wait()}
sync.WaitGroup是一个结构体,它只有三个方法,分别是:Add()、Done()和Wait()。
Add():增加计数器Done():计数器减1操作Wait():只要计数器不为0则一致等待
goroutine和线程
OS线程(操作系统线程)一般都有固定的栈内存(通常为2MB),一个goroutine的栈在其生命周期开始时只有很小的栈(典型情况下2KB),goroutine的栈不是固定的,他可以按需增大和缩小,goroutine的栈大小限制可以达到1GB,虽然极少会用到这个大。所以在Go语言中一次创建十万左右的goroutine也是可以的。
goroutine调度
GPM是Go语言运行时(runtime)层面的实现,是go语言自己实现的一套调度系统。区别于操作系统调度OS线程。
- M:主线程,是一个物理线程,是Go运行时(runtime)对操作系统内核线程的虚拟, M与内核线程一般是一一映射的关系, 一个
groutine最终是要放到M上执行的; - P:协程需要的上下文环境,P会对自己管理的
goroutine队列做一些调度(比如把占用CPU时间较长的goroutine暂停、运行后续的goroutine等等)当自己的队列消费完了就去全局队列里取,如果全局队列里也消费完了会去其他P的队列里抢任务 - G:协程,就是
goroutine,里面除了存放本goroutine信息外 还有与所在P的绑定等信息;
他们的关系如下图:
P与M一般也是一一对应的。他们关系是: P管理着一组G挂载在M上运行,如上图的G1和G2。当一个G长久阻塞在一个M上时,比如上图的G0处于阻塞状态,这时候runtime会新建一个M,上图中的M1,阻塞G0所在的P会把其他的G 挂载在新建的M1上去运行,上图中的G1和G2就会挂到新的M1上去执行,G0继续处于阻塞状态,当G0不阻塞了,M会被放到空间的主线程继续执行,同时G0会被唤醒,当G0执行完成或者认为其已经死掉时回收旧的M。
P的个数是通过runtime.GOMAXPROCS设定(最大256),Go1.5版本之后默认为物理线程数。 在并发量大的时候会增加一些P和M,但不会太多,切换太频繁的话得不偿失。
单从线程调度讲,Go语言相比起其他语言的优势在于OS线程是由OS内核来调度的,goroutine则是由Go运行时(runtime)自己的调度器调度的,这个调度器使用一个称为m:n调度的技术(复用/调度m个goroutine到n个OS线程)。 其一大特点是goroutine的调度是在用户态下完成的, 不涉及内核态与用户态之间的频繁切换,包括内存的分配与释放,都是在用户态维护着一块大的内存池, 不直接调用系统的malloc函数(除非内存池需要改变),成本比调度OS线程低很多。 另一方面充分利用了多核的硬件资源,近似的把若干goroutine均分在物理线程上, 再加上本身goroutine的超轻量,以上种种保证了go调度方面的性能。
GOMAXPROCS
Go运行时的调度器使用GOMAXPROCS参数来确定需要使用多少个OS线程来同时执行Go代码。默认值是机器上的CPU核心数。例如在一个8核心的机器上,调度器会把Go代码同时调度到8个OS线程上(GOMAXPROCS是m:n调度中的n)。
Go语言中可以通过runtime.GOMAXPROCS()函数设置当前程序并发时占用的CPU逻辑核心数。
Go1.5版本之前,默认使用的是单核心执行。Go1.5版本之后,默认使用全部的CPU逻辑核心数。
我们可以通过将任务分配到不同的CPU逻辑核心上实现并行的效果,这里举个例子:
func a() {for i := 1; i < 10; i++ {fmt.Println("A:", i)}}func b() {for i := 1; i < 10; i++ {fmt.Println("B:", i)}}func main() {runtime.GOMAXPROCS(1)go a()go b()time.Sleep(time.Second)}
两个任务只有一个逻辑核心,此时是做完一个任务再做另一个任务。 将逻辑核心数设为2,此时两个任务并行执行,代码如下。
func a() {for i := 1; i < 10; i++ {fmt.Println("A:", i)}}func b() {for i := 1; i < 10; i++ {fmt.Println("B:", i)}}func main() {runtime.GOMAXPROCS(2)go a()go b()time.Sleep(time.Second)}
Go语言中的操作系统线程和goroutine的关系:
- 一个操作系统线程对应用户态多个goroutine。
- go程序可以同时使用多个操作系统线程。
- goroutine和OS线程是多对多的关系,即m:n。
channel
单纯地将函数并发执行是没有意义的。函数与函数间需要交换数据才能体现并发执行函数的意义。
虽然可以使用共享内存进行数据交换,但是共享内存在不同的goroutine中容易发生竞态问题。
例子(我们使用goroutine来计算1-20的阶乘,并将结果保存到map中):
