特性
- 可见性:volatile字段的写操作保证对所有线程可见
禁止指令重排序(汇编层面),volatile字段的单个读写操作是原子性的
Volatile演示
下面的代码主要用来演示下Volatile的作用,然后将volatile字段的读写以图示方式展现出来:
int a;int result;volatile boolean flag;public void init(){a = 1; //①flag = true; // ②}public void doTask(){if(flag){ // ③result = a; // ④}......}
A线程执行
init()方法- B线程执行
doTask()方法
(发现以前的图不能用,图还在路上…)
实现原理三层分析
字节码层
volatile 的字节码层,只是给对应的字段加上了 VOLATILE 的访问修释符:
JVM层
JVM层使用 storestore 、 storeload 、 loadload 、 loadstore 四种内存屏障指令,内存屏障戳这篇文章:《👀自顶向下 - 写缓冲区和无效化队列》。storestore 和 storeload 分别放在 volatile写 前后,其示意图如下所示:
storestore表示 该指令前的所有**store**操作均对后续的代码可见(也就是对volatile写可见)storeload表示 该指令前的所有**store**操作均对后续的代码可见
**loadload 和 loadstore 分别放在 volatile读 前后,其示意图如下所示:
loadload表示 该指令前的所有load操作要 先于 后面的load操作 完成loadstore表示 该指令前的所有load操作必须在后面的store操作之前完成
Tips: 这里说的load是将值从主内存中加载到副本中;store是将值从副本中刷新到主内存中
内存屏障指令分析
为了更好的知道JVM中的这四大内存屏障指令的操作,我找了一下 openjdk 里面的源码,找到了在 windows-x86 (戳链接,直接看Github)下的内存屏障指令实现:
#include <intrin.h>
// Compiler version last used for testing: Microsoft Visual Studio 2010
// Please update this information when this file changes
