这章主要先描述计算机底层的一些做法和实现,这些做法和实现会引出为什么Java要这么做
存储器结构
在计算机体系里面,存储器的结构如下图所示(网上找的图):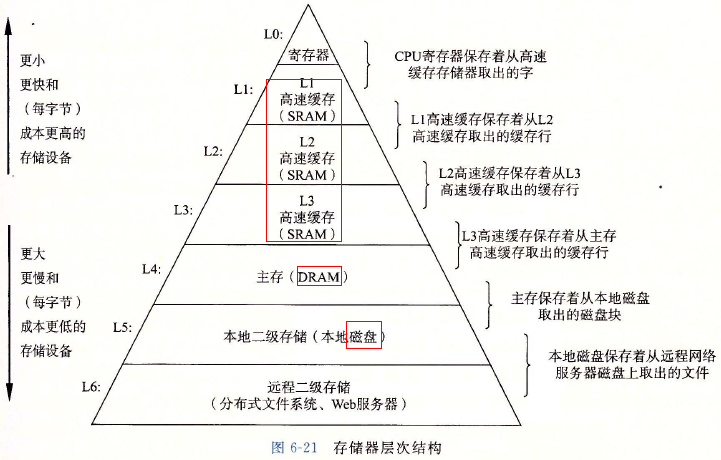
越往上速度越快但存储空间越小;越往下速度越慢但存储空间越大。在计算机体系中,能够很大程度影响我们程序运行速度的层次主要在 L1~L3 之间。我们看一下 i5 处理器的三级缓存结构: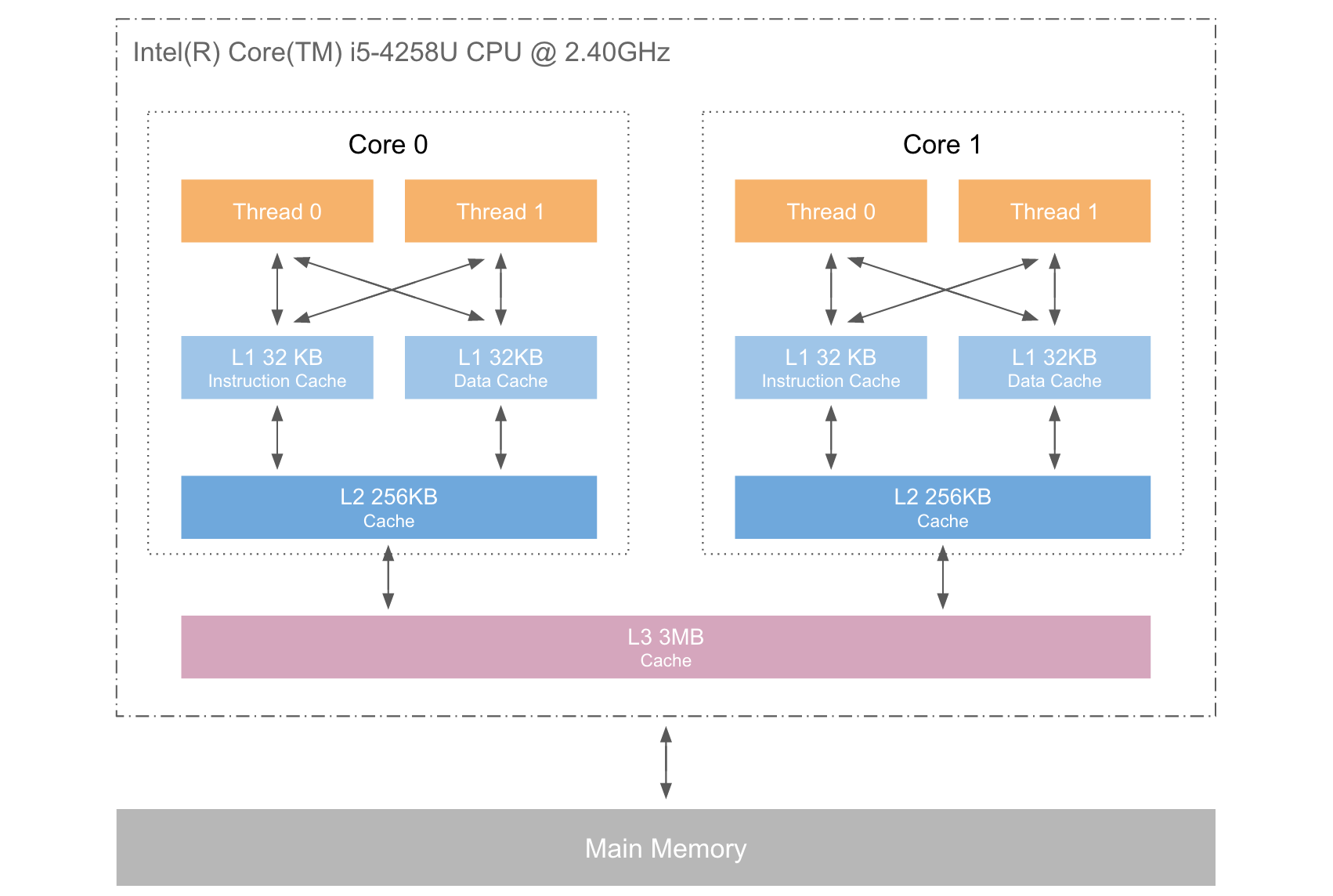
L1、L2、L3分别表示一级缓存、二级缓存、三级缓存。越靠近CPU的缓存,速度越快,容量也越小。L1缓存小但很快,并且紧靠着在使用它的CPU内核。分为指令缓存和数据缓存;L2大一些,也慢一些,并仍然只能被一个单独的CPU核使用;L3更大、更慢,并且被单个插槽上的所有CPU核共享;最后是主存,由全部插槽上的所有CPU核共享。
接下来将介绍和这三级缓存相关的概念和技术:
- 缓存行
- MESI概念
- 缓存行伪共享问题
- 合并写WriteCombiningBuffer
缓存行
缓存行 (Cache Line) 是 CPU缓存中的最小单位,CPU缓存由若干缓存行组成,一个缓存行的大小通常是 64 字节(这取决于 CPU)。每当CPU去读取缓存时,不是仅读取需要的部分而是把所在数据的一整行都取出来。
缓存MESI协议
该协议是用来保证多个CPU缓存中共享数据的一致性。该协议定义了四种状态,而CPU对缓存行的四种操作可能会产生不一致的状态,因此缓存控制器监听到本地操作和远程操作的时候,需要对地址一致的缓存行的状态进行一致性修改,从而保证数据在多个缓存之间保持一致性。
| 状态 | 描述 |
|---|---|
| M 修改 (Modified) | 该缓存行数据有效,仅当前核在使用,与主存中的数据不一致 |
| E 独享、互斥 (Exclusive) | 该缓存行有效,数据和内存中的数据一致,数据只存在于当前核中 |
| S 共享 (Shared) | 该缓存行有效,数据和内存中的数据一致,数据存在于很多核中。 |
| I 无效 (Invalid) | 该缓存行无效。 |
然后简单看一下协议的状态图: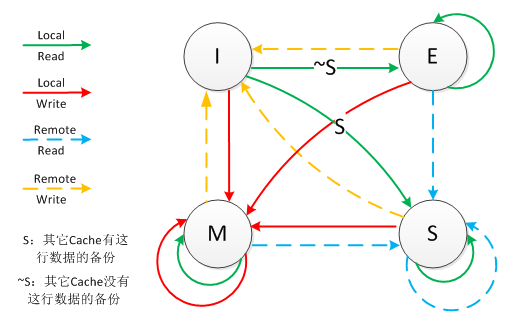
在上图中, Local Read表示读取本核Cache中的值,Local Write表示写本核Cache中的值,Remote Read表示读取其它核Cache中的值,Remote Write表示其它核写其自己的Cache中的值,箭头表示本Cache line状态的迁移,环形箭头表示状态不变。