package mainimport ("fmt""sync")// 定义一个Map用来保存计算结果var retMap = make(map[int]int)var wg sync.WaitGroup// 计算阶乘的函数func test(n int) {defer wg.Done()ret := 1for i := 1; i <= n; i++ {ret *= i}// 保存结果retMap[n] = ret}func main() {for i := 1; i <= 20; i++ {wg.Add(1)go test(i)}wg.Wait()// 打印mapfor i, v := range retMap {fmt.Printf("retMap[%d]=%d\n", i, v)}}
我们直接运行上面的代码,会报并发写的错误,如下:
fatal error: concurrent map writesfatal error: concurrent map writes
我们在build的时候加上-race参数来查看其资源竞选情况:
go build -race .\main.go
然后运行可执行文件:
......retMap[75]=0retMap[89]=0retMap[92]=0retMap[98]=0retMap[184]=0Found 1 data race(s)
从输出可以看到有一个数据在进行资源竞选。
正常的解决思路是对内存进行加锁,不让其同时写,但是这样就会造成性能问题。如下:
package mainimport ("fmt""sync")// 定义一个Map用来保存计算结果var retMap = make(map[int]int)var wg sync.WaitGroup// 声明全局锁var lock sync.Mutex// 计算阶乘的函数func test(n int) {defer wg.Done()ret := 1for i := 1; i <= n; i++ {ret *= i}// 保存结果// 加锁lock.Lock()retMap[n] = retlock.Unlock()}func main() {for i := 1; i <= 20; i++ {wg.Add(1)go test(i)}wg.Wait()// 打印mapfor i, v := range retMap {fmt.Printf("retMap[%d]=%d\n", i, v)}}
我们通过加锁可以解决这种竞选的问题,但是这是内存级别的加锁,对性能有很大的影响。在Go语言中还可以使用channel来解决这种竞选问题,如果说goroutine是Go程序并发的执行体,channel就是它们之间的连接。channel是可以让一个goroutine发送特定值到另一个goroutine的通信机制。
Go 语言中的通道(channel)是一种特殊的类型。通道像一个传送带或者队列,总是遵循先入先出(First In First Out)的规则,保证收发数据的顺序。每一个通道都是一个具体类型的导管,也就是声明channel的时候需要为其指定元素类型。
Go语言的并发模型是
CSP(Communicating Sequential Processes),提倡通过通信共享内存而不是通过共享内存而实现通信。
创建channel
channel是一种类型,一种引用类型。声明通道类型的格式如下:
var 变量 chan 元素类型
举几个例子:
var ch1 chan int // 声明一个传递整型的通道var ch2 chan bool // 声明一个传递布尔型的通道var ch3 chan []int // 声明一个传递int切片的通道
声明了什么类型的channel,就只能往里面存放相应类型的数据。
通道是引用类型,通道类型的空值是nil。
var ch chan intfmt.Println(ch) // <nil>
声明的通道后需要使用make函数初始化之后才能使用。
创建channel的格式如下:
make(chan 元素类型, [缓冲大小])
channel的缓冲大小是可选的,如果确定了缓冲区大小,是固定的,并不会动态扩容。
举几个例子:
ch4 := make(chan int)ch5 := make(chan bool)ch6 := make(chan []int)
操作channel
通道有发送(send)、接收(receive)和关闭(close)三种操作。
发送和接收都使用<-符号。
现在我们先使用以下语句定义一个通道:
ch := make(chan int)
发送
将一个值发送到通道中。
ch <- 10 // 把10发送到ch中
接收
从一个通道中接收值。
x := <- ch // 从ch中接收值并赋值给变量x<-ch // 从ch中接收值,忽略结果
关闭
我们通过调用内置的close函数来关闭通道。
close(ch)
关于关闭通道需要注意的事情是,只有在通知接收方goroutine所有的数据都发送完毕的时候才需要关闭通道。通道是可以被垃圾回收机制回收的,它和关闭文件是不一样的,在结束操作之后关闭文件是必须要做的,但关闭通道不是必须的。
关闭后的通道有以下特点:
