javajavase
Collection接口:单列集合,用来存储一个一个的对象|----Set接口:存储无序的、不可重复的数据 -->数学概念上的“集合”|----HashSet:作为Set接口主要实现类,线程不安全,可以存null值|----LinkedHashSet:HashSet的子类,遍历内部数据时,按照添加顺序遍历遍历操作LinkedHashSet效率高于HashSet|----TreeSet:可以按照添加对象的指定属性,进行排序
Set接口是Collection的子接口,Set接口没有提供额外的方法
- Set集合不允许包含相同元素,把相同元素加入同一个Set集合中则添加失败,多用于过滤操作,去掉重复数据
- 用于存放无序的、不可重复的元素
- Set判断两个对象是否相同不是使用==运算符,而是根据equals()方法
要求:向Set(主要HashSet、LinkedHashSet)中添加数据,其所在的类一定要重写hashCode()和equals()
- 要求:重写的hashCode()和equals()尽可能保持一致性“相等的对象必须具有相等的散列码”
- 重写两个方法的小技巧:对象中用作equals()方法比较的 Field,都应该用来计算hashCode值
无序性、不可重复性的理解
以HashSet为例说明
- 无序性:不等于随机性。存的数据在底层数组中并非照元素添加顺序存放,而是由数据的哈希值决定的
不可重复性:保证添加的元素照equals()判断时,不能返回true。即:相同的元素只能添加一个
HashSet
Hashset是Set接口的主要实现类
HashSet按Hash算法来存储集合中的元素,因此具有很好的存取、查找、删除性能
HashSet具有以下特点不能保证元素的排列顺序
- HashSet不是线程安全的
- 集合元素可以是null
HashSet集合判断两个元素相等的标准
- 两个对象通过hashCode()与equals()两个方法一起确定相等
对于存放在Set容器中的对象,对应的类一定要重写equals()和hashCode(Object obj)方法,以实现对象相等规则。即:“相等的对象必须具有相等的散列码”
@Testpublic void test1() {Set set = new HashSet();set.add(456);set.add(123);set.add(123);set.add("AA");set.add("CC");set.add(new User("Tom",12));set.add(new User("Tom",12));set.add(129);Iterator iterator = set.iterator();while(iterator.hasNext()) {System.out.println(iterator.next());}}
元素添加过程
我们向HashSet中添加元素a,首先调用元素a所在类的hashCode()方法,计算元素a的哈希值
此哈希值接着通过某种算法计算出在HashSet底层数组中的存放位置(即为索引位置)
判断数组此位置上是否已经有元素
- 如果此位置上没有其他元素,则元素a添加成功 —->情况1
- 如果此位置上有其他元素b(或以链表形式存在的多个元素),则比较元素a与元素b的hash值
- 如果hash值不相同,则元素a添加成功 —->情况2
- 如果hash值相同,进而需要调用元素a所在类的equals()方法
- equals()返回true,元素a添加失败
- equals()返回false,则元素a添加成功 —->情况3
对于添加成功的情况2和情况3而言:元素a与已经存在指定索引位置上数据以链表的方式存储
JDK7:元素a放到数组中,指向原来的元素
JDK8:原来的元素在数组中,指向元素
总结:七上八下
HashSet底层:数组+链表的结构(JDK7以前)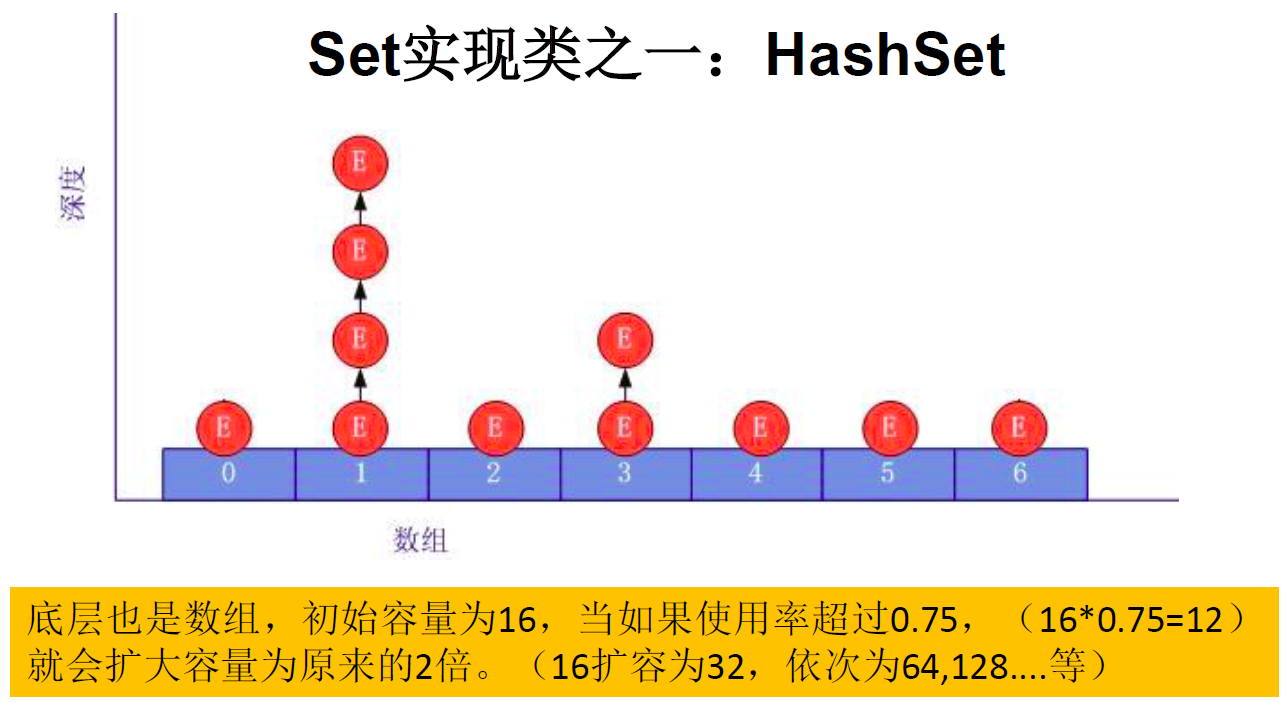
重写hashCode()的基本方法
- 在程序运行时,同一个对象多次调用hashCode()方法应该返回相同的值
- 当两个对象的equals()方法比较返回true时,这两个对象的hashCode()方法的返回值也应相等
对象中用作equals()方法比较的Field,都应该用来计算hashCode值
重写equals()方法基本原则
以自定义的Customer类为例,何时需要重写equals()?
