准备工作
下载Hive
Hive 1.x 和 Hadoop 1.x 对应;
Hive 2.x 和 Hadoop 2.x 对应;
Hive 3.x 和 Hadoop 3.x 对应;
到官网或者镜像中心下载对应版本的Hive。例如:apache-hive-3.1.3-bin.tar.gz
安装
解压
将 tar包上传到hadoop服务器,例如 hadoop102上的 /opt/software文件夹中。
解压到/opt/module文件夹:
tar -zxvf apache-hive-3.1.3-bin.tar.gz -C /opt/module/
如果感觉解压后的文件名比较长,可以进行重命名:
cd /opt/modulemv apache-hive-3.1.3-bin/ hive-3.1.3
配置环境变量
在/etc/profile.d/my_env.sh中加入以下环境变量:
# HIVE_HOMEexport HIVE_HOME=/opt/module/hive-3.1.3export PATH=$PATH:$HIVE_HOME/bin
解决日志 jar 包冲突
移除HIVE的日志jar包:
mv $HIVE_HOME/lib/log4j-slf4j-impl-2.17.1.jar $HIVE_HOME/lib/log4j-slf4j-impl-2.17.1.bak
不需要集群部署
因为Hive只是一个将HQL语句转换成MapReduce的工具,本质上也还是一个执行MapReduce任务的客户端,就和我们运行一个java程序一样,所以不存在集群化部署。
启动
初始化元数据库
当不修改配置时,hive默认使用的是自带的 derby 数据库。
启动前,需要先初始化元数据库:
bin/schematool -dbType derby -initSchema
如果执行报以下错误:
Exception in thread "main" java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)Vat org.apache.hadoop.conf.Configuration.set(Configuration.java:1357)at org.apache.hadoop.conf.Configuration.set(Configuration.java:1338)at org.apache.hadoop.mapred.JobConf.setJar(JobConf.java:536)at org.apache.hadoop.mapred.JobConf.setJarByClass(JobConf.java:554)at org.apache.hadoop.mapred.JobConf.<init>(JobConf.java:448)at org.apache.hadoop.hive.conf.HiveConf.initialize(HiveConf.java:5144)at org.apache.hadoop.hive.conf.HiveConf.<init>(HiveConf.java:5107)at org.apache.hive.beeline.HiveSchemaTool.<init>(HiveSchemaTool.java:96)at org.apache.hive.beeline.HiveSchemaTool.main(HiveSchemaTool.java:1473)at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)at java.lang.reflect.Method.invoke(Method.java:498)at org.apache.hadoop.util.RunJar.run(RunJar.java:323)at org.apache.hadoop.util.RunJar.main(RunJar.java:236)
则可能是 hive 内依赖的 guava.jar 和 hadoop内的 guava.jar版本不一致造成的。
检查方法:
- 查看
$HIVE_HOME/lib下的guava-xxx.jar(hive 3.1.3自带的是guava-19.0.jar) - 查看
$HADOOP_HOME/share/hadoop/common/lib下的guava-xxx.jar(hadoop 3.2.3自带的是guava-27.0-jre.jar)
将hive中低版本的guava的jar包移除,更换成 hadoop 的高版本 guava 包:
mv $HIVE_HOME/lib/guava-19.0.jar $HIVE_HOME/lib/guava-19.0.bakcp $HADOOP_HOME/share/hadoop/common/lib/guava-27.0-jre.jar $HIVE_HOME/lib/
然后重新执行初始化元数据命令即可。
初始化元数据库成功后,会在hive目录下生成:derby.log日志文件、metastore_db元数据库信息文件夹。
启动hive客户端
使用命令启动hive客户端:
bin/hive
查看启动日志,默认的日志保存位置为:/tmp/用户名/hive.log。
启动后,会出现一个警告:
Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.基于MR的Hive在 hive 2时已经过时,将来版本中可能会被弃用,考虑使用其他引擎(例如spark、tez),或者使用 hive 1.x。
简单的命令
HQL命令类似于Mysql的SQL:
-- 查看所有数据库show databases;-- 查看所有表show tables;-- 创建表create table test(id string); -- 字符串是string,整数是int,类似java的类型-- 插入一条数据insert into test values('aaa'); -- 该语句执行后,会被转换成一个MapReduce任务
默认生成的test文件为:/user/hive/warehouse/test/000000_0。该路径也可以自定义
更换元数据库
derby数据库的弊端
hive默认使用的是自带的derby数据库,该数据库使用起来不方便:
- 不能连接进去查看具体的内部数据
- 不支持多用户。当启动两个及以上的hive客户端时,就会报错
所以需要将hive的元数据库修改为MySQL。