// Implementation of class OrderAccess.
// A compiler barrier, forcing the C++ compiler to invalidate all memory assumptions
inline void compiler_barrier() {
// C++头文件<intrih.h>提供的函数,主要作用放在后面的拓展里~
_ReadWriteBarrier();
}
inline void OrderAccess::loadload() { compiler_barrier(); }
inline void OrderAccess::storestore() { compiler_barrier(); }
inline void OrderAccess::loadstore() { compiler_barrier(); }
inline void OrderAccess::storeload() { fence(); }
inline void OrderAccess::acquire() { compiler_barrier(); }
inline void OrderAccess::release() { compiler_barrier(); }
// CPU级别(汇编级别)的内存屏障
inline void OrderAccess::fence() {
// x86级别的走这个方法
#ifdef AMD64
StubRoutines_fence();
// 其余的机器走lock addl 0, %esp(addl用于四个字节,dword是四字)
#else
__asm {
lock add dword ptr [esp], 0;
}
#endif // AMD64
compiler_barrier();
}
inline void OrderAccess::cross_modify_fence() {
int regs[4];
__cpuid(regs, 0);
}
#endif // OS_CPU_WINDOWS_X86_ORDERACCESS_WINDOWS_X86_HPP
由于作者功力有限,x86的 fence() 实现戳这里。就windowsx86来看,只有 storeload 才上CPU级内存屏障,并非任意情况下的 volatile 都上CPU级的内存屏障。
Volatile写举例分析
volatile写的指令序列示意图如下所示:
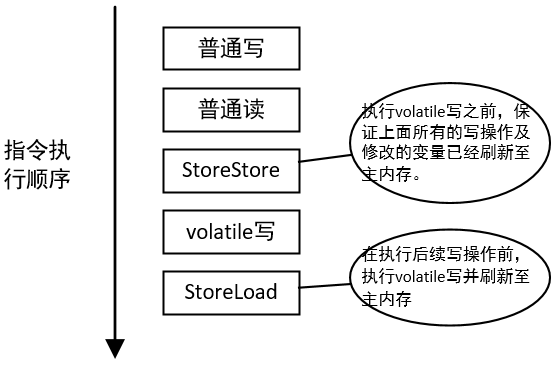
StoreStore 保证在执行volatile写前,所有写操作的处理已经刷新至内存,保证对其他线程可见了。而 StoreLoad 的作用是避免后面还有其他的volatile读/写操作发生重排序。由于JMM无法准确判断StoreLoad所处的环境(比如结尾是return),所以有两种选择:
- 在volatile读前加上StoreLoad
- 在volatile写后加上StoreLoad
但是因为StoreLoad相比其他内存屏障更加消耗性能,考虑更多场景下是少写多读,所以将StoreLoad加在volatile写后。
Volatile读举例分析
volatile读插入内存屏障的指令序列示意图如下所示:
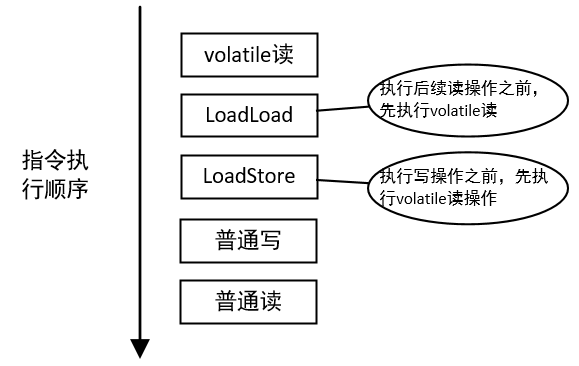
LoadLoad 保证先执行volatile读再执行后续的读操作(禁止volatile读和后续的读发生重排序),而后的 LoadStore 保证先执行volatile读再执行写操作(禁止volatile读和后续的写发生重排序)。两者联合起来就是无论如何volatile读必须和程序顺序保持一致。
CPU层
这一部分需要观察JVM输出的汇编代码,我们通过 hsdis 插件去获取JIT执行的汇编指令,这一部分的教程可以看这篇文章《工具篇——获取执行的汇编代码》
Volatile写测试
我现在拿这段程序进行测试:
public class VolatileApp {
static volatile boolean flag = false;
public static void main(String[] args) {
test();
}
public static void test(){
flag = false;
}
}
使用如下的 VMOption :
-server -Xcomp -XX:+UnlockDiagnosticVMOptions -XX:-Inline -XX:CompileCommand=print,*VolatileApp.test
最后的输出如下所示:
下面的这张是使用了 volatile 关键字的输出: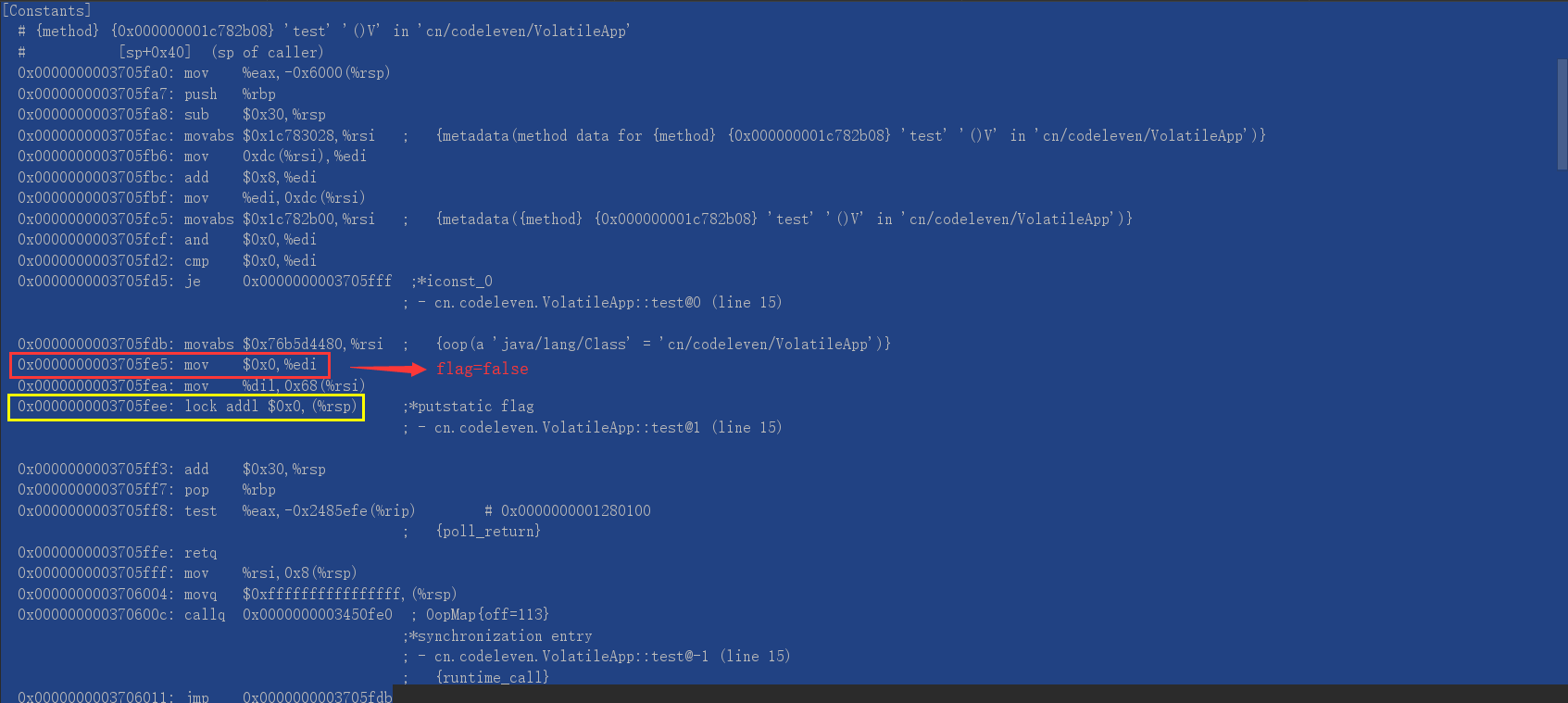
下面这张是没有使用 volatile 关键字的输出: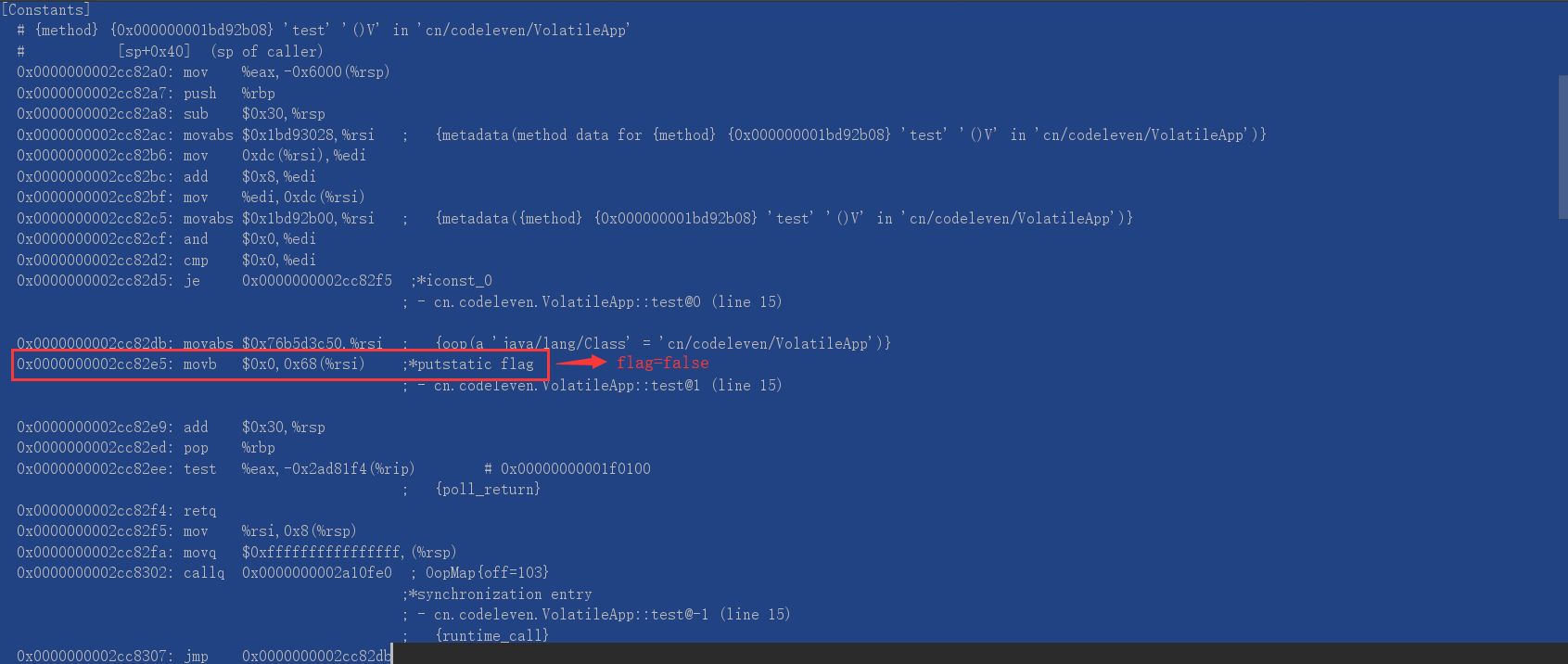
