IO编程
IO在计算机中指Input/Output,也就是输入和输出。由于程序和运行时数据是在内存中驻留,由CPU这个超快的计算核心来执行,涉及到数据交换的地方,通常是磁盘、网络等,就需要IO接口。
IO编程中,Stream(流)是一个很重要的概念,可以把流想象成一个水管,数据就是水管里的水,但是只能单向流动。Input Stream就是数据从外面(磁盘、网络)流进内存,Output Stream就是数据从内存流到外面去。
IO编程中,Stream(流)是一个很重要的概念,可以把流想象成一个水管,数据就是水管里的水,但是只能单向流动。Input Stream就是数据从外面(磁盘、网络)流进内存,Output Stream就是数据从内存流到外面去。对于浏览网页来说,浏览器和新浪服务器之间至少需要建立两根水管,才可以既能发数据,又能收数据。
由于CPU和内存的速度远远高于外设的速度,所以,在IO编程中,就存在速度严重不匹配的问题。举个例子来说,比如要把100M的数据写入磁盘,CPU输出100M的数据只需要0.01秒,可是磁盘要接收这100M数据可能需要10秒,怎么办呢?有两种办法:
第一种是CPU等着,也就是程序暂停执行后续代码,等100M的数据在10秒后写入磁盘,再接着往下执行,这种模式称为同步IO;
另一种方法是CPU不等待,只是告诉磁盘,“您老慢慢写,不着急,我接着干别的事去了”,于是,后续代码可以立刻接着执行,这种模式称为异步IO。
同步和异步的区别就在于是否等待IO执行的结果。好比你去麦当劳点餐,你说“来个汉堡”,服务员告诉你,对不起,汉堡要现做,需要等5分钟,于是你站在收银台前面等了5分钟,拿到汉堡再去逛商场,这是同步IO。
你说“来个汉堡”,服务员告诉你,汉堡需要等5分钟,你可以先去逛商场,等做好了,我们再通知你,这样你可以立刻去干别的事情(逛商场),这是异步IO。
很明显,使用异步IO来编写程序性能会远远高于同步IO,但是异步IO的缺点是编程模型复杂。想想看,你得知道什么时候通知你“汉堡做好了”,而通知你的方法也各不相同。如果是服务员跑过来找到你,这是回调模式,如果服务员发短信通知你,你就得不停地检查手机,这是轮询模式。总之,异步IO的复杂度远远高于同步IO。
操作IO的能力都是由操作系统提供的,每一种编程语言都会把操作系统提供的低级C接口封装起来方便使用,Python也不例外。我们后面会详细讨论Python的IO编程接口。
文件
实际开发中常常会遇到对数据进行持久化操作的场景,而实现数据持久化最直接简单的方式就是将数据保存到文件中。
在Python中实现文件的读写操作其实非常简单,通过Python内置的open函数,我们可以指定文件名、操作模式、编码信息等来获得操作文件的对象,接下来就可以对文件进行读写操作了。这里所说的操作模式是指要打开什么样的文件(字符文件还是二进制文件)以及做什么样的操作(读、写还是追加),具体的如下表所示。
| 操作模式 | 具体含义 |
|---|---|
'r' |
读取 (默认) |
'w' |
写入(会先截断之前的内容) |
'x' |
写入,如果文件已经存在会产生异常 |
'a' |
追加,将内容写入到已有文件的末尾 |
'b' |
二进制模式 |
't' |
文本模式(默认) |
'+' |
更新(既可以读又可以写) |
下面这张图来自于菜鸟教程网站,它展示了如果根据应用程序的需要来设置操作模式。
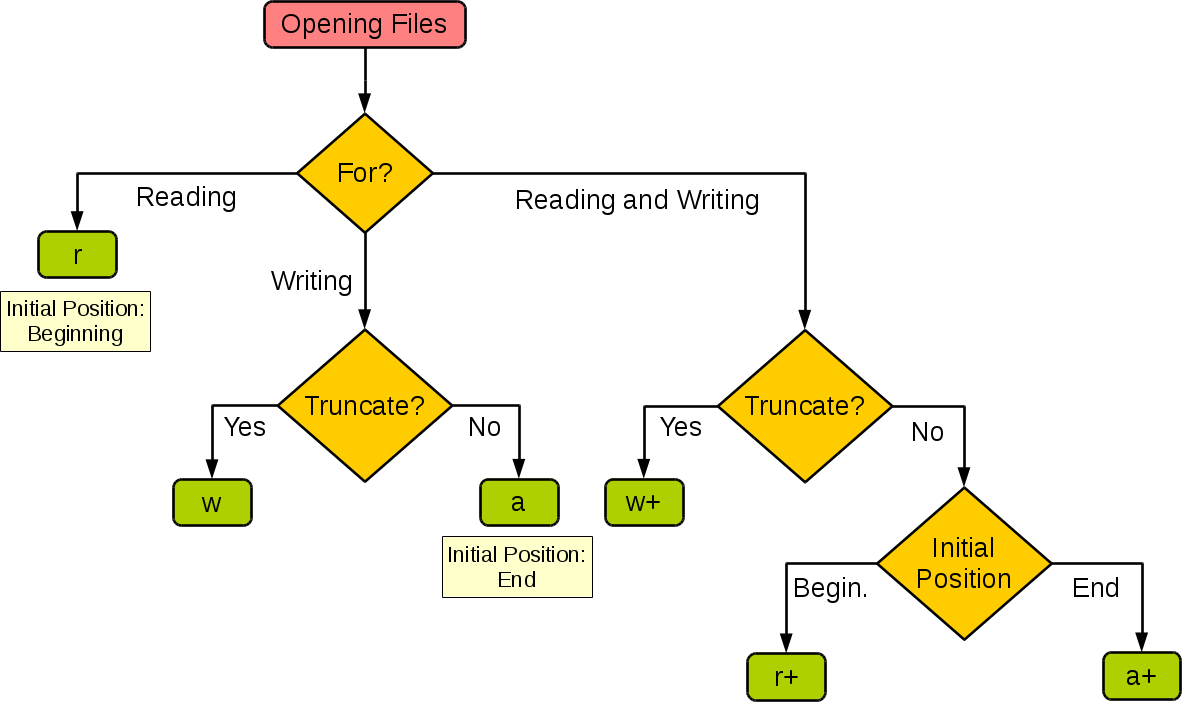
| 模式 | r | r+ | w | w+ | a | a+ |
|---|---|---|---|---|---|---|
| 读 | + | + | + | + | ||
| 写 | + | + | + | + | + | |
| 创建 | + | + | + | + | ||
| 覆盖 | + | + | ||||
| 指针在开始 | + | + | + | + | ||
| 指针在结尾 | + | + |
读文本文件
读取文本文件时,需要在使用open函数时指定好带路径的文件名(可以使用相对路径或绝对路径)并将文件模式设置为'r'(如果不指定,默认值也是'r'),然后通过encoding参数指定编码(如果不指定,默认值是None,那么在读取文件时使用的是操作系统默认的编码),如果不能保证保存文件时使用的编码方式与encoding参数指定的编码方式是一致的,那么就可能因无法解码字符而导致读取失败。下面的例子演示了如何读取一个纯文本文件。
def main():f = open('PythonIO.txt', 'r', encoding='utf-8')print(f.read())f.close()if __name__ == '__main__':main()
文件名称:PythonIO.txt
除了使用文件对象的read方法读取文件之外,还可以使用for-in循环逐行读取或者用readlines方法将文件按行读取到一个列表容器中,代码如下所示。
import timedef main():# 一次性读取整个文件内容with open('致橡树.txt', 'r', encoding='utf-8') as f:print(f.read())# 通过for-in循环逐行读取with open('致橡树.txt', mode='r') as f:for line in f:print(line, end='')time.sleep(0.5)print()# 读取文件按行读取到列表中with open('致橡树.txt') as f:lines = f.readlines()print(lines)if __name__ == '__main__':main()
写文本文件
文本信息写入文件文件也非常简单,在使用open函数时指定好文件名并将文件模式设置为'w'即可。
