数据如何存储比较高效?
内存:读取快,可靠性差
硬盘:读取慢,可靠性高
个人理解:NameNode采用 硬盘+存储,硬盘修改操作效率差,内存修改操作高,为了解决硬盘修改差的问题,采用每次修改操作,都追加到文件中edits,然后定时将所有操作进行合并,将最终值放到fsimages中
NN 和 2NN
NameNode和SecondaryNameNode工作流程示意: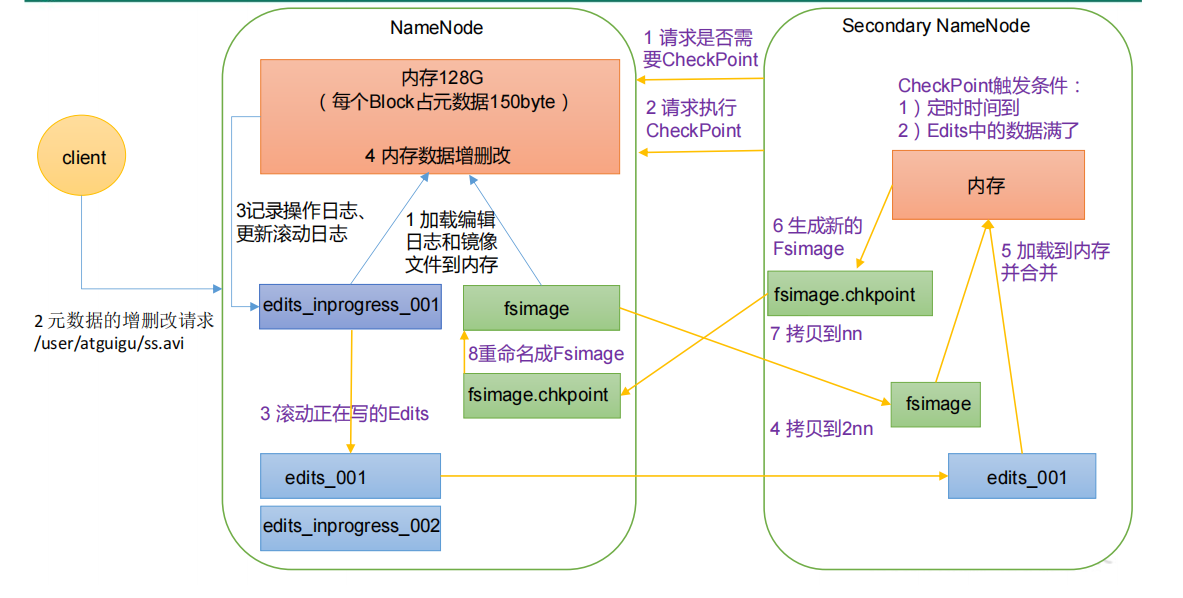 :::info
fsimages(镜像文件)是负责记录最终实际值。
:::info
fsimages(镜像文件)是负责记录最终实际值。
edits(编辑日志)存储的是每次数据的操作步骤。例如:edits_inprogress_xxx
:::
在没有 SecondaryNameNode 的集群中,NameNode的工作流程是:
- 系统启动后,将edits和fsimage从硬盘加载到内存中,方便数据的快速增删改。先加载fsimage内容到内存,然后在内存中按顺序把将edits中修改的内容执行一遍。
- 元数据发生变动时,edits中记录改变向量,内存中数据也同步修改,但是不写入磁盘的fsimage
- 系统关闭时,将edits中的改变向量按顺序执行,写入到fsimage中
有了SecondaryNameNode的集群,SecondaryNameNode会定期询问NameNode是否到达检查点(checkpoint),如果到达了检查点,SecondaryNameNode就辅助NameNode执行edits信息向fsimage中写入。
NameNode工作流程为:
- 系统启动,将edits和fsimage从磁盘加载到内存中
- 客户端发出修改元数据的请求给NameNode
- NameNode将修改数据的改变向量写入磁盘的edit_inprogress中,然后同步修改掉内存中的数据
SecondaryNameNode工作流程为:
- 向NameNode询问是否到达检查点(默认如果Edits记录的修改次数达到100万,或者距离上个checkpoint时间间隔了1小时,就到达了检查点)
- 如果到达检查点,请求执行Checkpoint
- NameNode的edit_inprogress_001中存储的改变向量滚动写入Edits中。在edit_inporgress_001写入edits过程中,如果客户端向NameNode发出改变元数据的请求,这部分新的改变向量被暂时先写入edit_inprogress_002中。
- 将NameNode的Edits、fsimage拷贝到SecondaryNameNode
- 将Edits、fsimage信息加载到自己的内存中。在fsimage基础上顺序执行Edits中的改变向量
- 将内存中的计算结果写入磁盘fsimage.checkpoint
- 将fsimage.checkpoint拷贝给NameNode
- NameNode将fsimage.checkpoint重命名为fsimage,覆盖原有的fsimage
NameNode中存储着很多的Edits文件,有些已经在fsimage中合并过了。那么开机启动时,NameNode如何判断还需要合并哪些Edits?