安装Mysql数据库
下载:
到mysql官网下载对应Linux版本的Mysql 5.7安装包:mysql-5.7.28-1.el7.x86_64.rpm-bundle.tar
将安装包上传到 hadoop102 的/opt/software/目录并解压:
# 解压完的几个文件还是安装包,所以直接解压到 /opt/software 文件夹即可tar -xvf mysql-5.7.28-1.el7.x86_64.rpm-bundle.tar
卸载系统自带的Mysql:
# 检查当前系统是否已经自带了Mysqlrpm -qa | grep mariadb# 如果已经自带了Mysql,例如mariadb-libs-5.5.56-2.el7.x86_64,则先进行卸载sudo rpm -e --nodeps mariadb-libs# 卸载完重新检查rpm -qa | grep mariadb
安装Mysql:
需要注意安装顺序,后面的rpm对前面的有依赖
sudo rpm -ivh mysql-community-common-5.7.28-1.el7.x86_64.rpmsudo rpm -ivh mysql-community-libs-5.7.28-1.el7.x86_64.rpmsudo rpm -ivh mysql-community-libs-compat-5.7.28-1.el7.x86_64.rpmsudo rpm -ivh mysql-community-client-5.7.28-1.el7.x86_64.rpmsudo rpm -ivh mysql-community-server-5.7.28-1.el7.x86_64.rpm
如果出现检测mysql-community-libs-8.0.29-1.el7.x86_64.rpm: 头V4 RSA/SHA256 Signature, 密钥 ID 3a79bd29: NOKEY 安装命令后面加 —nodeps —force 例如 rpm -ivh mysql-community-libs-8.0.16-2.el7.x86_64.rpm —nodeps —force
如果linux是最小版本的,可能会缺少libaio等依赖,根据报错安装相关依赖即可:
# 如果报错缺少libaio依赖,则安装依赖即可。没报错则无需安装yum install -y libaio
删除datadir中的内容:
查看文件/etc/my.cnf 文件中的 datadir的值,默认是/var/lib/mysql。
进入该路径,查看该路径下是否有内容。如果有则清空该文件夹下的内容,如果没有则无需理会。
初始化数据库:
sudo mysqld --initialize --user=mysql
启动Mysql服务:
sudo systemctl start mysqld
mysqld服务默认就是开机自启,无需再配置开机自启。
查看临时生成的root用户的密码:
# 查看日志文件中生成root用户的临时密码 A temporary password is generated for root@localhost:sudo cat /var/log/mysqld.log
使用该密码登录数据库:
mysql -uroot -p
登入数据库后,修改root用户的密码,否则执行其他操作可能会报错:
-- set password = password("新密码");set password = password("root");
修改Mysql库下的user表中的root用户允许任意ip连接:
update mysql.user set host='%' where user='root';flush privileges;
更换为Mysql数据库
添加jdbc驱动:
从Maven中央仓库下载mysql驱动包:mysql-connector-java-5.1.37.jar
将mysql的jdbc驱动包放到$HIVE_HOME/lib目录下。
添加配置文件:
hive的配置文件位于$HIVE_HOME/conf目录下,该目录下自带了一些.template的模板样例。
与Hadoop的xxx-site.xml配置文件类似,Hive中用户自定义的配置文件叫hive-site.xml。
在$HIVE_HOME/conf下新建hive-site.xml:
内容可以参考
hive-default.xml.template模板
<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://hadoop102:3306/hive?useSSL=false</value><description>jdbc连接的URL</description></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value><description>jdbc驱动类</description></property><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value><description>用户名</description></property><property><name>javax.jdo.option.ConnectionPassword</name><value>root</value><description>密码</description></property><!-- 下面两处的校验是为了derby的校验。如果换成了Mysql数据库,都需要设置成false,否则hive会启动失败 --><property><name>hive.metastore.schema.verification</name><value>false</value><description>hive元数据存储版本的验证</description></property><property><name>hive.metastore.event.db.notification.api.auth</name><value>false</value><description>hive元数据存储授权</description></property><property><name>hive.metastore.warehouse.dir</name><value>/user/hive/warehouse</value><description>Hive表数据在HDFS的默认存储的工作目录</description></property></configuration>
