前面讲了缓存行的概念,然后说了缓存一致性协议MESI。这里要显式的说一个缓存行可能存在的问题,就是缓存行伪共享——当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。
首先考虑以下这样一个场景: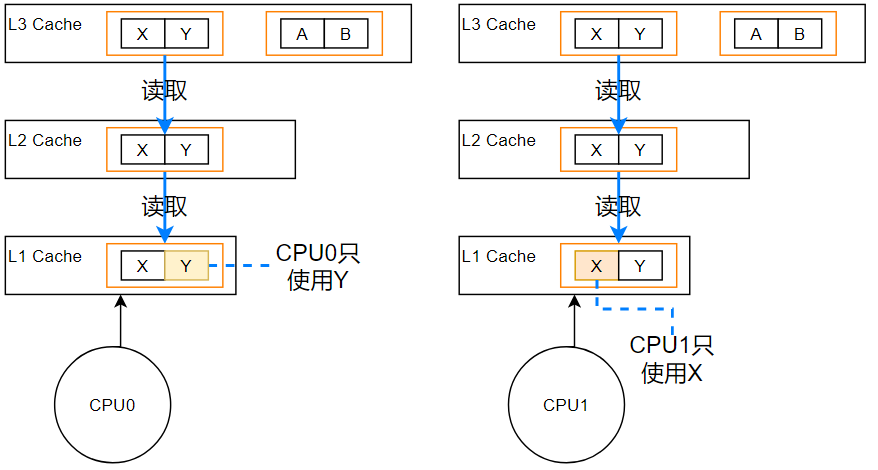
CPU0使用缓存行里的 Y 数据,CPU1使用相同缓存行里的 X 数据。结合前面讲的缓存MESI协议,此时该缓存行正处于 share 状态。
假设现在CPU0要对 Y 进行修改,因为是对自己内核的缓存行进行修改,所以该CPU0里的缓存行变成 Modify 状态,CPU1里的缓存行变成 Invalid 状态;当CPU1要读/写 X 时,要求CPU0将修改写入主存,然后CPU1再去读/写。如果CPU1又修改了 X ,那么CPU0又要重读/写整个缓存行。所以伪共享会造成性能损耗。
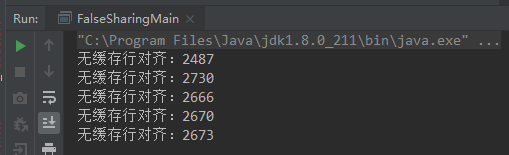
为了验证伪共享造成的性能问题,下面列出了“无缓存对齐”和“缓存对齐”两个案例来进行对比。最后还给了一个更好的方案来加强“缓存对齐”。
无缓存对齐
首先是一个没有运用缓存对齐的程序:
public class FalseSharingMain {private static class TestObject{public volatile long x = 0;}private static TestObject[] objects = new TestObject[]{new TestObject(), new TestObject()};private static final int count = 10000_0000;public static void main(String[] args) throws InterruptedException {for (int i = 0; i < 5; i++) {testCase1();}}private static void testCase1() throws InterruptedException {Thread t1 = new Thread(()->{for (long i = 0; i < count; i++) {objects[0].x = i;}});Thread t2 = new Thread(()->{for (long i = 0; i < count; i++) {objects[1].x = i;}});long currentMillions = System.nanoTime();t1.start();t2.start();t1.join();t2.join();System.out.println("无缓存行对齐:" + ((System.nanoTime() - currentMillions) / 100_0000));}}
缓存对齐
我们看一下下面这个缓存对齐了的程序:
public class FalseSharingMain2 {
private static class TestObject{
public volatile long x = 0;
}
private static class TestPaddingObject extends TestObject{
public volatile long p1, p2, p3, p4, p5, p6, p7;
}
// 修改了这个数组的类型,让静态类型指向要修改的类
private static TestPaddingObject[] objects2 = new TestPaddingObject[]{new TestPaddingObject(),
new TestPaddingObject()};
private static final int count = 10000_0000;
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < 5; i++) {
testCase2();
}
}
private static void testCase2() throws InterruptedException {
Thread t1 = new Thread(() -> {
for (long i = 0; i < count; i++) {
objects2[0].x = i;
}
});
Thread t2 = new Thread(() -> {
for (long i = 0; i < count; i++) {
objects2[1].x = i;
}
});
long currentMillions = System.nanoTime();
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("缓存行对齐:" + ((System.nanoTime() - currentMillions) / 100_0000));
}
}
直接看结果: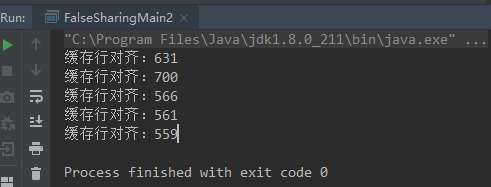
缓存对齐(加强)
该种方案比较适合要修改的变量个数比较少的情况。
public class FalseSharingMain2 {
private static class TestObject{
public volatile long p1, p2, p3, p4, p5, p6, p7;
}
private static class TestPaddingObject extends TestObject{
public volatile long x = 0;
public volatile long p8, p9, p11, p12, p13, p14, p15;
}
private static TestPaddingObject[] objects2 = new TestPaddingObject[]{new TestPaddingObject(), new TestPaddingObject()};
private static final int count = 10000_0000;
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < 20; i++) {
testCase2();
}
}
private static void testCase2() throws InterruptedException {
Thread t1 = new Thread(() -> {
for (long i = 0; i < count; i++) {
objects2[0].x = i;
}
});
Thread t2 = new Thread(() -> {
for (long i = 0; i < count; i++) {
objects2[1].x = i;
}
});
long currentMillions = System.nanoTime();
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("缓存行对齐:" + ((System.nanoTime() - currentMillions) / 100_0000));
}
}
缓存对齐写法
JDK6
我们可以简单的使用 long 类型进行对齐:
public static class A{
private volatile long p1, p2, p3, p4, p5, p6, p7;
private volatile long x;
}
JDK7
可能会对空的 long 类型进行优化,所以这个版本下
JDK8
使用 @Contended 注解,将该注解放在类上,JVM会自动对齐
结论
在多线程情况下,如果要对某几个变量频繁修改,看看这几个变量是否能够缓存对齐。做完对齐之后,最好new一下对象,通过内存布局 jol 库,来查看这个对象的实例数据是否满足64Byte。

若有收获,就点个赞吧
0 人点赞