我们至少可以分析出在windowsx86上, volatile写 是通过加 lock addl $0x0, $(%rsp) 来做屏障的。而这个 lock 指令的作用如下所示:
The LOCK # signal is asserted during execution of the instruction following the lock prefix. This signal can be used in a multiprocessor system to ensure exclusive use of shared memory while LOCK # is asserted
lock用于在多处理器中执行指令时对共享内存的独占使用。它的副作用是能够将当前处理器对应缓存的内容刷新到内存,并使其他处理器对应的缓存失效。另外还提供了有序的指令无法越过这个内存屏障的作用。
大家可以看看这篇文章,了解一下 LOCK# 指令在底层做了哪些事情:《👀内存模型硬件篇 - LOCK#指令》
Volatile读测试
该测试所用的 VMOption 和 Volatile写测试 相同,其代码如下所示:
public class VolatileApp {
static boolean flag = false;
static int count = 0;
public static void main(String[] args) {
test();
}
public static void test(){
if(flag){
count = 12345;
}
}
}
汇编代码输出结果如下所示: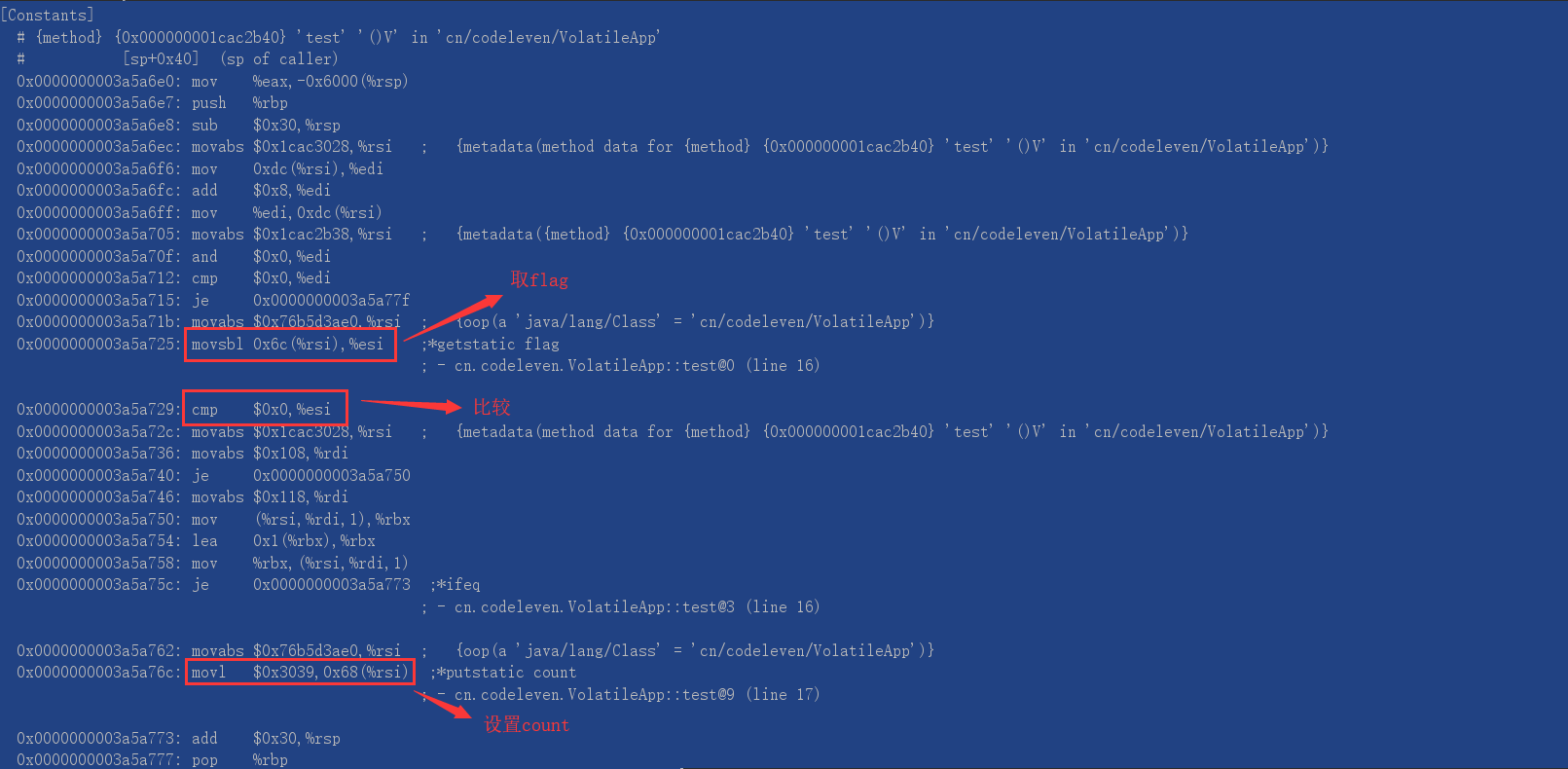
我们可以看到并没有任何CPU层面上的“锁”,所以对应着JVM层的分析,可以确认除了 StoreLoad 外,其他的指令只是 C++ 级别的禁止优化。
总结
volatile 在字节码层只是加了一个 ACC_VOLATILE 访问修饰符;JVM在执行时如果是 StoreLoad ,就会执行 CPU级别的 fence() ,即插入 LOCK# 指令;其他的指令是通过 C++ 的 _ReadWriteBarrier 实现的,主要就是调用该方法时,强制内存读取和写入在调用时完成。
Volatile优化
在实际执行过程中,只要不改变volatile写/读的内存语义,编译器可以根据实际情况省略不必要的屏障。
int a;
volatile int v1 = 1;
volatile int v2 = 2;
