用程序来处理图像和办公文档经常出现在实际给工作当中,Python的标准库中虽然没有直接支持这些操作的模块,但我们可以通过Python生态圈中的第三方模块来完成这些操作。
处理Excel表格
Excel文档基本概念
- 工作簿(workbook): 一个 Excel 电子表格文档;
- 工作表(sheet): 每个工作簿可以包含多个表, 如: sheet1, sheet2等;
- 活动表(active sheet): 用户当前查看的表;
- 列(column): 列地址是从 A 开始的;
- 行(row): 行地址是从 1 开始的;
- 单元格(cell): 特定行和列的方格;
在openpyxl中,主要用到三个概念:Workbooks,Sheets,Cells。
- Workbook是一个excel工作表;
- Sheet是工作表中的一张表页;
- Cell是一页中的一个格;
Python的openpyxl模块让我们可以在Python程序中读取和修改Excel电子表格,由于微软从Office 2007开始使用了新的文件格式,这使得Office Excel和LibreOffice Calc、OpenOffice Calc是完全兼容的,这就意味着openpyxl模块也能处理来自这些软件生成的电子表格。
pip install openpyxl
openpyxl就是围绕着这三个概念进行的,不管读写都是 三板斧:打开Workbook,定位Sheet,操作Cell。
Python操作Excel写数据
import openpyxl # 导入类库# 1.创建工作簿Workbookwb = openpyxl.Workbook();# 2. 获取第一个工作表Sheet,并且修改标题描述sheet = wb.activesheet.title = '期末成绩'# 3. 写出该Excel文件wb.save("excelTest.xlsx")
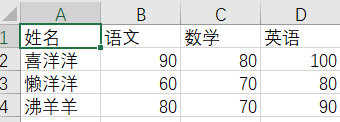
import randomimport openpyxl# 第一步:创建工作簿(Workbook)wb = openpyxl.Workbook()# 第二步:添加工作表(Worksheet)sheet = wb.activesheet.title = '期末成绩'# 第三步:循环往单元格写数据titles = ('姓名', '语文', '数学', '英语')for col_index, title in enumerate(titles):sheet.cell(1, col_index + 1, title)names = ('喜羊羊', '美羊羊', '懒羊羊', '暖羊羊', '沸羊羊','慢羊羊')for row_index, name in enumerate(names):sheet.cell(row_index + 2, 1, name)for col_index in range(2, 5):sheet.cell(row_index + 2, col_index, random.randrange(50, 101))# 第四步:保存工作簿wb.save('考试成绩表.xlsx')
enumerate:python的内置函数之一,用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
语法:
enumerate(sequence, [start=0])# 参数-- sequence:一个序列、迭代器或其他支持迭代对象。-- start:下标起始位置。
>>> seasons = ['Spring', 'Summer', 'Fall', 'Winter']>>> list(enumerate(seasons))[(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]>>> list(enumerate(seasons, start=1)) # 下标从 1 开始[(1, 'Spring'), (2, 'Summer'), (3, 'Fall'), (4, 'Winter')]
Python读取Excel数据
import openpyxl# 1、加载Excellwb = openpyxl.load_workbook('socre.xlsx')# 获取Excel中含有的工作表名称返回listprint(lwb.sheetnames)# 2、获取表单对象# ——方法一:根据名称获取值socre1 = lwb['socre1']# ——方法二:获取的表单返回的是list,所以可以通过索引取值socre2 = lwb.worksheets[1]# 3、获取单元格# ——方法一:获取得是单元格的对象“A1”,并非"A1"的值cell_object = socre1['A1']print(cell_object.value)# ——方法二:获取的是第一行第一列的值cell_object1 = socre2.cell(1, 1)print(cell_object1.value)print("------------------")# 表sheet中一共有多少行 结果:4行rows = socre1.max_rowprint(rows)# 表sheet一共有多少列 结果:6列cols = socre1.max_columnprint(cols)print("------------------")# 定义一个空列表 (下面需要装读取的最终内容)data_arr = []for i in range(1, rows + 1):tem_data = []for y in range(1,cols + 