注意如果需要对文件内容进行追加式写入,应该将模式设置为'a'。如果要写入的文件不存在会自动创建文件而不是引发异常。下面的例子演示了如何将1-9999之间的素数分别写入三个文件中(1-99之间的素数保存在a.txt中,100-999之间的素数保存在b.txt中,1000-9999之间的素数保存在c.txt中)。
from math import sqrtdef is_prime(n):"""判断素数的函数"""assert n > 0for factor in range(2, int(sqrt(n)) + 1):if n % factor == 0:return Falsereturn True if n != 1 else Falsedef main():filenames = ('a.txt', 'b.txt', 'c.txt')fs_list = []try:for filename in filenames:fs_list.append(open(filename, 'w', encoding='utf-8'))for number in range(1, 10000):if is_prime(number):if number < 100:fs_list[0].write(str(number) + '\n')elif number < 1000:fs_list[1].write(str(number) + '\n')else:fs_list[2].write(str(number) + '\n')except IOError as ex:print(ex)print('写文件时发生错误!')finally:for fs in fs_list:fs.close()print('操作完成!')if __name__ == '__main__':main()
读写二进制文件
知道了如何读写文本文件要读写二进制文件也就很简单了,下面的代码实现了复制图片文件的功能。读取一个文件,在写出这个读入的文件。
def main():try:with open('PythonImage.png', 'rb') as fs1:data = fs1.read()print(type(data)) # <class 'bytes'>with open('PythonImageWrite.png', 'wb') as fs2:fs2.write(data)except FileNotFoundError as e:print('指定的文件无法打开.')except IOError as e:print('读写文件时出现错误.')print('程序执行结束.')if __name__ == '__main__':main()
读写JSON文件
如果希望把一个列表或者一个字典中的数据保存到文件中又该怎么做呢?答案是将数据以JSON格式进行保存。JSON是“JavaScript Object Notation”的缩写,它本来是JavaScript语言中创建对象的一种字面量语法,现在已经被广泛的应用于跨平台跨语言的数据交换,原因很简单,因为JSON也是纯文本,任何系统任何编程语言处理纯文本都是没有问题的。目前JSON基本上已经取代了XML作为异构系统间交换数据的事实标准。
| JSON类型 | Python类型 |
|---|---|
| {} | dict |
| [] | list |
| “string” | str |
| 1234.56 | int或float |
| true/false | True/False |
| null | None |
我们使用Python中的json模块就可以将字典或列表以JSON格式保存到文件中,代码如下所示。
import jsondef main():mydict = {'name': '杨宝宝','age': 38,'qq': 88888888,'friends': ['李元芳', '狄仁杰'],'cars': [{'brand': 'BC', 'max_speed': 180},{'brand': 'Aaodi', 'max_speed': 280},{'brand': 'BaoMa', 'max_speed': 320}]}try:with open('data.json', 'w', encoding='utf-8') as fs:json.dump(mydict, fs)except IOError as e:print(e)print('保存数据完成!')if __name__ == '__main__':main()
json模块主要有四个比较重要的函数,分别是:
dump- 将Python对象按照JSON格式序列化到文件中dumps- 将Python对象处理成JSON格式的字符串load- 将文件中的JSON数据反序列化成对象loads- 将字符串的内容反序列化成Python对象
这里出现了两个概念,一个叫序列化,一个叫反序列化。“序列化(serialization)在计算机科学的数据处理中,是指将数据结构或对象状态转换为可以存储或传输的形式,这样在需要的时候能够恢复到原先的状态,而且通过序列化的数据重新获取字节时,可以利用这些字节来产生原始对象的副本(拷贝)。与这个过程相反的动作,即从一系列字节中提取数据结构的操作,就是反序列化(deserialization)”。
StringIO
很多时候,数据读写不一定是文件,也可以在内存中读写。StringIO顾名思义就是在内存中读写str。
要把str写入StringIO,我们需要先创建一个StringIO,然后,像文件一样写入即可:
>>> from io import StringIO>>> f = StringIO()>>> f.write('hello')5>>> f.write(' ')1>>> f.write('world!')6>>> print(f.getvalue())hello world!
