2.1 创建 Maven 项目
增加 Scala 插件
Spark 版本为 3.0.0,默认采用的 Scala 编译版本为 2.12
增加依赖关系
<dependencies><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>3.0.0</version></dependency></dependencies><build><plugins><!-- 该插件用于将 Scala 代码编译成 class 文件 --><plugin><groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plugin</artifactId><version>3.2.2</version><executions><execution><!-- 声明绑定到 maven 的 compile 阶段 --><goals><goal>testCompile</goal></goals></execution></executions></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>3.1.0</version><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins></build>
WordCount
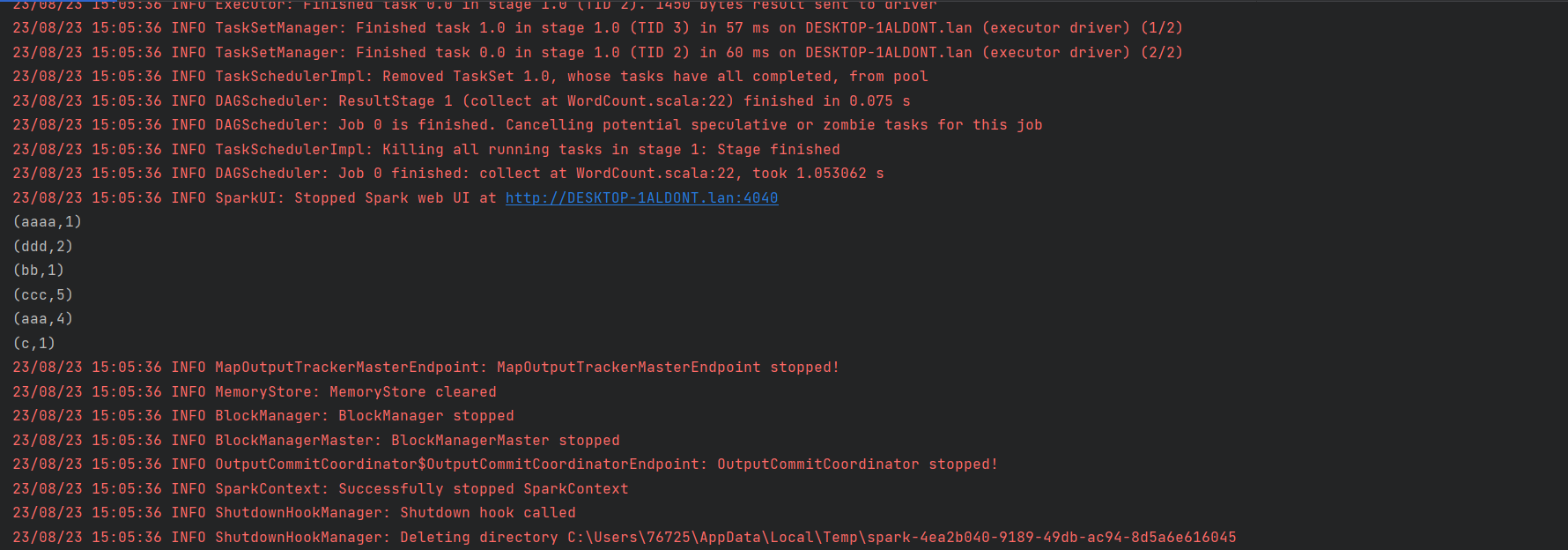
import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}object WordCount {def main(args: Array[String]): Unit = {// 创建Spark运行配置对象val sparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")// 创建Spark上下文环境对象(连接对象)val sc: SparkContext = new SparkContext(sparkConf)// 读取文件数据val fileRDD: RDD[String] = sc.textFile("F:\\学习资料下载\\spark\\2.资料\\data\\WordCount.txt")// 将文件中的数据进行分词val wordRDD: RDD[String] = fileRDD.flatMap(_.split(" "))// 转换数据结构 word => (word, 1)val word2OneRDD: RDD[(String, Int)] = wordRDD.map((_, 1))// 将转换结构后的数据按照相同的单词进行分组聚合val word2CountRDD: RDD[(String, Int)] = word2OneRDD.reduceByKey(_ + _)// 将数据聚合结果采集到内存中val word2Count: Array[(String, Int)] = word2CountRDD.collect()// 打印结果word2Count.foreach(println)//关闭 Spark 连接sc.stop()}

若有收获,就点个赞吧
0 人点赞
