http://www.cs.umd.edu/~pugh/java/memoryModel/jsr-133-faq.html
Java内存模型是JSR-133的名字,提出来用于解决并发编程下的一些问题。属于JVM规范里面,但请不要把运行时内存规范也拿出来放一起说,这两个不是一个概念!
本篇将对 JMM 的作用从头到尾一一剖析,剖析思路如下图所示:
点击查看【processon】
将文章分为三个阶段:
- 底层:当程序运行时,底层的JVM、操作系统、硬件(特指CPU)都在悄咪咪地做哪些优化
**JMM**层面:这个层面并不是真实存在的,只是以规范的形式指导开发人员如何正确编写并发程序;让JVM层想办法支持这些规范;- 代码层面(应用层面):
JMM如何指导开发人员编写正确的并发程序底层
这个底层范围比较宽泛, 主要就是JVM、操作系统以及CPU等不常接触的底层知识。首先要分析一些真硬件的东西,它们在底层悄咪咪地替我们做了许多优化,而这些优化虽然能提高速度,但是无意间会造成我们程序的错误,我们可以通过《Java内存模型前置篇(硬件)》来学习一下CPU层面做了哪些优化,这些优化会有什么问题。
除了硬件之外,还要说说JVM层,因为JVM是C++写的,字节码载入JVM执行时肯定是要转成C++执行的,这之中也会做一些优化,比如调整指令执行的顺序。虽然这些优化也能提高速度,但是无意间也会导致程序的逻辑与预期的不一致。
总结一下,底层为了上面的应用能够快快的跑都做了许多优化,但是这些优化手段在 JMM 这种 内存共享型内存模型中,很容易发生一个叫 “内存可见性问题”。而内存可见性的源头主要归为重排序问题:
- 重排序
- 指令重排序
- 内存重排序
代码层面
当开发人员还只是写单线程应用时,因为 JMM 帮我们做了一些处理(指 As-If-Serial ),所以体会不到底层优化带来的一些问题。
但是当开发人员开始写并发应用时, As-If-Serial 的作用就比较有限了,底层优化带来的问题就一个个暴露出来了,比较常见的就是内存可见性问题、指令重排问题。As-If-Serial 内容戳这里直达《👀JMM - As If Serial语义》。
总之,开发人员编写并发程序时,不考虑任何其他的同步手段, As-If-Serial 的语义还是太弱了。
JMM
那如果开发人员想编写个并发程序,岂不是还要知道底层知识?而且不同的硬件底层还都不一样,这学习成本不要太高!这不,大佬们就整出了一份《JSR-133》用来说明什么样的情况 JVM 帮你解决了可见性问题;哪些问题 JVM 没有解决,需要开发人员自行抉择的。但是这份规范长篇大论的,理论知识还贼多,看着贼难~
我选择通过各大博客文章、书籍来学习内存模型,并辅以《JSR-133》加深理解。
什么是内存模型
通过上面对各层的学习,我们知道了底层的一些优化带来的麻烦。而内存模型就是为了解决这个问题而生的,它并不是真实存在的一套系统,而是一套规范、准则。按照这些规范编写的Java程序在各种不同的平台上都能达到内存访问的一致性。
对 JMM 层次大纲进行线程和内存间关系的抽象,我们能得出如下图所示的关系: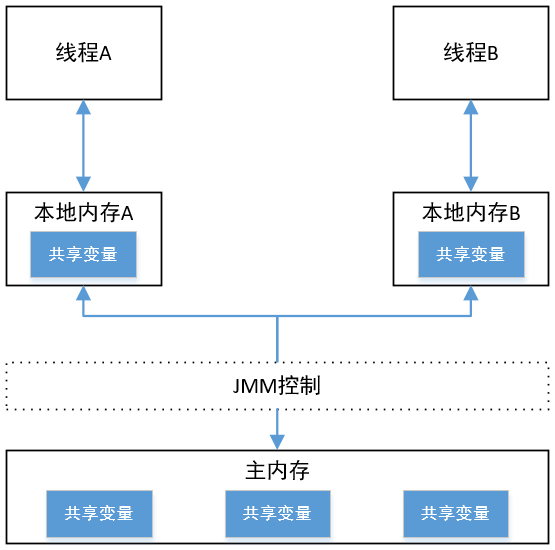
线程间共享的变量存在主内存(Main Memory)中,每个线程都有一个私有的本地内存(Local Memory),本地内存中存储了该线程以读/写共享变量的副本。本地内存是JMM的一个抽象概念,并不真实存在。它涵盖了缓存、写缓冲区、寄存器以及其他的硬件和编译器优化。