- 对一个关闭的通道再发送值就会导致panic。
- 对一个关闭的通道进行接收会一直获取值直到通道为空。
- 对一个关闭的并且没有值的通道执行接收操作会得到对应类型的零值。
- 关闭一个已经关闭的通道会导致panic。
channel操作的注意事项
- channel只能存放指定的数据类型
- channel的数据放满后,就不能再向里面存放数据,否则会抛出deadlock
- 如果从channel中取出数据后,则可以继续向里存放数据
- 在没有任何协程的情况下,如果channel里的数据取完了,再取就会报deadlock
无缓冲的channel
上面介绍过在用make初始化channel的时候可以指定缓冲区大小,也可以不指定。如果不指定其就为无缓冲区的channel。
如下:
package mainimport "fmt"func main() {// 声明一个无缓冲的channelch := make(chan int)// 向里面存放一个数据ch <- 10fmt.Println(ch)}
这时候我们运行代码会报如下错误:
fatal error: all goroutines are asleep - deadlock!
这是因为无缓冲的channel是没办法直接给它发送值的,必须要有地方接受channel的值才行。
如下我们开启一个goroutine来接受值。
package mainimport "fmt"func getRet(ch chan int) {ret := <-chfmt.Println(ret)}func main() {// 声明一个无缓冲的channelch := make(chan int)// 启动 一个goroutine去接受值go getRet(ch)// 向里面存放一个数据ch <- 10}
无缓冲通道上的发送操作会阻塞,直到另一个goroutine在该通道上执行接收操作,这时值才能发送成功,两个goroutine将继续执行。相反,如果接收操作先执行,接收方的goroutine将阻塞,直到另一个goroutine在该通道上发送一个值。
使用无缓冲通道进行通信将导致发送和接收的goroutine同步化。因此,无缓冲通道也被称为同步通道。
有缓冲channel
解决上面问题的方法还有一种就是使用有缓冲区的通道。我们可以在使用make函数初始化通道的时候为其指定通道的容量,例如:
func main() {ch := make(chan int, 1) // 创建一个容量为1的有缓冲区通道ch <- 10fmt.Println("发送成功")}
只要通道的容量大于零,那么该通道就是有缓冲的通道,通道的容量表示通道中能存放元素的数量。如果缓冲区满了则不能继续向里面存放数据,只有等别人从缓冲区取走数据后才能继续向里面存放数。
我们可以使用内置的len函数获取通道内元素的数量,使用cap函数获取通道的容量,虽然我们很少会这么做。
单向channel
有的时候我们会将通道作为参数在多个任务函数间传递,很多时候我们在不同的任务函数中使用通道都会对其进行限制,比如限制通道在函数中只能发送或只能接收。
Go语言中提供了单向通道来处理这种情况。
如下即为只能向channel里存数据:
package mainimport "fmt"func testChan(x chan<- int) {for i := 1; i < 3; i++ {x <- i}}func main() {// 声明一个channelch1 := make(chan int, 3)testChan(ch1)}
如果我们在testChan函数中加上如下代码读取channel
for i := range x {fmt.Println(i)}
则会抛出一下错误:
// invalid operation: range x (receive from send-only type chan<- int)
上面写的是只能向channel里写入数据,只能读取类似,代码如下:
package mainimport "fmt"func readChan(in <-chan int) {for i := range in {fmt.Println(i)}}func writeChan(in chan<- int) {for i := 1; i < 4; i++ {in <- i}close(in)}func main() {in := make(chan int, 3)go writeChan(in)readChan(in)}
其中:
chan<- int是一个只写单向通道(只能对其写入int类型值),可以对其执行发送操作但是不能执行接收操作;<-chan int是一个只读单向通道(只能从其读取int类型值),可以对其执行接收操作但是不能执行发送操作。
在函数传参及任何赋值操作中可以将双向通道转换为单向通道,但反过来是不可以的。
用for range 从channel取值
当向通道中发送完数据时,我们可以通过close函数来关闭通道。
当通道被关闭时,再往该通道发送值会引发panic,从该通道取值的操作会先取完通道中的值,再然后取到的值一直都是对应类型的零值。那如何判断一个通道是否被关闭了呢?
