一.应用
爬取知乎回答,总结,做合集单:
好书推荐,高赞高关注回答的总结整理观点的整理
爬起京东,淘宝,拼多多,亚马逊评论,给出评论词云,差评好评比例等
(如何判别刷单?)
- 爬取豆瓣评论
- 淘宝联盟,京东,爬取高佣金,高时长商品,到咸鱼上架。
- 1688上10元以内,可提供以免费送。12元邮费。
闲鱼:水果生鲜,日用百货,女装服饰
品牌分析
某品牌的商品分析
售后
二.爬虫基础
0x01.爬虫介绍
1.定义
2.工作流程
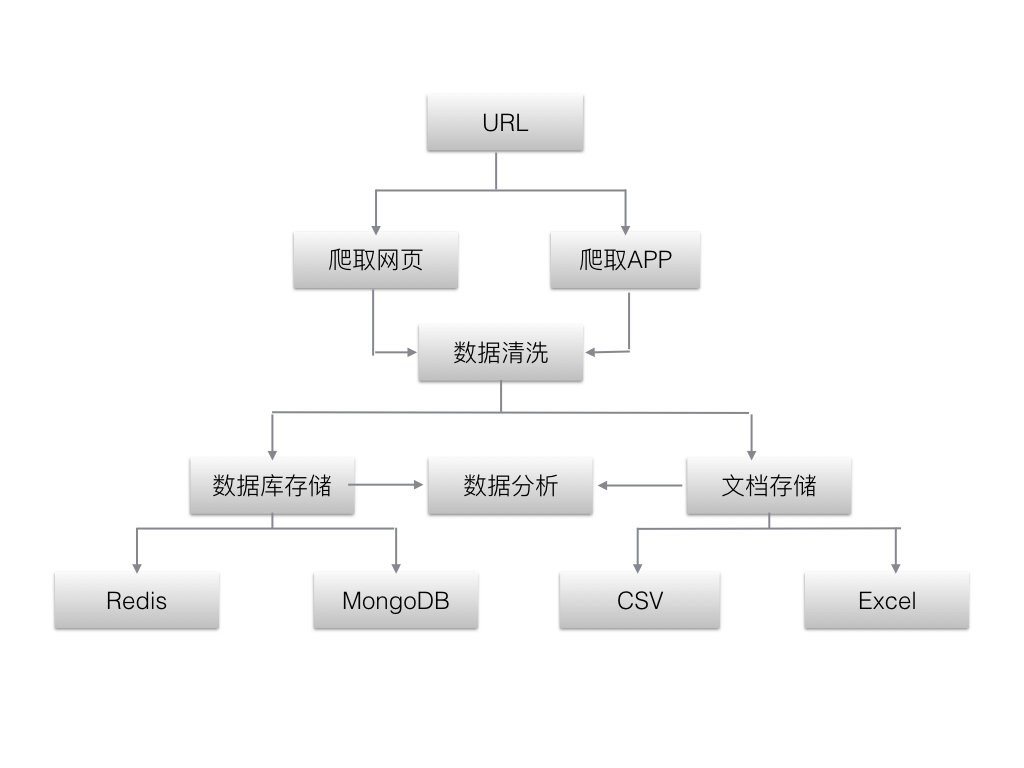
3.爬虫的分类
根据爬取的内容,可分为以下4类。
3.1通用类,搜索引擎
3.2聚焦类,针对特定网站
3.3增量类,只爬取变化
3.4深层类,需要经过账号登陆,验证码验证
4.爬虫抓取策略
4.1深度优先策略
在网页a爬取,发现存在a1,a2两个链接。先爬a1,如果在a1内发现有b1,b2,b3三个链接,则先进入b1,爬取。如果b1内没有新链接,则退回a1,进入b2。以此类推。
每个枝节都深入爬取,直到爬完,然后返回上层,逐渐当顶。
适合嵌套深的网站。
4.2广度优先策略
逐层爬取。在网页a爬取,如果网页a有两个链接,则爬进去。之后对这两个链接分别爬取。不深入到网页里的子链接。
适合同层次url多,要求快速爬取的网站。
5.爬虫学习基础
5.1python语言
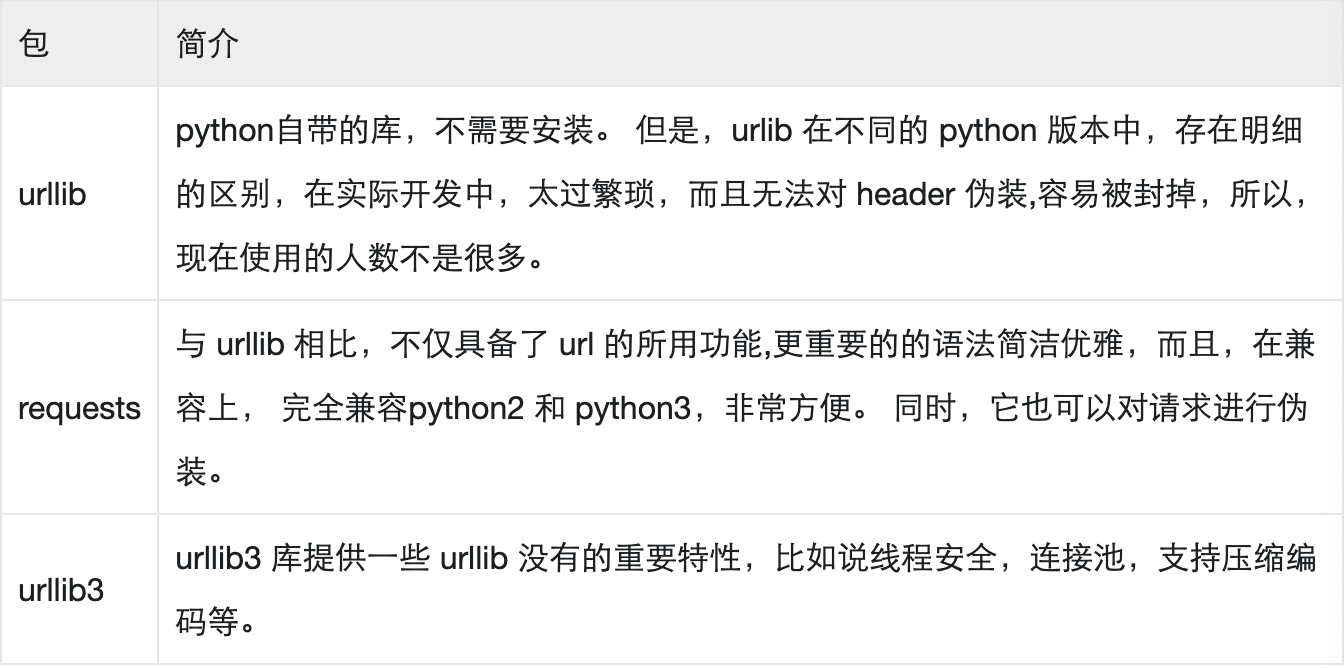
5.2数据库基础
5.3数据清洗和处理
6.爬虫法律和道德问题
6.1爬取注意事项
对特定网站,不能高频率并发,导致网站崩溃
爬取公共数据,如果商用,请专业法务对网站进行协议和声明进行分析确认后再用。
爬取非公开,需要用到个人账号。不允许公开数据。
6.2robots协议
0x02网页基础构成和抓取原理