1):tem_data.append(socre1.cell(row = i,column = y).value)data_arr.append(tem_data)print(data_arr)print("------------------")# 行切片获取数据# 行切片 (索引从1开始,int类型,切片原则是,两边都包含,包含起始索引值和结束索引值)# min_row 起始行的索引值# max_row 结束行的索引值# min_col 起始列的索引值# max_col 结束列的索引值# values_only false:返回对象 true:返回单元格对应的数据# 列切片与行切片相同,列切片使用 .iter_colsresult = socre1.iter_rows(min_row=1, max_row=rows, min_col=1, max_col=cols, values_only=True)print(list(result))# 读完表后关闭Excellwb.close()
['socre1', 'socre2']姓名姓名------------------74------------------[['姓名', '语文', '英语', '数学'], ['喜洋洋', 90, 99, 100], ['沸羊羊', 60, 70, 80], ['懒洋洋', 66, 60, 90], ['美羊羊', 90, 92, 91], ['暖洋洋', 95, 97, 91], ['慢羊羊', 100, 100, 100]]------------------[('姓名', '语文', '英语', '数学'), ('喜洋洋', 90, 99, 100), ('沸羊羊', 60, 70, 80), ('懒洋洋', 66, 60, 90), ('美羊羊', 90, 92, 91), ('暖洋洋', 95, 97, 91), ('慢羊羊', 100, 100, 100)]
总结:还是如上方所说,三步走,获取工作簿,获取工作表、获取相应单元格。后续不管是读数据还是写数据都去获取到相应的单元去调整即可。
Python读写CSV
CSV文件介绍
CSV(Comma Separated Values)全称逗号分隔值文件是一种简单、通用的文件格式,被广泛的应用于应用程序(数据库、电子表格等)数据的导入和导出以及异构系统之间的数据交换。因为CSV是纯文本文件,不管是什么操作系统和编程语言都是可以处理纯文本的,而且很多编程语言中都提供了对读写CSV文件的支持,因此CSV格式在数据处理和数据科学中被广泛应用。
CSV文件有以下特点:
- 纯文本,使用某种字符集;
- 由一条条的记录组成(典型的是每行一条记录);
- 每条记录被分隔符(如逗号、分号、制表符等)分隔为字段(列);
- 每条记录都有同样的字段序列。
CSV文件可以使用文本编辑器或类似于Excel电子表格这类工具打开和编辑,当使用Excel这类电子表格打开CSV文件时,你甚至感觉不到CSV和Excel文件的区别。很多数据库系统都支持将数据导出到CSV文件中,当然也支持从CSV文件中读入数据保存到数据库中。

CSV库
[csv](https://docs.python.org/zh-cn/3.11/library/csv.html#module-csv) 模块中的 [reader](https://docs.python.org/zh-cn/3.11/library/csv.html#csv.reader) 类和 [writer](https://docs.python.org/zh-cn/3.11/library/csv.html#csv.writer) 类可用于读写序列化的数据。也可使用 [DictReader](https://docs.python.org/zh-cn/3.11/library/csv.html#csv.DictReader) 类和 [DictWriter](https://docs.python.org/zh-cn/3.11/library/csv.html#csv.DictWriter) 类以字典的形式读写数据。
csv.reader:以列表的形式返回读取的数据。csv.writer:以列表的形式写入数据。csv.DictReader:以字典的形式返回读取的数据。csv.DictWriter:以字典的形式写入数据。
csv.writer
csv.writer方法返回一个writer对象,该对象负责将用户数据转换为给定文件状对象上的定界字符串
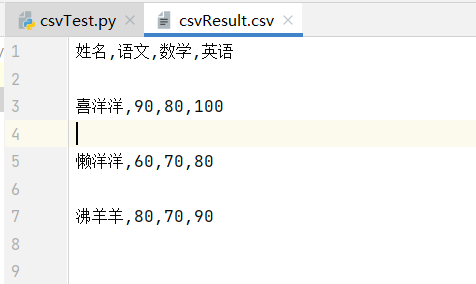
result = [['喜洋洋', '90', '80', '100'], ['懒洋洋', '60', '70', '80'], ['沸羊羊', '80', '70', '90']]with open('csvResult.csv', 'w') as file:writer = csv.writer(file)writer.writerow(['姓名', '语文', '数学', '英语'])writer.writerows(result)
该脚本将上方人物分数列和对应表标题写入到csvResult.csv文件中
writer.writerow:将一行数据写入到csv文件中
writer.writerows:将列表写入到csv文件中
结果如下:
csv.reader
csv.reader()方法返回一个reader对象,该对象将遍历给定CSV文件中的行。
with open('csvResult.csv', 'r') as f:reader = csv.reader(f);for r in reader:print(r)
结果:
['姓名', '语文', '数学', '英语'][]['喜洋洋', '90', '80', '100'][]['懒洋洋', '60', '70', '80'][]['沸羊羊', '80', '70', '90'][]
通过open打开csv文件,使用reader读取文件中的行数据
csv.DictReader
def __init__(self, f, fieldnames=None, restkey=None, restval=None,dialect="excel", *args, **kwds):
创建一个像普通阅读器一样操作的对象,将每行中的信息映射到 dict,其键由可选的 fieldnames 参数给出。
fieldnames 参数是一个序列。如果省略fieldnames,则读取文件 第一行中的值将用作字段名。不管字段名是如何确定的,字典都会保留它们的原始顺序。
如果一行的字段多于字段名,则将剩余数据放入列表中并使用 restkey 指定的字段名(默认为 None )存储。如果非空白行的字段少于字段名,则缺少的值为 filled-in,值为 restval(默认为 None )。
姓名,语文,数学,英语喜洋洋,90,80,100,100,100结果:{'姓名': '喜洋洋', '语文': '90', '数学': '80', '英语': '100', None: ['100', '100']}
读取的csv文件
姓名,语文,数学,英语喜洋洋,90,80,100懒洋洋,60,70,80沸羊羊,80,70,90
读取方法
with open('csvResult.csv', 'r') as f:reader = csv.DictReader(f);for r in reader:print(r)
结果
{'姓名': '喜洋洋', '语文': '90', '数学': '80', '英语': '100'}{'姓名': '懒洋洋', '语文': '60', '数学': '70', '英语': '80'}{'姓名': '沸羊羊', '语文': '80', '数学': '70', '英语': '90'}
csv.DictWriter
csv.DictWriter(f, fieldnames)。语法中的参数 f 是 open() 函数打开的文件对象;参数 fieldnames 用来设置文件的表头;
执行csv.DictWriter(f, fieldnames)后会得到一个 Writer 对象
得到的 Writer 对象可以调用 writeheader() 方法,将 fieldnames 写入 csv 的第一行;
最后,调用 writerows() 方法将多个字典写进 csv 文件中。
result = [{'姓名': '喜洋洋', '语文': '90', '数学': '80', '英语': '100'},{'姓名': '懒洋洋', '语文': '60', '数学': '70', '英语': '80'},{'姓名': '沸羊羊', '语文': '80', '数学': '70', '英语': '90'}]fieldnames = ['姓名', '语文', '数学', '英语']with open('csvResult.csv', 'w') as file:writer = csv.DictWriter(file, fieldnames)writer.writeheader()writer.writerows(result)
结果
姓名,语文,数学,英语喜洋洋,90,80,100懒洋洋,60,70,80沸羊羊,80,70,90
delimiter
上面介绍了最简单的读写操作,下面讲解下不是很规范的csv文件我们应该怎么处理
现在,假设CSV文件将使用 其他定界符。(严格来说,这不是CSV文件,但是这种做法很常见。)
例如,我们将上方csvResult.csv文件中的元素写出是由竖线字符(|)分隔,读取时根据竖线字符(|)读取为csv文件格式:
写入时设置分隔符 delimiter = “|” 写出的csv文件数据随之而变
result = [['喜洋洋', '90', '80', '100'], ['懒洋洋', '60', '70', '80'], ['沸羊羊', '80', '70', '90']]with open('csvResult.csv', 'w') as file:writer = csv.writer(file,delimiter="|")writer.writerow(['姓名', '语文', '数学', '英语'])writer.writerows(result)
姓名|语文|数学|英语喜洋洋|90|80|100懒洋洋|60|70|80沸羊羊|80|70|90
读取是就可以设置 delimiter,使用参数指定新的分隔字符。
示例:
with open('csvResult.csv', 'r') as f:reader = csv.reader(f,delimiter="|");for r in reader:print(r)
结果:
['姓名', '语文', '数学', '英语'][]['喜洋洋', '90', '80', '100'][]['懒洋洋', '60', '70', '80'][]['沸羊羊', '80', '70', '90'][]
Quoting
可以在CSV文件中引用单词。Python CSV模块中有四种不同的引用模式:
- QUOTE_ALL —引用所有字段
- QUOTE_MINIMAL-仅引用那些包含特殊字符的字段
- QUOTE_NONNUMERIC —引用所有非数字字段
- QUOTE_NONE —不引用字段
引用就是加上双引号

若有收获,就点个赞吧
0 人点赞