void readAndWrite(){
int i = v1;
int j = v2;
a = i + j;
v1 = i + 1;
v2 = j + 2;
}
针对readAndWrite()方法,编译器在生成字节码时会做如下优化。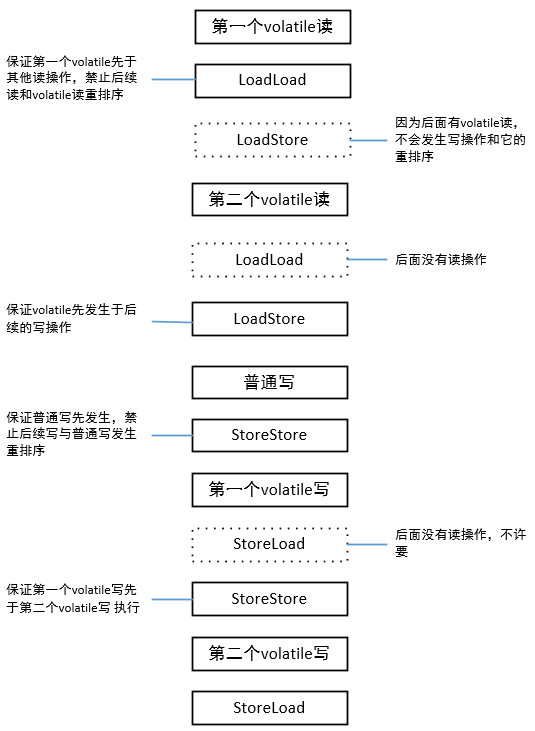
按顺序下来,第一个volatile读先于第二个volatile,第二个volatile先于所有后续的写,故第一个volatile读一定不会被重排序;StoreStore保证普通写先于第一个volatile写,StoreStore又保证第一个volatile写先于第二个volatile写,最后安全起见插入StoreLoad。
拓展
JSR-133为什么增强volatile的内存语义
在之前的版本,虽然不允许volatile变量间 的重排序,但是允许volatile和普通变量间的重排序。为了提供一种比锁更轻量级的线程间通信机制,专家组决定增强volatile的内存语义,严格限制volatile变量与普通变量的重排序,确保volatile的写-读和锁的释放-获取具有相同的内存语义。
由于volatile仅仅保证对单个volatile变量的读/写具有原子性,而锁的互斥执行的特性可以确保对整个临界区代码的执行具有原子性。在功能上,锁比volatile更强大;在可伸缩性和性能上,volatile更有优势。
具体看《Java理论与实践:正确使用volatile变量》
X86下阻止C++进行代码优化
在 Windows X86 里,内存屏障指令的实现有用到这样一行代码:
inline void compiler_barrier() {
_ReadWriteBarrier();
}
_ReadWriteBarrier() 来自于 <intrih.h> 头文件中,该函数的作用可以看文档——《_ReadWriteBarrier 》)。主要作用就是阻止C++编译器的部分优化。
Unsafe中对StoreLoad的优化putOrderedObject()
这个方法很有意思,乍一看命名是放一个有序的对象,但它是通过避免加上StoreLoad内存屏障来弥补volatile写的性能问题。这时可能会有朋友问,不加上volatile不会影响可见性吗?会影响可见性,但不会永远影响下去,最多就两三秒的延迟,就会将共享变量刷新至主内存。所以当延迟要求不高,性能要求高时,就可以采用这个方法(主要在Atmoic*类里面使用)。

若有收获,就点个赞吧
0 人点赞