总结一下 JMM 里需要关注的两个重点:
- 共享变量/堆内存(Shared variables/Heap memory)能够在线程间共享的内存称作共享内存或堆内存。所有的实例字段,静态字段以及数组元素都存储在堆内存中。我们使用变量这个词来表示字段和数组元素。方法中的局部变量永远不会在线程间共享且不会被内存模型影响。
- 线程**间**的动作(Inter-thread Actions)是由某一线程执行,能被另一线程探测或直接影响的动作(action)。比如
lock或unlock某个管程,读写某个volatile变量等等
此外,我们无需关注线程内(intra-thread)的动作(如,将两个局部变量相加并将结果存储到第三个局部变量中),因为一个线程内的执行有 As-If-Serial 保障,我们只需要关注其他线程的干扰,即线程间的动作。
Java内存模型的设计思路
- 程序员对内存模型的使用。因为程序员希望内存模型简单易用、易于理解,所以程序员需要一个强内存模型(尽量偏向顺序一致性)编写程序
- 编译器和处理器对内存模型的实现。因为编译器和处理器希望内存模型对它们的束缚越小越好,这样方便调整指令顺序、优化指令提高性能,所以编译器和处理器需要一个弱内存模型(尽量远离顺序一致性)
所以JSR-133专家组在设计JMM时候就需要找到一个平衡点:一方面要保证程序员的简单易用性,一方面要保证对处理器和编译器的限制尽可能少。
总结
本章将按下图的思维导图顺序给大家分析在JMM之下的问题,以及JMM之上的解决方法:
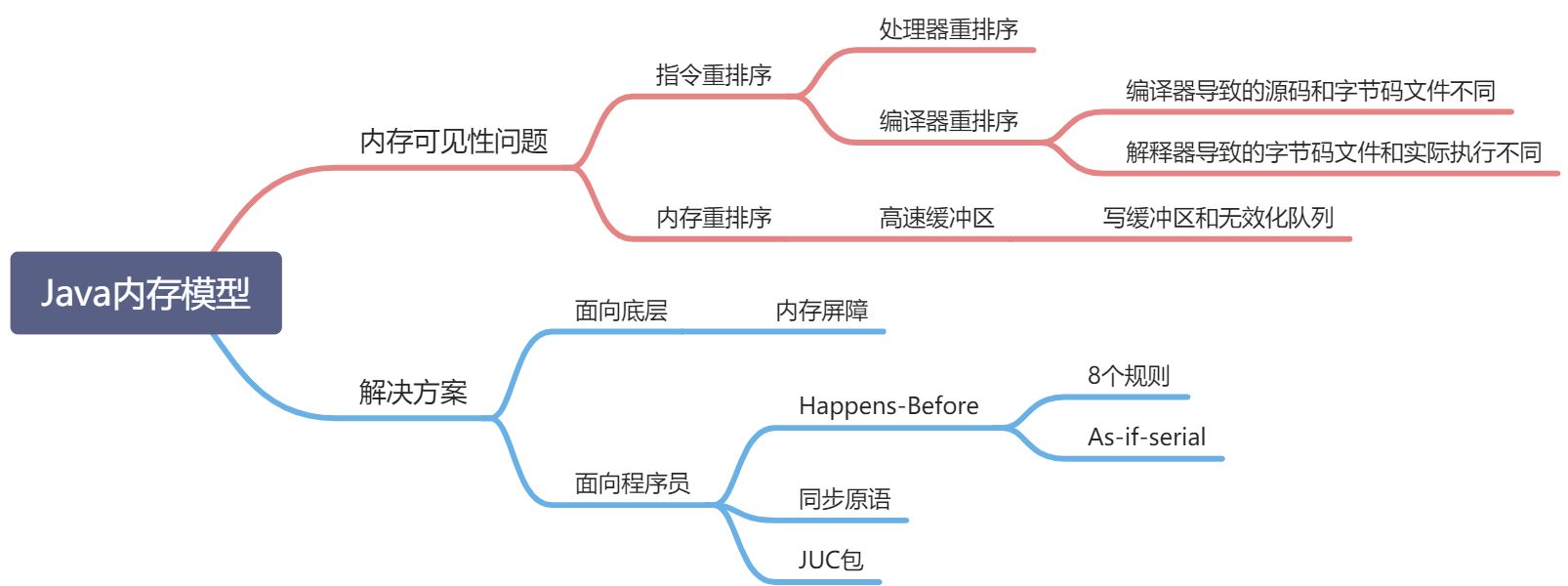 整体层次思路:Java采用的是内存共享模型,该模型会遇到内存可见性的问题,而内存可见性通常都是由 重排序 引发的,重排序又分为 指令重排序 和 内存重排序。为了解决上述问题,
整体层次思路:Java采用的是内存共享模型,该模型会遇到内存可见性的问题,而内存可见性通常都是由 重排序 引发的,重排序又分为 指令重排序 和 内存重排序。为了解决上述问题, JVM 底层提供了内存屏障技术,并将这些底层技术变成更易于使用的原语、工具、规范等等,帮助程序员不需要理解底层原理即可正确实现的程序。除此之外,还有些工具提供了更高的一致性保证(比如使用 synchronized ),但是会增加性能消耗。所以这方面的选择还需要程序员自行判断定夺。
内存可见性问题
因为 Java 是在虚拟机上的语言,所以底层有很多中间层。如果较真起来,内存可见性问题可以变得十分复杂,但是总的来说常见的原因有下面这两类:
- 指令重排序:当发生指令重排序时,
CPU执行的指令已经和预期的不一致了。因为Java的层次比较高,很多中间层都会对指令进行优化,常见的中间层有:javac编译器、JIT及时编译:源代码文件编译过程中优化指令- 解释器执行:
JVM本身是用C++编写的,C++代码执行过程中也可能存在优化(重排序) CPU执行:合并写技术、乱序执行(Wiki)
- 内存重排序:当发生内存重排序时,此时
CPU确实是按指令 (特指内存操作相关的指令) 执行的,但因为CPU和 主存中存在着高速缓冲区等一系列中间硬件,它们在主存读写中起到一定作用,而它们的一些行为可能会让指令的执行无序。
解决方法
HappensBefore原则
同步原语
JUC包
参考资料

若有收获,就点个赞吧
0 人点赞