getvalue()方法用于获得写入后的str。
要读取StringIO,可以用一个str初始化StringIO,然后,像读文件一样读取:
>>> from io import StringIO>>> f = StringIO('Hello!\nHi!\nGoodbye!')>>> while True:... s = f.readline()... if s == '':... break... print(s.strip())...Hello!Hi!Goodbye!
BytesIO
StringIO操作的只能是str,如果要操作二进制数据,就需要使用BytesIO。
BytesIO实现了在内存中读写bytes,我们创建一个BytesIO,然后写入一些bytes:
>>> from io import BytesIO>>> f = BytesIO()>>> f.write('中文'.encode('utf-8'))6>>> print(f.getvalue())b'\xe4\xb8\xad\xe6\x96\x87'
请注意,写入的不是str,而是经过UTF-8编码的bytes。
和StringIO类似,可以用一个bytes初始化BytesIO,然后,像读文件一样读取:
>>> from io import BytesIO>>> f = BytesIO(b'\xe4\xb8\xad\xe6\x96\x87')>>> f.read()b'\xe4\xb8\xad\xe6\x96\x87'
异常
异常的语法:
try:# 可能会发生报错的逻辑except *Error:print('异常信息!')finally:# 一定执行
请注意上面的代码,如果open函数指定的文件并不存在或者无法打开,那么将引发异常状况导致程序崩溃。为了让代码有一定的健壮性和容错性,我们可以使用Python的异常机制对可能在运行时发生状况的代码进行适当的处理,如下所示。
def main():f = Nonetry:f = open('PythonIO.txt', 'r', encoding='utf-8')print(f.read())except FileNotFoundError:print('无法打开指定的文件!')except LookupError:print('指定了未知的编码!')except UnicodeDecodeError:print('读取文件时解码错误!')finally:if f:f.close()if __name__ == '__main__':main()
在Python中,我们可以将那些在运行时可能会出现状况的代码放在try代码块中,在try代码块的后面可以跟上一个或多个except来捕获可能出现的异常状况。例如在上面读取文件的过程中,文件找不到会引发FileNotFoundError,指定了未知的编码会引发LookupError,而如果读取文件时无法按指定方式解码会引发UnicodeDecodeError,我们在try后面跟上了三个except分别处理这三种不同的异常状况。最后我们使用finally代码块来关闭打开的文件,释放掉程序中获取的外部资源,由于finally块的代码不论程序正常还是异常都会执行到(甚至是调用了sys模块的exit函数退出Python环境,finally块都会被执行,因为exit函数实质上是引发了SystemExit异常),因此我们通常把finally块称为“总是执行代码块”,它最适合用来做释放外部资源的操作。如果不愿意在finally代码块中关闭文件对象释放资源,也可以使用上下文语法,通过with关键字指定文件对象的上下文环境并在离开上下文环境时自动释放文件资源,代码如下所示。
def main():try:with open('致橡树.txt', 'r', encoding='utf-8') as f:print(f.read())except FileNotFoundError:print('无法打开指定的文件!')except LookupError:print('指定了未知的编码!')except UnicodeDecodeError:print('读取文件时解码错误!')if __name__ == '__main__':main()
字符串正则表达式
字符串是编程时涉及到的最多的一种数据结构,对字符串进行操作的需求几乎无处不在。比如判断一个字符串是否是合法的Email地址,虽然可以编程提取@前后的子串,再分别判断是否是单词和域名,但这样做不但麻烦,而且代码难以复用。
正则表达式就是用于描述这些规则的工具,换句话说正则表达式是一种工具,它定义了字符串的匹配模式(如何检查一个字符串是否有跟某种模式匹配的部分或者从一个字符串中将与模式匹配的部分提取出来或者替换掉)今天几乎所有的编程语言都提供了对正则表达式操作的支持,Python通过标准库中的re模块来支持正则表达式操作。
它的设计思想是用一种描述性的语言来给字符串定义一个规则,凡是符合规则的字符串,我们就认为它“匹配”了,否则,该字符串就是不合法的。
所以我们判断一个字符串是否是合法的Email的方法是:
- 创建一个匹配Email的正则表达式;
- 用该正则表达式去匹配用户的输入来判断是否合法。
关于正则表达式的相关知识,大家可以阅读这篇博客《正则表达式30分钟入门教程》,读完这篇文章后你就可以看懂下面的表格,这是我们对正则表达式中的一些基本符号进行的扼要总结。
| 符号 | 解释 | 示例 | 说明 | ||
| . | 匹配任意字符 | b.t | 可以匹配bat / but / b#t / b1t等 | ||
| \w | 匹配字母/数字/下划线 | b\wt | 可以匹配bat / b1t / b_t等 但不能匹配b#t | ||
| \s | 匹配空白字符(包括\r、\n、\t等) | love\syou | 可以匹配love you | ||
| \d | 匹配数字 | \d\d | 可以匹配01 / 23 / 99等 | ||
| \b | 匹配单词的边界 | \bThe\b | |||
| ^ | 匹配字符串的开始 | ^The | 可以匹配The开头的字符串 | ||
| $ | 匹配字符串的结束 | .exe$ | 可以匹配.exe结尾的字符串 | ||
| \W | 匹配非字母/数字/下划线 | b\Wt | 可以匹配b#t / b@t等 但不能匹配but / b1t / b_t等 | ||
| \S | 匹配非空白字符 | love\Syou | 可以匹配love#you等 但不能匹配love you | ||
| \D | 匹配非数字 | \d\D | 可以匹配9a / 3# / 0F等 | ||
| \B | 匹配非单词边界 | \Bio\B | |||