初始化Mysql元数据库
登录Mysql,根据hive-site.xml配置的数据库实例名,在Mysql中创建Hive的元数据库:
create database hive;
使用hive的schematool工具初始化hive元数据库:
/opt/module/hive-3.1.3/bin/schematool -initSchema -dbType mysql -verbose
再次启动hive:
# 启动hive进行查看bin/hive
Hive向外提供服务
Hive安装之后,可以在本机进行使用,但是还无法让第三方客户端连接。
如果想在Java程序等第三方客户端中连接使用Hive服务,则还需开启Hive的对应服务。
使用元数据服务的方式访问Hive
- 在
hive-site.xml文件中添加如下信息:<property><name>hive.metastore.uris</name><value>thrift://hadoop102:9083</value><description>指定存储元数据要连接的地址</description></property>
- 启动
metastore服务:hive --service metastore
- 启动hive
bin/hive
配置了metastore服务后,第三方工具就可以通过该服务来连接本机的hive。
注意事项:
如果在hive-site.xml中配置了metastore服务,那么就必须启动该服务才能使用hive,否则会报错。
使用JDBC方式访问Hive
- 在
hive-site.xml中添加如下信息:<!-- 需要先配置metastore服务的:hive.metastore.uris --><property><name>hive.server2.thrift.bind.host</name><value>hadoop102</value><description>指定hive server2连接的host</description></property><property><name>hive.server2.thrift.bind.port</name><value>10000</value><description>指定hive server2连接端口号</description></property>
- 启动hive server2:
# 需要先启动metastore服务 hive --service metastorehive --service hiveserver2# 也可以使用 bin/hiveserver2命令启动
- 启动 beeline 客户端:(hiveserver2服务启动的比较慢,需要等待一会儿才能连上)
# beeline -u jdbc地址 -n 用户名# 不需要密码,hiveserver2没有密码bin/beeline -u jdbc:hive2://hadoop102:10000 -n tengyer
- 连接上之后,就可以正常的进行查询:
show tables;select * from test;
- hiveserver2启动后,会向外暴露一个WebUI服务,端口号是 10002,可以用浏览器进行访问:http://hadoop102:10002/
注意事项:
使用 hiveserver2时,底层会去连接 metastore 服务,所以除了要启动 hiveserver2服务外,还需要启动 metastore服务。
使用beeline连接hiveserver2时,如果报错:
WARN jdbc.HiveConnection: Failed to connect to hadoop102:10000Error: Could not open client transport with JDBC Uri: jdbc:hive2://hadoop102:10000: Failed to open new session: java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): User: tengyer is not allowed to impersonate tengyer (state=08S01,code=0)
需要在 Hadoop 的core-site.xml中添加配置:
<!-- 任意地址都可以使用hadoop 的超级代理用户tengyer连接(hive需要用) --><property><name>hadoop.proxyuser.tengyer.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.tengyer.groups</name><value>*</value></property>
配置完需要重启Hadoop。
编写Hive服务启动脚本
hive --service xxxx开启的服务或者bin/hiveserver2启动的服务默认是在前台运行的,需要保证窗口不关闭,所以需要改为使用 nohup 启动。
nohup hive --service metastore 2>&1 &nohup hive --service hiveserver2 2>&1 &
为了方便使用,可以编写成脚本,来管理服务的启动和关闭:~/bin/hiveservices.sh