我们来看下面这个例子:
package mainimport "fmt"func main() {// 声明channelch1 := make(chan int, 10)ch2 := make(chan int, 10)// 启动goroutine向里写值go func() {for i := 0; i < 10; i++ {ch1 <- i}close(ch1)}()// 启动goroutine,取ch1存进ch2go func() {for {i, ok := <-ch1if !ok {fmt.Println("ch1中的数据已取完")break}ch2 <- i}close(ch2)}()// 输出ch2for i := range ch2 {fmt.Println(i)}}
从上面的例子中我们看到有两种方式在接收值的时候判断该通道是否被关闭,不过我们通常使用的是for range的方式。使用for range遍历通道,当通道被关闭的时候就会退出for range。
注意事项:
- 在遍历时,如果channel没有关闭,则会出现deadlock
- 在遍历时,如果channel已经关闭,则会正常遍历数据,遍历完后会自动关闭
接口类型的channel
使用接口类型的channel可以向里面存任何类型的数据,如下:
package mainimport "fmt"type cat struct {name stringage int}func main() {// 定义接口类型的channelallChan := make(chan interface{}, 5)allChan <- 10 // 向里面存Int类型的值allChan <- "hello" // 向里面存string类型的值newCat := cat{name: "咖啡猫", age: 80}allChan <- newCat // 向里面存结构体类型的值newSlice := []int{1, 2, 3}allChan <- newSlice // 向里面存切片类型的值newMap := map[string]int{"apple": 10,}allChan <- newMap // 向里面存map类型的值// 第一此取值ret1 := <-allChanfmt.Println("ret1:", ret1)// 第二次取值ret2 := <-allChanfmt.Println("ret2:", ret2)// 第三次取值ret3 := <-allChanfmt.Println("ret3:", ret3)// 第三次取值ret4 := <-allChanfmt.Println("ret4:", ret4)// 第五次取值ret5 := <-allChanfmt.Println("ret5:", ret5)}
其输出如下:
ret1: 10ret2: helloret3: {咖啡猫 80}ret4: [1 2 3]ret5: map[apple:10]
但是如果我们直接取结构体的某个键,可以直接取吗?如下:
package mainimport "fmt"type dog struct {name stringage int}func main() {aChan := make(chan interface{}, 1)d := dog{name: "小黑",age: 10,}aChan <- dret := <-aChanfmt.Println(ret.name)}
如果向上面这样直接取值则编译不过去,会panic,如下:
ret.name undefined (type interface {} is interface with no methods)
其意思就是说interface没有name这个方法。这是为什么呢?
因为从编译层面来说,编译器依然认为ret是一个interface类型,而不是struct类型,而且上面定义的interface是没有name这个字段的,所以编译会报错。
解决办法即为做类型断言,如下:
package mainimport "fmt"type dog struct {name stringage int}func main() {aChan := make(chan interface{}, 1)d := dog{name: "小黑",age: 10,}aChan <- dret := <-aChanret1 := ret.(dog)fmt.Println(ret1.name)}
channel总结
channel常见的异常总结,如下图: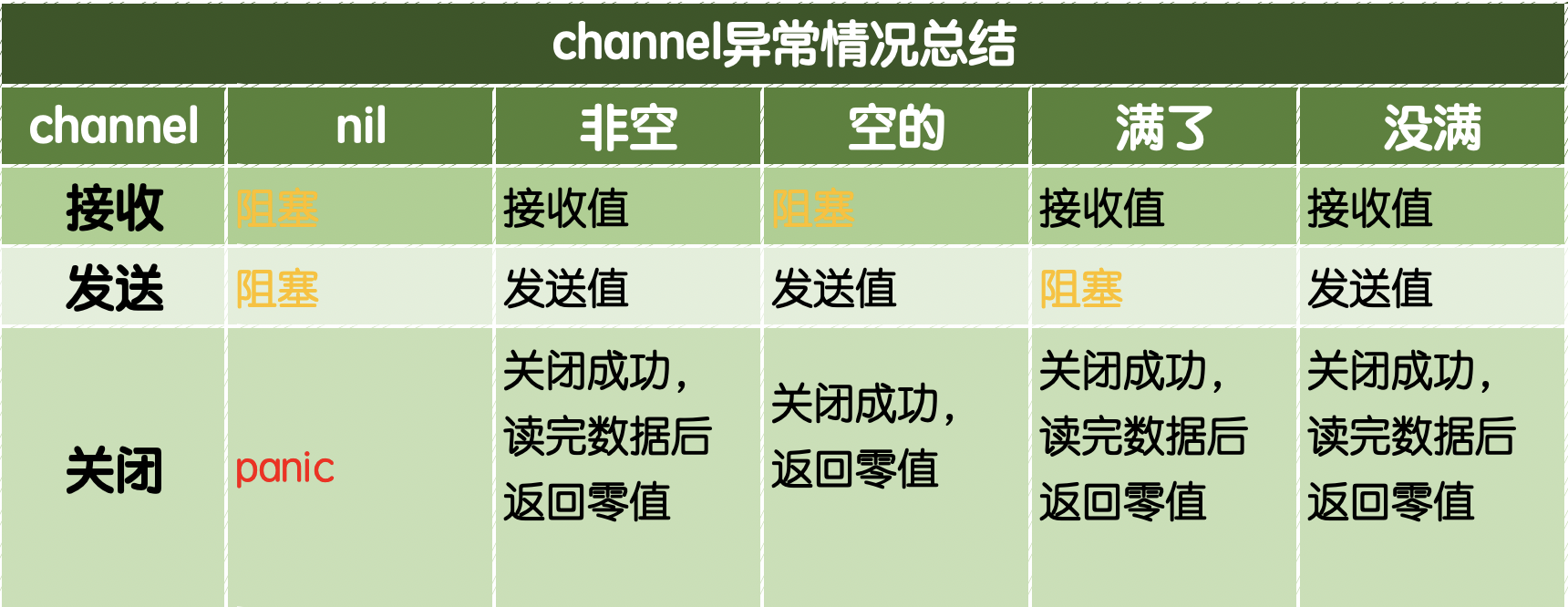
关闭已经关闭的channel也会引发panic。
select
如果我们需要从多个channel里读取数据,可以使用select,它的使用类似于switch语句,它有一系列case分支和一个默认的分支。每个case会对应一个通道的通信(接收或发送)过程。select会一直等待,直到某个case的通信操作完成时,就会执行case分支对应的语句。具体格式如下:
select{case <-ch1:...case data := <-ch2:...case ch3<-data:...default:默认操作}