为了帮助理解,这里列出了一张状态迁移表,帮助大家更好的理解:
| 当前状态 | 事件 | 行为 | 下一个状态 |
|---|---|---|---|
| Invalid | Local Read | - 如果其他Cache没有这份数据,本Cache从内存中取数据 - 如果其他Cache有这份数据,且状态为M,则将数据更新到内存,本Cache再从内存中取数据 - 如果其他Cache有这份数据,且状态为S或E,则本核从内存中取数据,这些Cache的缓存行都变成S |
- Exclusive - Share |
| LocalWrite |
- 从内存中取数据,在Cache中修改,状态变成M - 如果其他Cache有这份数据,且状态为M,则将数据更新到内存 - 如果其他Cache有这份数据,其他Cache的Cache line状态变成I |
M | |
| Remote Read | 本Cache是Invalid,别的核的操作与它无关 | I | |
| Remote Write | 既然是Invalid,别的核的操作与它无关 | I | |
| E(Exclusive) | Local Read | 从Cache中取数据,状态不变 | E |
| Local Write | 修改Cache中的数据,状态变成M | M | |
| Remote Read | 数据和其它核共用,状态变成了S | S | |
| Remote Write | 数据被修改,本Cache line不能再使用,状态变成I | I | |
| S(Shared) | Local Read | 从Cache中取数据,状态不变 | S |
| Local Write | 修改Cache中的数据,状态变成M, 其它核共享的Cache line状态变成I |
M | |
| Remote Read | 状态不变 | S | |
| Remote Write | 数据被修改,本Cache line不能再使用,状态变成I | I | |
| M(Modified) | Local Read | 从Cache中取数据,状态不变 | M |
| Local Write | 修改Cache中的数据,状态不变 | M | |
| Remote Read | 这行数据被写到内存中,使其它核能使用到最新的数据,状态变成S | S | |
| Remote Write | 这行数据被写到内存中,使其它核能使用到最新的数据,由于其它核会修改这行数据, 状态变成I |