| [] | 匹配来自字符集的任意单一字符 | [aeiou] | 可以匹配任一元音字母字符 | ||
| [^] | 匹配不在字符集中的任意单一字符 | [^aeiou] | 可以匹配任一非元音字母字符 | ||
| * | 表示匹配任意个字符(包括0个) | \w* | |||
| + | 匹配1次或多次 | \w+ | |||
| ? | 匹配0次或1次 | \w? | |||
| {N} | 匹配N次 | \w{3} | |||
| {M,} | 匹配至少M次 | \w{3,} | |||
| {M,N} | 匹配至少M次至多N次 | \w{3,6} | |||
| 分支 | foo | bar | 可以匹配foo或者bar | ||
| (?#) | 注释 | ||||
| (exp) | 匹配exp并捕获到自动命名的组中 | ||||
(?<name>exp) |
匹配exp并捕获到名为name的组中 | ||||
| (?:exp) | 匹配exp但是不捕获匹配的文本 | ||||
| (?=exp) | 匹配exp前面的位置 | \b\w+(?=ing) | 可以匹配I’m dancing中的danc | ||
| (?<=exp) | 匹配exp后面的位置 | (?<=\bdanc)\w+\b | 可以匹配I love dancing and reading中的第一个ing | ||
| (?!exp) | 匹配后面不是exp的位置 | ||||
| (?<!exp) | 匹配前面不是exp的位置 | ||||
| *? | 重复任意次,但尽可能少重复 | a.b a.?b | 将正则表达式应用于aabab,前者会匹配整个字符串aabab,后者会匹配aab和ab两个字符串 | ||
| +? | 重复1次或多次,但尽可能少重复 | ||||
| ?? | 重复0次或1次,但尽可能少重复 | ||||
| {M,N}? | 重复M到N次,但尽可能少重复 | ||||
| {M,}? | 重复M次以上,但尽可能少重复 |
Python对正则表达式的支持
https://www.liaoxuefeng.com/wiki/1016959663602400/1017639890281664
有了准备知识,我们就可以在Python中使用正则表达式了。Python提供re模块,包含所有正则表达式的功能。
由于Python的字符串本身也用\转义,所以要特别注意:在书写正则表达式时使用了原始字符串的写法(在字符串前面加上了r),所谓 原始字符串 就是字符串中的每个字符都是它原始的意义,说得更直接一点就是字符串中没有所谓的转义字符啦。因为正则表达式中有很多元字符和需要进行转义的地方,如果不使用原始字符串就需要将反斜杠写作\,例如表示数字的\d得书写成\d,这样不仅写起来不方便,阅读的时候也会很吃力。
下面是re模块中的核心函数:
| 函数 | 说明 |
|---|---|
| compile(pattern, flags=0) | 编译正则表达式返回正则表达式对象 |
| match(pattern, string, flags=0) | 用正则表达式匹配字符串 成功返回匹配对象 否则返回None |
| search(pattern, string, flags=0) | 搜索字符串中第一次出现正则表达式的模式 成功返回匹配对象 否则返回None |
| split(pattern, string, maxsplit=0, flags=0) | 用正则表达式指定的模式分隔符拆分字符串 返回列表 |
| sub(pattern, repl, string, count=0, flags=0) | 用指定的字符串替换原字符串中与正则表达式匹配的模式 可以用count指定替换的次数 |
| fullmatch(pattern, string, flags=0) | match函数的完全匹配(从字符串开头到结尾)版本 |
| findall(pattern, string, flags=0) | 查找字符串所有与正则表达式匹配的模式 返回字符串的列表 |
| finditer(pattern, string, flags=0) | 查找字符串所有与正则表达式匹配的模式 返回一个迭代器 |
| purge() | 清除隐式编译的正则表达式的缓存 |
| re.I / re.IGNORECASE | 忽略大小写匹配标记 |
| re.M / re.MULTILINE | 多行匹配标记 |
下面我们通过一系列的例子来告诉大家在Python中如何使用正则表达式。
验证用户名和QQ号是否有效并给出提示信息
"""验证输入用户名和QQ号是否有效并给出对应的提示信息要求:用户名必须由字母、数字或下划线构成且长度在6~20个字符之间,QQ号是5~12的数字且首位不能为0"""import redef main():username = input('请输入用户名: ')qq = input('请输入QQ号: ')# match函数的第一个参数是正则表达式字符串或正则表达式对象# 第二个参数是要跟正则表达式做匹配的字符串对象m1 = re.match(r'^[0-9a-zA-Z_]{6,20}$', username)if not m1:print('请输入有效的用户名.')m2 = re.match(r'^[1-9]\d{4,11}$', qq)if not m2:print('请输入有效的QQ号.')if m1 and m2:print('你输入的信息是有效的!')if __name__ == '__main__':main()
从一段文字中提取出国内手机号码
import redef main():context = '''重要的事情说8130123456789遍,我的手机号是13512346789这个靓号,不是15600998765,也是110或119,王大锤的手机号才是15600998765。'''# 创建正则表达式对象 使用了前瞻和回顾来保证手机号前后不应该出现数字pattern = re.compile(r'(?<=\D)1[34578]\d{9}(?=\D)')listPhone = re.findall(pattern,context)print(listPhone)print('------------------------')# 通过迭代器取出匹配对象并获得匹配的内容for temp in pattern.finditer(context):print(temp.group())print('------------------------')# 通过search函数指定搜索位置找出所有匹配m = pattern.search(context)while m:print(m.group())m = pattern.search(context, m.end())if __name__ == '__main__':main()