l例子:
package mainimport ("fmt""sync")var wg sync.WaitGroupfunc insertData(ch1 chan int, num int) {for i := 0; i < num; i++ {ch1 <- i}defer wg.Done()}func main() {ch1 := make(chan int, 10)ch2 := make(chan int, 20)wg.Add(2)go insertData(ch1, 10)go insertData(ch2, 20)wg.Wait()// 循环取for {select {case v := <-ch1:fmt.Printf("从ch1取出数据,其值为:%d\n", v)case v := <-ch2:fmt.Printf("从ch2取出数据,其值为:%d\n", v)default:fmt.Printf("没有数据了\n")}}}
如果取完了就会一直打印default语句。
如果要退出可以使用如下方式:
(1)、用label标签
package mainimport ("fmt""sync")var wg sync.WaitGroupfunc insertData(ch1 chan int, num int) {for i := 0; i < num; i++ {ch1 <- i}defer wg.Done()}func main() {ch1 := make(chan int, 10)ch2 := make(chan int, 20)wg.Add(2)go insertData(ch1, 10)go insertData(ch2, 20)// 循环取wg.Wait()label:for {select {case v := <-ch1:fmt.Printf("从ch1取出数据,其值为:%d\n", v)case v := <-ch2:fmt.Printf("从ch2取出数据,其值为:%d\n", v)default:fmt.Printf("没有数据了\n")break label}}}
(2)、用return语句,用return会退出当前所在函数
package mainimport ("fmt""sync")var wg sync.WaitGroupfunc insertData(ch1 chan int, num int) {for i := 0; i < num; i++ {ch1 <- i}defer wg.Done()}func main() {ch1 := make(chan int, 10)ch2 := make(chan int, 20)wg.Add(2)go insertData(ch1, 10)go insertData(ch2, 20)// 循环取wg.Wait()for {select {case v := <-ch1:fmt.Printf("从ch1取出数据,其值为:%d\n", v)case v := <-ch2:fmt.Printf("从ch2取出数据,其值为:%d\n", v)default:fmt.Printf("没有数据了\n")return}}}
使用select语句能提高代码的可读性。
- 可处理一个或多个
channel的发送/接收操作。 - 如果多个
case同时满足,select会随机选择一个。 - 对于没有
case的select{}会一直等待,可用于阻塞main函数。
并发安全与锁
注:锁是一个结构体类型,当作为参数传递的时候须用指针类型
在使用goroutine的时候,如果多个goroutine同时对一个资源进行操作,可能会造成竞态问题。
比如:
package mainimport ("fmt""sync")var x = 0var wg sync.WaitGroupfunc add() {for i := 0; i < 50000; i++ {x++}wg.Done()}func main() {wg.Add(2)go add()go add()wg.Wait()fmt.Println(x)}
运行代码,结果如下:
PS E:\DEV\Go\src\code.rookieops.com\day07\14lock> go run .\main.go65768PS E:\DEV\Go\src\code.rookieops.com\day07\14lock> go run .\main.go69379
可以看到其输出的结果并不是我们想要的,这时候就可以引入锁机制。
互斥锁
互斥锁也叫排他锁。当使用这种的锁的时候,它能保证同时只有一个goroutine可以访问共享资源。
Go语言中使用sync.Mutex来实现互斥锁。
如下对上段代码进行重构:
package mainimport ("fmt""sync")var x = 0var wg sync.WaitGroupvar lock sync.Mutexfunc add() {for i := 0; i < 50000; i++ {lock.Lock()x++lock.Unlock()}wg.Done()}func main() {wg.Add(2)go add()go add()wg.Wait()fmt.Println(x)}