1.网站的概念
1.1静态网站
所有页面使用html。无法与服务端互动。被动显示服务器端响应返回的信息。
优点:
容易被搜索引擎收录,方便seo优化;
内容独立,不依赖数据库。
缺点:
维护成本大,多数需要手工更新。
页面缺少互动,体验差。
1.2动态网站
提供与用户交互体验。如用户注册,实时推荐等。
包含静态html文件,还有服务端脚本,比如jsp,asp等。
优点:
用户体验好,实现个性化设置。
服务端与客户端互动,服务器对数据可管理和分析。
缺点:
客户端需要与数据库交互,降低访问速度;
对搜索引擎不友好。
2.网页三大基本元素
2.1html
超文本标记语言。约定文档的展现方式。
约定不同标签表示不同含义。
包含头部和主体两大部分。
负责页面结构。
2.2css
级联样式表或风格样式表。
配合html,提供丰富渲染效果。
负责页面样式。
2.3JavaScript
3.爬虫抓取原理
爬取的是html标签下特定数据,对数据进行持久化保存。
关键在于找到数据所处的html标签,因此需要分析网页的构成。
0x03html和css基础入门
1.html基础
常见标签
html:声明
head:头部
body:主体
title:标题
p:段落
button:按钮
h/h3:段落
bold:加粗
br:空行
img:图片,src带资源地址,alt提示不显示文字
a:超链接,href带链接
无序列表:ul下每项用li声明
有序列表:ol下每项用li声明
表格:table声明,thead表头,tbody表体;tr声明行,td是单元格。
表单:form声明,div块,label文本,input输入框,input有不同的形式,type声明,不同type对应不同额外属性
2.css基础
html里引入css样式:

若有收获,就点个赞吧
0 人点赞