替换字符串中的不良内容
def main():context = '你丫是傻叉吗? 我操你大爷的. Fuck you.'purified = re.sub('[操肏艹]|fuck|shit|傻[比逼叉缺吊屌]|煞笔','*', context, flags=re.IGNORECASE)print(purified) # 你丫是*吗? 我*你大爷的. * you.if __name__ == '__main__':main()
拆分长字符串
import redef main():poem = '窗前明月光,疑是地上霜。举头望明月,低头思故乡。'sentence_list = re.split(r'[,。, .]', poem)while '' in sentence_list:sentence_list.remove('')print(sentence_list) # ['窗前明月光', '疑是地上霜', '举头望明月', '低头思故乡']if __name__ == '__main__':main()
进程和线程
今天我们使用的计算机早已进入多CPU或多核时代,而我们使用的操作系统都是支持“多任务”的操作系统,这使得我们可以同时运行多个程序,也可以将一个程序分解为若干个相对独立的子任务,让多个子任务并发的执行,从而缩短程序的执行时间,同时也让用户获得更好的体验。因此在当下不管是用什么编程语言进行开发,实现让程序同时执行多个任务也就是常说的“并发编程”,应该是程序员必备技能之一。为此,我们需要先讨论两个概念,一个叫进程,一个叫线程。
进程就是操作系统中执行的一个程序,操作系统以进程为单位分配存储空间,每个进程都有自己的地址空间、数据栈以及其他用于跟踪进程执行的辅助数据,操作系统管理所有进程的执行,为它们合理的分配资源。进程可以通过fork或spawn的方式来创建新的进程来执行其他的任务,不过新的进程也有自己独立的内存空间,因此必须通过进程间通信机制(IPC,Inter-Process Communication)来实现数据共享,具体的方式包括管道、信号、套接字、共享内存区等。
一个进程还可以拥有多个并发的执行线索,简单的说就是拥有多个可以获得CPU调度的执行单元,这就是所谓的线程。由于线程在同一个进程下,它们可以共享相同的上下文,因此相对于进程而言,线程间的信息共享和通信更加容易。当然在单核CPU系统中,真正的并发是不可能的,因为在某个时刻能够获得CPU的只有唯一的一个线程,多个线程共享了CPU的执行时间。使用多线程实现并发编程为程序带来的好处是不言而喻的,最主要的体现在提升程序的性能和改善用户体验,今天我们使用的软件几乎都用到了多线程技术,这一点可以利用系统自带的进程监控工具(如macOS中的“活动监视器”、Windows中的“任务管理器”)来证实,如下图所示。
当然多线程也并不是没有坏处,站在其他进程的角度,多线程的程序对其他程序并不友好,因为它占用了更多的CPU执行时间,导致其他程序无法获得足够的CPU执行时间;另一方面,站在开发者的角度,编写和调试多线程的程序都对开发者有较高的要求,对于初学者来说更加困难。
Python既支持多进程又支持多线程,因此使用Python实现并发编程主要有3种方式:多进程、多线程、多进程+多线程。
多进程
Unix/Linux操作系统提供了一个fork()系统调用,它非常特殊。普通的函数调用,调用一次,返回一次,但是fork()调用一次,返回两次,因为操作系统自动把当前进程(称为父进程)复制了一份(称为子进程),然后,分别在父进程和子进程内返回。
子进程永远返回0,而父进程返回子进程的ID。这样做的理由是,一个父进程可以fork出很多子进程,所以,父进程要记下每个子进程的ID,而子进程只需要调用getppid()就可以拿到父进程的ID。
Python的os模块封装了常见的系统调用,其中就包括fork,可以在Python程序中轻松创建子进程:
import osprint('Process (%s) start...' % os.getpid())# Only works on Unix/Linux/Mac:pid = os.fork()if pid == 0:print('I am child process (%s) and my parent is %s.' % (os.getpid(), os.getppid()))else:print('I (%s) just created a child process (%s).' % (os.getpid(), pid))
运行结果如下:
Process (876) start...I (876) just created a child process (877).I am child process (877) and my parent is 876.# 如果在Windows报错:AttributeError: module 'os' has no attribute 'fork'
由于Windows没有fork调用,上面的代码在Windows上无法运行。而Mac系统是基于BSD(Unix的一种)内核,所以,在Mac下运行是没有问题的。
有了fork调用,一个进程在接到新任务时就可以复制出一个子进程来处理新任务,常见的Apache服务器就是由父进程监听端口,每当有新的http请求时,就fork出子进程来处理新的http请求。
multiprocessing
由于Windows没有fork调用,难道在Windows上无法用Python编写多进程的程序?Python是跨平台的,自然也应该提供一个跨平台的多进程支持。multiprocessing模块就是跨平台版本的多进程模块。
multiprocessing模块提供了一个Process类来代表一个进程对象,下面的例子演示了启动一个子进程并等待其结束:
from multiprocessing import Processimport os# 子进程要执行的代码def run_proc(name):print('Run child process %s (%s)...' % (name, os.getpid()))if __name__=='__main__':print('Parent process %s.' % os.getpid())p = Process(target=run_proc, args=('test',))print('Child process will start.')p.start()p.join()print('Child process end.')