然后就能得到我们想要的结果。
读写互斥锁
在一种特殊场景下,比如新闻网站这种读多写少的场景下,用互斥锁的话就会很浪费性能,Go语言提供了一种读写互斥锁,是用sync.RWMutx来实现。
我们写两个对比示例:
(1)、用互斥锁来模拟这种场景
package mainimport ("fmt""sync""time")var (x = 0lock sync.Mutexwg sync.WaitGrouprwlock sync.RWMutex)func write() {defer wg.Done()lock.Lock()// rwlock.Lock()x++lock.Unlock()// rwlock.Unlock()}func read() {defer wg.Done()lock.Lock()// rwlock.RLock()fmt.Println(x)lock.Unlock()// rwlock.RUnlock()}func main() {start := time.Now()for i := 0; i < 10; i++ {wg.Add(1)go write()}for i := 0; i < 200; i++ {wg.Add(1)go read()}wg.Wait()fmt.Println(time.Now().Sub(start))}
输出的执行时间为:
156.5827ms
(2)、用读写互斥锁来模拟上面场景
package mainimport ("fmt""sync""time")var (x = 0lock sync.Mutexwg sync.WaitGrouprwlock sync.RWMutex)func write() {defer wg.Done()// lock.Lock()rwlock.Lock()x++// lock.Unlock()rwlock.Unlock()}func read() {defer wg.Done()// lock.Lock()rwlock.RLock()fmt.Println(x)// lock.Unlock()rwlock.RUnlock()}func main() {start := time.Now()for i := 0; i < 10; i++ {wg.Add(1)go write()}for i := 0; i < 200; i++ {wg.Add(1)go read()}wg.Wait()fmt.Println(time.Now().Sub(start))}
输出时间为:
91.7481ms
可以看到这两种的区别。
sync.Once
Go语言中的sync包中提供了一个针对只执行一次场景的解决方案–sync.Once。
sync.Once只有一个Do方法,其签名如下:
func (o *Once) Do(f func()) {}
备注:如果要执行的函数f需要传递参数就需要搭配闭包来使用。
示例1:使用sync.Once来关闭channel
package mainimport ("fmt""sync")var (once sync.Oncewg sync.WaitGroup)func test(ch1 chan int) {for i := 0; i < 10; i++ {ch1 <- i}once.Do(func() { defer close(ch1) })defer wg.Done()}func main() {wg.Add(1)ch1 := make(chan int, 10)go test(ch1)wg.Wait()for v := range ch1 {fmt.Println(v)}}
示例2:用sync.Once来加载配置文件示例
var icons map[string]image.Imagevar loadIconsOnce sync.Oncefunc loadIcons() {icons = map[string]image.Image{"left": loadIcon("left.png"),"up": loadIcon("up.png"),"right": loadIcon("right.png"),"down": loadIcon("down.png"),}}// Icon 是并发安全的func Icon(name string) image.Image {loadIconsOnce.Do(loadIcons)return icons[name]}
示例3:用sync.Once来实现并发安全的单例模式
package singletonimport ("sync")type singleton struct {}var instance *singletonvar once sync.Oncefunc GetInstance() *singleton {once.Do(func() {instance = &singleton{}})return instance}
sync.Once其实内部包含一个互斥锁和一个布尔值,互斥锁保证布尔值和数据的安全,而布尔值用来记录初始化是否完成。这样设计就能保证初始化操作的时候是并发安全的并且初始化操作也不会被执行多次。