I |
缓存行伪共享
乱序执行
乱序执行(out-of-orderexecution):是指CPU允许将多条指令不按程序规定的顺序分开发送给各相应电路单元处理的技术。这样将根据各电路单元的状态和各指令能否提前执行的具体情况分析后,将能提前执行的指令立即发送给相应电路。简单来说,CPU为了提高指令执行效率,会在一条指令执行过程中(比如去内存读数据(慢100倍)),去同时执行另一条指令,前提是,两条指令没有依赖关系。
乱序执行证明
public class Disorder {private static int x = 0, y = 0;private static int a = 0, b =0;public static void main(String[] args) throws InterruptedException {int i = 0;for(;;) {i++;x = 0; y = 0;a = 0; b = 0;Thread one = new Thread(new Runnable() {public void run() {//由于线程one先启动,下面这句话让它等一等线程two. 读着可根据自己电脑的实际性能适当调整等待时间.//shortWait(100000);a = 1;x = b;}});Thread other = new Thread(new Runnable() {public void run() {b = 1;y = a;}});one.start();other.start();one.join();other.join();String result = "第" + i + "次 (" + x + "," + y + ")";if(x == 0 && y == 0) {System.err.println(result);break;} else {//System.out.println(result);}}}public static void shortWait(long interval){long start = System.nanoTime();long end;do{end = System.nanoTime();}while(start + interval >= end);}}
合并写技术
总结
为什么要先讲硬件呢?因为Java内存模型很大程度上是为了向程序员屏蔽底层具体实现而存在的,为什么要屏蔽呢?就是因为底层存储器的复杂、CPU的乱序执行等等用来提高CPU执行效率的优化技术。

若有收获,就点个赞吧
0 人点赞