创建子进程时,只需要传入一个执行函数和函数的参数,创建一个Process实例,用start()方法启动,这样创建进程比fork()还要简单。
join()方法可以等待子进程结束后再继续往下运行,通常用于进程间的同步。
Pool
如果要启动大量的子进程,可以用进程池的方式批量创建子进程:
from multiprocessing import Poolimport os, time, randomdef long_time_task(name):print('Run task %s (%s)...' % (name, os.getpid()))start = time.time()time.sleep(random.random() * 3)end = time.time()print('Task %s runs %0.2f seconds.' % (name, (end - start)))if __name__=='__main__':print('Parent process %s.' % os.getpid())p = Pool(4)for i in range(5):p.apply_async(long_time_task, args=(i,))print('Waiting for all subprocesses done...')p.close()p.join()print('All subprocesses done.')
Parent process 20444.Waiting for all subprocesses done...Run task 0 (84740)...Run task 1 (5456)...Run task 2 (79140)...Run task 3 (93200)...Task 0 runs 0.33 seconds.Run task 4 (84740)...Task 2 runs 1.27 seconds.Task 3 runs 1.79 seconds.Task 1 runs 2.94 seconds.Task 4 runs 2.98 seconds.All subprocesses done.
代码解读:
对Pool对象调用join()方法会等待所有子进程执行完毕,调用join()之前必须先调用close(),调用close()之后就不能继续添加新的Process了。
请注意输出的结果,task 0,1,2,3是立刻执行的,而task 4要等待前面某个task完成后才执行,这是因为Pool的默认大小在我的电脑上是4,因此,最多同时执行4个进程。这是Pool有意设计的限制,并不是操作系统的限制。如果改成:
p = Pool(5)
就可以同时跑5个进程。
由于Pool的默认大小是CPU的核数,如果你不幸拥有8核CPU,你要提交至少9个子进程才能看到上面的等待效果。
子进程
很多时候,子进程并不是自身,而是一个外部进程。我们创建了子进程后,还需要控制子进程的输入和输出。
subprocess模块可以让我们非常方便地启动一个子进程,然后控制其输入和输出。
下面的例子演示了如何在Python代码中运行命令nslookup www.python.org,这和命令行直接运行的效果是一样的:
import subprocessprint('$ nslookup www.python.org')r = subprocess.call(['nslookup', 'www.python.org'])print('Exit code:', r)
运行结果:
服务器: public1.114dns.comAddress: 114.114.114.114非权威应答:名称: dualstack.python.map.fastly.netAddresses: 2a04:4e42:11::223151.101.108.223Aliases: www.python.orgExit code: 0
进程间通信
Process之间肯定是需要通信的,操作系统提供了很多机制来实现进程间的通信。Python的multiprocessing模块包装了底层的机制,提供了Queue、Pipes等多种方式来交换数据。
我们以Queue为例,在父进程中创建两个子进程,一个往Queue里写数据,一个从Queue里读数据:
from multiprocessing import Process, Queueimport os, time, random# 写数据进程执行的代码:def write(q):print('Process to write: %s' % os.getpid())for value in ['A', 'B', 'C']:print('Put %s to queue...' % value)q.put(value)time.sleep(random.random())# 读数据进程执行的代码:def read(q):print('Process to read: %s' % os.getpid())while True:value = q.get(True)print('Get %s from queue.' % value)if __name__=='__main__':# 父进程创建Queue,并传给各个子进程:q = Queue()pw = Process(target=write, args=(q,))pr = Process(target=read, args=(q,))# 启动子进程pw,写入:pw.start()# 启动子进程pr,读取:pr.start()# 等待pw结束:pw.join()# pr进程里是死循环,无法等待其结束,只能强行终止:pr.terminate()
运行结果如下:
Process to write: 68620Process to read: 79524Put A to queue...Get A from queue.Put B to queue...Get B from queue.Put C to queue...Get C from queue.
在Unix/Linux下,multiprocessing模块封装了fork()调用,使我们不需要关注fork()的细节。由于Windows没有fork调用,因此,multiprocessing需要“模拟”出fork的效果,父进程所有Python对象都必须通过pickle序列化再传到子进程去,所以,如果multiprocessing在Windows下调用失败了,要先考虑是不是pickle失败了。
多线程
多任务可以由多进程完成,也可以由一个进程内的多线程完成。
我们前面提到了进程是由若干线程组成的,一个进程至少有一个线程。
由于线程是操作系统直接支持的执行单元,因此,高级语言通常都内置多线程的支持,Python也不例外,并且,Python的线程是真正的Posix Thread,而不是模拟出来的线程。
Python的标准库提供了两个模块:_thread和threading,_thread是低级模块,threading是高级模块,对_thread进行了封装。绝大多数情况下,我们只需要使用threading这个高级模块。
启动一个线程就是把一个函数传入并创建Thread实例,然后调用start()开始执行:
import time, threading# 新线程执行的代码:def loop():print('thread %s is running...' % threading.current_thread().name)n = 0while n < 5:n = n + 1print('thread %s >>> %s' % (threading.current_thread().name, n))time.sleep(1)print('thread %s ended.' % threading.current_thread().name)if __name__=='__main__':print('thread %s is running...' % threading.current_thread().name)t = threading.Thread(target=loop, name='LoopThread')t.start()t.join()print('thread %s ended.' % threading.current_thread().name)
thread MainThread is running...thread LoopThread is running...thread LoopThread >>> 1thread LoopThread >>> 2thread LoopThread >>> 3thread LoopThread >>> 4thread LoopThread >>> 5thread LoopThread ended.thread MainThread ended.