sync.Map
如果要并发操作Map的话可以用sync.Map,它是一个开箱即用的Map,只用它的时候不需要再用make进行初始化了。sync.Map内置了一些常用方法,比如:Sotre、load、Delete、Range等。
示例:
package mainimport ("fmt""strconv""sync")var (m sync.Mapwg sync.WaitGroup)func main() {for i := 0; i < 20; i++ {wg.Add(1)go func(n int) {key := strconv.Itoa(n)// 存值m.Store(key, n)// 取值value, _ := m.Load(key)fmt.Printf("key: %s, value: %d\n", key, value)defer wg.Done()}(i)}wg.Wait()}
原子操作
代码中的加锁操作因为涉及内核态的上下文切换会比较耗时、代价比较高。针对基本数据类型我们还可以使用原子操作来保证并发安全,因为原子操作是Go语言提供的方法它在用户态就可以完成,因此性能比加锁操作更好。Go语言中原子操作由内置的标准库sync/atomic提供。
其操作有:
(1)、读取操作
func LoadInt32(addr *int32) (val int32)func LoadInt64(addr *int64) (val int64)func LoadUint32(addr *uint32) (val uint32)func LoadUint64(addr *uint64) (val uint64)func LoadUintptr(addr *uintptr) (val uintptr)func LoadPointer(addr *unsafe.Pointer) (val unsafe.Pointer)
(2)、写入操作
func StoreInt32(addr *int32, val int32)func StoreInt64(addr *int64, val int64)func StoreUint32(addr *uint32, val uint32)func StoreUint64(addr *uint64, val uint64)func StoreUintptr(addr *uintptr, val uintptr)func StorePointer(addr *unsafe.Pointer, val unsafe.Pointer)
(3)、修改操作
func AddInt32(addr *int32, delta int32) (new int32)func AddInt64(addr *int64, delta int64) (new int64)func AddUint32(addr *uint32, delta uint32) (new uint32)func AddUint64(addr *uint64, delta uint64) (new uint64)func AddUintptr(addr *uintptr, delta uintptr) (new uintptr)
(4)、交换操作
func SwapInt32(addr *int32, new int32) (old int32)func SwapInt64(addr *int64, new int64) (old int64)func SwapUint32(addr *uint32, new uint32) (old uint32)func SwapUint64(addr *uint64, new uint64) (old uint64)func SwapUintptr(addr *uintptr, new uintptr) (old uintptr)func SwapPointer(addr *unsafe.Pointer, new unsafe.Pointer) (old unsafe.Pointer)
(5)、比较并交换操作
func CompareAndSwapInt32(addr *int32, old, new int32) (swapped bool)func CompareAndSwapInt64(addr *int64, old, new int64) (swapped bool)func CompareAndSwapUint32(addr *uint32, old, new uint32) (swapped bool)func CompareAndSwapUint64(addr *uint64, old, new uint64) (swapped bool)func CompareAndSwapUintptr(addr *uintptr, old, new uintptr) (swapped bool)func CompareAndSwapPointer(addr *unsafe.Pointer, old, new unsafe.Pointer) (swapped bool)

若有收获,就点个赞吧
0 人点赞