答:每个Edits文件名上都有编号,例如edits_0000000000000000423-0000000000000000424、edits_0000000000000000424-0000000000000000425,当这个Edits被合并到fsimage后,生成的这个fsimage文件名上也会带有这个编号,例如fsimage_0000000000000000425。系统开机启动时,向内存中加载完fsimage_0000000000000000425,然后只会将编号大于0000000000000000425的Edits文件加载到内存中进行执行。
因为checkpoint拷贝的时候,客户端如果向DataNode发出写元数据的请求,这部分元数据的修改被记录到了NameNode的edit_inprogress中,而SecondaryNameNode没有这个文件。所以如果NameNode宕机,使用SecondaryNameNode临时充当NameNode的话,会丢失掉这部分信息。
FSImage 和 Edits
NameNode被格式化之后,将在$HADOOP_HOME/data/dfs/name/current目录下产生如下文件:
- fsimage_xxxxxx
- fsimage_xxxxxx.md5
- seen_txid
- VERSION
如果NameNode中存储的元数据信息有修改变动,还会在该文件夹下生成:
- edits_xxxx
- edits_inprogress_xxxxx
FSImage文件:HDFS文件系统元数据的一个永久性的检查点。其中包含HDFS文件系统的所有目录和文件inode的序列化信息
Edits文件:存放HDFS文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先会被记录到Edits文件中。因为它只是记录本次修改的这个操作指令,并不直接去FSImage上修改指定元数据,所以Edits写的速度比较快。
seen_txid:保存的是一个数字。就是最后一个 edits_xxx 的数字
VERSION:记录了NameNode的命令空间编号namespaceID,还有集群编号clusterID等信息。
每次NameNode启动时候都会将FSImage文件读入内存,加载Edis里面的更新操作,保证内存中的元数据信息是最新的、同步的,可以看成NameNode启动时候就将FSImage和Edits文件进行了合并。
oiv 和 oev命令
使用cat等命令无法直接查看FSImage和Edits文件,可以借助hdfs oiv查看FSImage,借助hdfs oev查看Edits文件。
使用oiv命令查看FSImage文件:
hdfs oiv -p <文件类型> -d <FSImage文件> -o <转换后要输出的文件>
示例:
# 将fsimage_0000000000000000423转换成一个XML文件进行查看hdfs oiv -p XML -i fsimage_0000000000000000423 -o /app/423.xml
通过输出的xml可以看到,FSImage中以树状结构存储了文件和所属文件夹之间的关联信息,以及文件的元数据。
但是FSImage中并没有存储每个数据块存储在哪台DataNode上。而是在系统上电启动时,DataNode主动向NameNode汇报自己服务器上存储的数据块信息。
使用oev命令查看Edits文件:
hdfs oev -p <文件类型> -i <Edits文件> -o <转换后要输出的文件>
示例:
hdfs oev -p XML -i edits_0000000000000000424-0000000000000000425 -o /app/e424.xml# 也可以查看当前正在写入的Edits文件hdfs oev -p XML -i edits_inprogress_0000000000000000426 -o /app/inprogress.xml
CheckPoint设置
默认执行CheckPoint的情况:
- 通常情况下,SecondaryNameNode每隔一小时执行一次
- 每分钟检查一次Edits的操作次数,当操作次数达到100万时,SecondaryNameNode执行一次
间隔时间的配置:hdfs-default.xml
<property><name>dfs.namenode.checkpoint.period</name><value>3600s</value></property>
操作次数设置、检查操作次数的时间间隔设置:hdfs-default.xml
<property><name>dfs.namenode.checkpoint.txns</name><value>1000000</value><describe>操作动作次数</describe></property><property><name>dfs.namenode.checkpoint.check.period</name><value>60s</value><describe>1分钟检查一次操作次数</describe></property>

若有收获,就点个赞吧
0 人点赞