由于任何进程默认就会启动一个线程,我们把该线程称为主线程,主线程又可以启动新的线程,Python的threading模块有个current_thread()函数,它永远返回当前线程的实例。
主线程实例的名字叫MainThread,子线程的名字在创建时指定,我们用LoopThread命名子线程。名字仅仅在打印时用来显示,完全没有其他意义,如果不起名字Python就自动给线程命名为Thread-1,Thread-2……
Lock
多线程和多进程最大的不同在于,多进程中,同一个变量,各自有一份拷贝存在于每个进程中,互不影响,而多线程中,所有变量都由所有线程共享,所以,任何一个变量都可以被任何一个线程修改,因此,线程之间共享数据最大的危险在于多个线程同时改一个变量,把内容给改乱了。来看看多个线程同时操作一个变量怎么把内容给改乱了:
import time, threading# 假定这是你的银行存款:balance = 0def change_it(n):# 先存后取,结果应该为0:global balancebalance = balance + nbalance = balance - ndef run_thread(n):for i in range(2000000):change_it(n)if __name__=='__main__':t1 = threading.Thread(target=run_thread, args=(5,))t2 = threading.Thread(target=run_thread, args=(8,))t1.start()t2.start()t1.join()t2.join()print(balance)

注意:每台计算机的资源分配都不大一样,自己跑的时候可能会是0正确的执行
我们定义了一个共享变量balance,初始值为0,并且启动两个线程,先存后取,理论上结果应该为0,但是,由于线程的调度是由操作系统决定的,当t1、t2交替执行时,只要循环次数足够多,balance的结果就不一定是0了。
原因是因为高级语言的一条语句在CPU执行时是若干条语句,即使一个简单的计算:
balance = balance + n
也分两步:
- 计算
balance + n,存入临时变量中; - 将临时变量的值赋给
balance。
也就是可以看成:
x = balance + nbalance = x
由于x是局部变量,两个线程各自都有自己的x,当代码正常执行时:
初始值 balance = 0t1: x1 = balance + 5 # x1 = 0 + 5 = 5t1: balance = x1 # balance = 5t1: x1 = balance - 5 # x1 = 5 - 5 = 0t1: balance = x1 # balance = 0t2: x2 = balance + 8 # x2 = 0 + 8 = 8t2: balance = x2 # balance = 8t2: x2 = balance - 8 # x2 = 8 - 8 = 0t2: balance = x2 # balance = 0结果 balance = 0
但是t1和t2是交替运行的,如果操作系统以下面的顺序执行t1、t2:
初始值 balance = 0t1: x1 = balance + 5 # x1 = 0 + 5 = 5t2: x2 = balance + 8 # x2 = 0 + 8 = 8t2: balance = x2 # balance = 8t1: balance = x1 # balance = 5t1: x1 = balance - 5 # x1 = 5 - 5 = 0t1: balance = x1 # balance = 0t2: x2 = balance - 8 # x2 = 0 - 8 = -8t2: balance = x2 # balance = -8结果 balance = -8
究其原因,是因为修改balance需要多条语句,而执行这几条语句时,线程可能中断,从而导致多个线程把同一个对象的内容改乱了。
两个线程同时一存一取,就可能导致余额不对,你肯定不希望你的银行存款莫名其妙地变成了负数,所以,我们必须确保一个线程在修改balance的时候,别的线程一定不能改。
如果我们要确保balance计算正确,就要给change_it()上一把锁,当某个线程开始执行change_it()时,我们说,该线程因为获得了锁,因此其他线程不能同时执行change_it(),只能等待,直到锁被释放后,获得该锁以后才能改。由于锁只有一个,无论多少线程,同一时刻最多只有一个线程持有该锁,所以,不会造成修改的冲突。创建一个锁就是通过threading.Lock()来实现:
import time, threading# 假定这是你的银行存款:balance = 0lock = threading.Lock()def change_it(n):# 先存后取,结果应该为0:global balancebalance = balance + nbalance = balance - ndef run_thread(n):# 先要获取锁:lock.acquire()try:# 放心地改吧:change_it(n)finally:# 改完了一定要释放锁:lock.release()if __name__=='__main__':t1 = threading.Thread(target=run_thread, args=(5,))t2 = threading.Thread(target=run_thread, args=(8,))t1.start()t2.start()t1.join()t2.join()print(balance)
当多个线程同时执行lock.acquire()时,只有一个线程能成功地获取锁,然后继续执行代码,其他线程就继续等待直到获得锁为止。
获得锁的线程用完后一定要释放锁,否则那些苦苦等待锁的线程将永远等待下去,成为死线程。所以我们用try...finally来确保锁一定会被释放。
锁的好处就是确保了某段关键代码只能由一个线程从头到尾完整地执行,坏处当然也很多,首先是阻止了多线程并发执行,包含锁的某段代码实际上只能以单线程模式执行,效率就大大地下降了。其次,由于可以存在多个锁,不同的线程持有不同的锁,并试图获取对方持有的锁时,可能会造成死锁,导致多个线程全部挂起,既不能执行,也无法结束,只能靠操作系统强制终止。
ThreadLocal
在多线程环境下,每个线程都有自己的数据。一个线程使用自己的局部变量比使用全局变量好,因为局部变量只有线程自己能看见,不会影响其他线程,而全局变量的修改必须加锁。
但是局部变量也有问题,就是在函数调用的时候,传递起来很麻烦:
def process_student(name):std = Student(name)# std是局部变量,但是每个函数都要用它,因此必须传进去:do_task_1(std)do_task_2(std)def do_task_1(std):do_subtask_1(std)do_subtask_2(std)def do_task_2(std):do_subtask_2(std)do_subtask_2(std)
每个函数一层一层调用都这么传参数那还得了?用全局变量?也不行,因为每个线程处理不同的Student对象,不能共享。
如果用一个全局dict存放所有的Student对象,然后以thread自身作为key获得线程对应的Student对象如何?