#!/bin/bashHIVE_LOG_DIR=/opt/module/hive-3.1.3/logsif [ ! -d $HIVE_LOG_DIR ]thenmkdir -p $HIVE_LOG_DIRfi# 检查进程是否运行正常,参数1为进程名,参数2为进程端口function check_process(){pid=$(ps -ef 2>/dev/null | grep -v grep | grep -i $1 | awk '{print $2}')ppid=$(netstat -nltp 2>/dev/null | grep $2 | awk '{print $7}' | cut -d '/' -f 1)echo $pid[[ "$pid" =~ "$ppid" ]] && [ "$ppid" ] && return 0 || return 1}function hive_start(){metapid=$(check_process HiveMetastore 9083)cmd="nohup /opt/module/hive-3.1.3/bin/hive --service metastore >$HIVE_LOG_DIR/metastore.log 2>&1 &"[ -z "$metapid" ] && eval $cmd || echo "Metastore 服务已启动"server2pid=$(check_process HiveServer2 10000)cmd="nohup /opt/module/hive-3.1.3/bin/hiveserver2 >$HIVE_LOG_DIR/HiveServer2.log 2>&1 &"[ -z "$server2pid" ] && eval $cmd || echo "HiveServer2 服务已启动"}function hive_stop(){metapid=$(check_process HiveMetastore 9083)[ "$metapid" ] && kill $metapid || echo "Metastore服务未启动"server2pid=$(check_process HiveServer2 10000)[ "$server2pid" ] && kill $server2pid || echo "HiveServer2服务未启动"}case $1 in"start")hive_start;;"stop")hive_stop;;"restart")hive_stopsleep 2hive_start;;"status")check_process HiveMetastore 9083 >/dev/null && echo "Metastore服务运行正常" || echo "Metastore服务运行异常"check_process HiveServer2 10000 >/dev/null && echo "HiveServer2服务运行正常" || echo "HiveServer2服务运行异常";;*)echo Invalid Args!echo 'Usage: '${basename $0}' start|stop|restart|status';;esac
Hive 交互命令
不进入hive交互窗口执行sql
Hive提供的交互命令可以通过-help进行查看:
hive -help
使用-e直接执行sql,不需要再进入hive提示符中。就可以把sql写到shell脚本中进行执行:
# 后面可以执行多个sql语句hive -e "select * from test;"
使用-f执行sql文件:
# sql文件中可以带有多个sql语句hive -v hive.sql
查看在hive中输入的所有历史命令:
cat ~/.hivehistory
hive交互窗口
hive窗口进入:
bin/hive
hive窗口退出:
# exit或quitexit;
在hive交互窗口中查看 HDFS 文件系统内容:
# 在hive交互窗口中,可以直接查看hdfs文件系统内容dfs -fs /;
在hive交互窗口中执行Linux本地的命令:
在命令前加上
!即可执行Linux命令
!ls;!clear;
静默模式:
只打印结果,不打印中间转换成MR的调试信息
hive -S
Hive 其他常用属性配置
Hive运行日志信息配置
Hive的log默认存放在 /tmp/用户名/hive.log文件中。
在$HIVE_HOME/conf下新建hive-log4j2.properties配置文件,修改hive的日志配置信息:
内容可以复制
hive-log4j2.properties.template模板
# 修改配置文件中hive的日志文件夹路径配置property.hive.log.dir=/opt/module/hive/logs
打印当前所处的数据库和表头
通过bin/hive进入Hive交互窗口后,如果使用use xxx;切换了数据库实例,不方便看出来。使用select查询时也没有表头列名。
可以在hive-site.xml中加入如下两个配置:
<property><name>hive.cli.print.header</name><value>true</value></property><property><name>hive.cli.print.current.db</name><value>true</value></property>
参数配置方式
查看当前所有配置信息。在Hive的交互窗口中使用set;命令查看:
set;
参数配置的三种方式:
- 使用配置文件配置
默认的配置文件为:hive-default.xml。用户自定义的配置文件为:hive-site.xml
用户自定义配置会覆盖默认配置。另外,Hive也会读入Hadoop的配置项,因为Hiva是作为Hadoop的客户端启动的,Hive的配置会覆盖Hadoop的配置。配置文件的设定对本机启动的所有Hive进程都有效。 - 命令行参数方式配置
启动Hive时,可以在命令行添加-hiveconf param=value来设定参数。
该配置参数只对本地hive启动有效。
例如:hive -hiveconf mapred.reduce.tasks=10;
- 参数声明方式
可以在HQL中使用SET关键字设定参数。
例如:set mapred.reduce.tasks=100;
优先级:配置文件 < 命令行参数 < 参数声明。
有些系统级别的参数(例如 log4j 相关设定),必须使用前两种方式。
使用DBeaver等工具连接Hive
当Hive启动 jdbc 服务后,便可以使用 DBeaver 等第三方工具连接Hive。
Hive的 jdbc 驱动jar位于:$HIVE_HOME/jdbc文件夹下,如:hive-jdbc-3.1.3-standalone.jar
配置数据库连接:
主机:hadoop102,
端口:10000(配置的jdbc服务的端口)
数据库/默认:default(根据实际情况选择对应的数据库实例名)
用户名:kaixin(即hadoop的core-site.xml中配置的代理用户名)
密码:空
最终生成的JDBC url为:jdbc:hive2://hadoop102:10000/default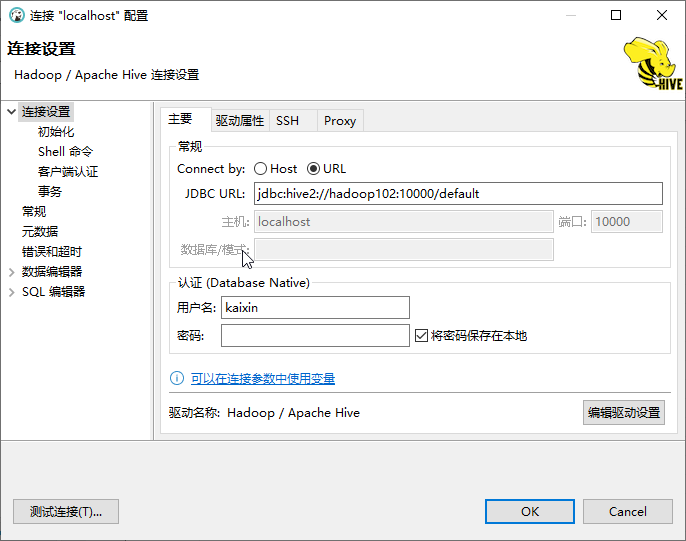

若有收获,就点个赞吧
0 人点赞