global_dict = {}def std_thread(name):std = Student(name)# 把std放到全局变量global_dict中:global_dict[threading.current_thread()] = stddo_task_1()do_task_2()def do_task_1():# 不传入std,而是根据当前线程查找:std = global_dict[threading.current_thread()]...def do_task_2():# 任何函数都可以查找出当前线程的std变量:std = global_dict[threading.current_thread()]...
这种方式理论上是可行的,它最大的优点是消除了std对象在每层函数中的传递问题,但是,每个函数获取std的代码有点丑。有没有更简单的方式?
ThreadLocal应运而生,不用查找dict,ThreadLocal帮你自动做这件事:
import threading# 创建全局ThreadLocal对象:local_school = threading.local()def process_student():# 获取当前线程关联的student:std = local_school.studentprint('Hello, %s (in %s)' % (std, threading.current_thread().name))def process_thread(name):# 绑定ThreadLocal的student:local_school.student = nameprocess_student()if __name__=='__main__':t1 = threading.Thread(target= process_thread, args=('Alice',), name='Thread-A')t2 = threading.Thread(target= process_thread, args=('Bob',), name='Thread-B')t1.start()t2.start()t1.join()t2.join()
Hello, Alice (in Thread-A)Hello, Bob (in Thread-B)
全局变量local_school就是一个ThreadLocal对象,每个Thread对它都可以读写student属性,但互不影响。你可以把local_school看成全局变量,但每个属性如local_school.student都是线程的局部变量,可以任意读写而互不干扰,也不用管理锁的问题,ThreadLocal内部会处理。
可以理解为全局变量local_school是一个dict,不但可以用local_school.student,还可以绑定其他变量,如local_school.teacher等等。
ThreadLocal最常用的地方就是为每个线程绑定一个数据库连接,HTTP请求,用户身份信息等,这样一个线程的所有调用到的处理函数都可以非常方便地访问这些资源。
小结
一个ThreadLocal变量虽然是全局变量,但每个线程都只能读写自己线程的独立副本,互不干扰。ThreadLocal解决了参数在一个线程中各个函数之间互相传递的问题。
网络编程入门
网络基础这些概念太多太杂了,这里就不讲解了,可自行去了解
基于HTTP协议的网络资源访问
HTTP(超文本传输协议)
HTTP是超文本传输协议(Hyper-Text Transfer Proctol)的简称,维基百科上对HTTP的解释是:超文本传输协议是一种用于分布式、协作式和超媒体信息系统的应用层协议,它是万维网数据通信的基础,设计HTTP最初的目的是为了提供一种发布和接收HTML页面的方法,通过HTTP或者HTTPS(超文本传输安全协议)请求的资源由URI(统一资源标识符)来标识。关于HTTP的更多内容,我们推荐阅读阮一峰老师的《HTTP 协议入门》,简单的说,通过HTTP我们可以获取网络上的(基于字符的)资源,开发中经常会用到的网络API(有的地方也称之为网络数据接口)就是基于HTTP来实现数据传输的。
JSON格式
JSON(JavaScript Object Notation)是一种轻量级的数据交换语言,该语言以易于让人阅读的文字(纯文本)为基础,用来传输由属性值或者序列性的值组成的数据对象。尽管JSON是最初只是Javascript中一种创建对象的字面量语法,但它在当下更是一种独立于语言的数据格式,很多编程语言都支持JSON格式数据的生成和解析,Python内置的json模块也提供了这方面的功能。由于JSON是纯文本,它和XML一样都适用于异构系统之间的数据交换,而相较于XML,JSON显得更加的轻便和优雅。下面是表达同样信息的XML和JSON,而JSON的优势是相当直观的。
XML的例子:
<?xml version="1.0" encoding="UTF-8"?><message><from>Alice</from><to>Bob</to><content>Will you marry me?</content></message>
JSON的例子:
{"from": "Alice","to": "Bob","content": "Will you marry me?"}
requests库
requests是一个基于HTTP协议来使用网络的第三库,其官方网站有这样的一句介绍它的话:“Requests是唯一的一个非转基因的Python HTTP库,人类可以安全享用。”简单的说,使用requests库可以非常方便的使用HTTP,避免安全缺陷、冗余代码以及“重复发明轮子”(行业黑话,通常用在软件工程领域表示重新创造一个已有的或是早已被优化過的基本方法)。前面的文章中我们已经使用过这个库,下面我们还是通过requests来实现一个访问网络数据接口并从中获取美女图片下载链接然后下载美女图片到本地的例子程序,程序中使用了天行数据提供的网络API。
我们可以先通过pip安装requests及其依赖库。
已经设置好了环境变量,因为Python3自身带了pip,所以无需安装pip,直接在命令行进行安装操作,要使用pip,我们需要知道它的位置,在Python3的安装目录里有一个Scripts文件夹。
pip install requests
如果使用PyCharm作为开发工具,可以直接在代码中书写import requests,然后通过代码修复功能来自动下载安装requests。

若有收获,就点个赞吧
0 人点赞