- 当一个类有自己特有的“逻辑相等”概念,当改写equals()的时候,总是要改写hashCode(),根据一个类的 equals方法(改写后),两个截然不同的实例有可能在逻辑上是相等的,但是根据Object.hashCode()方法,它们仅仅是两个对象
- 因此违反了“相等的对象必须具有相等的散列码”
- 结论:复写equals方法的时候一般都需要同时复写hashCode方法,通常参与计算hashCode的对象的属性也应该参与到equals()中进行计算

@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;User user = (User) o;if (age != user.age) return false;return name != null ? name.equals(user.name) : user.name == null;}@Overridepublic int hashCode() { // return name.hashCode() + age;int result = name != null ? name.hashCode() : 0;result = 31 * result + age;return result;}
LinkedHashSet
LinkedhashSet是HashSet的子类
- 在添加数据的同时,每个数据还维护了两个引用,记录此数据前一个数据和后一个数据
- 优点:对于频繁的遍历操作,LinkedHashSet效率高于HashSet
- LinkedhashSet不允许集合元素重复
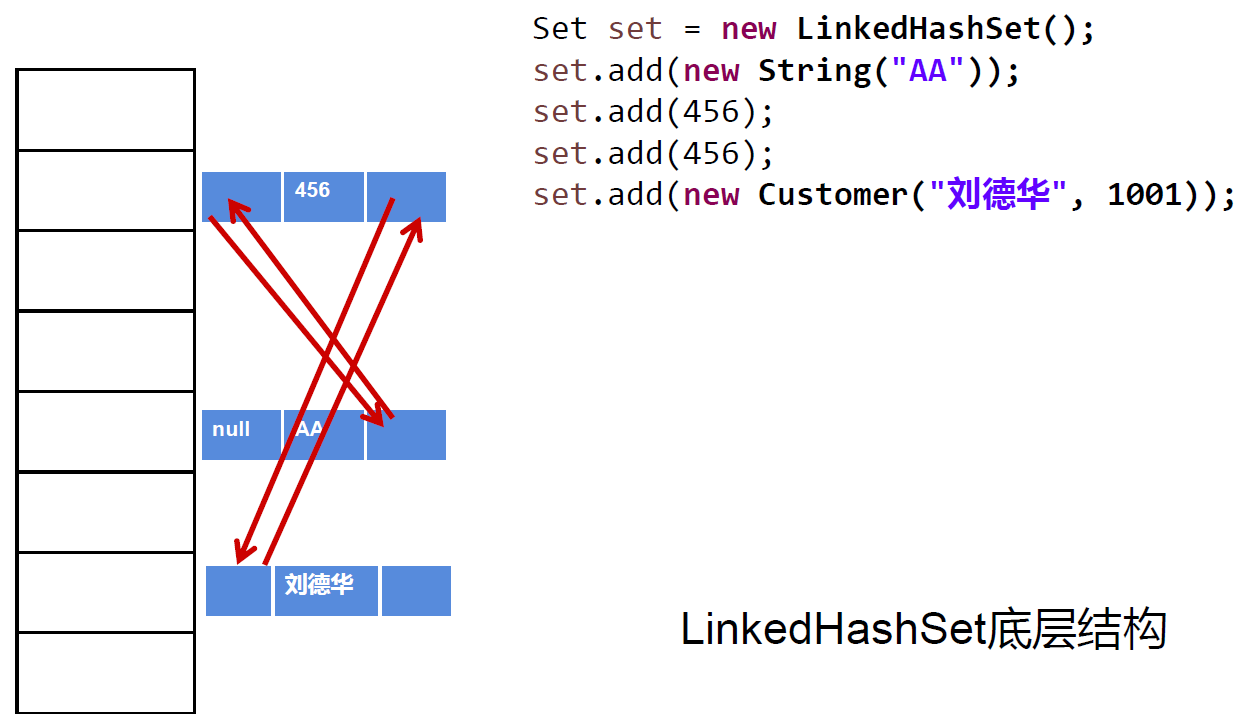
@Testpublic void test() {Set set = new LinkedHashSet();set.add(456);set.add(123);set.add(123);set.add("AA");set.add("CC");set.add(new User("Tom",12));set.add(new User("Tom",12));set.add(129);Iterator iterator = set.iterator();while(iterator.hasNext()){System.out.println(iterator.next());}}
TreeSet
TreeSet是SortedSet接口的实现类,TreeSet可以确保集合元素处于排序状态
TreeSet底层使用红黑树结构存储数据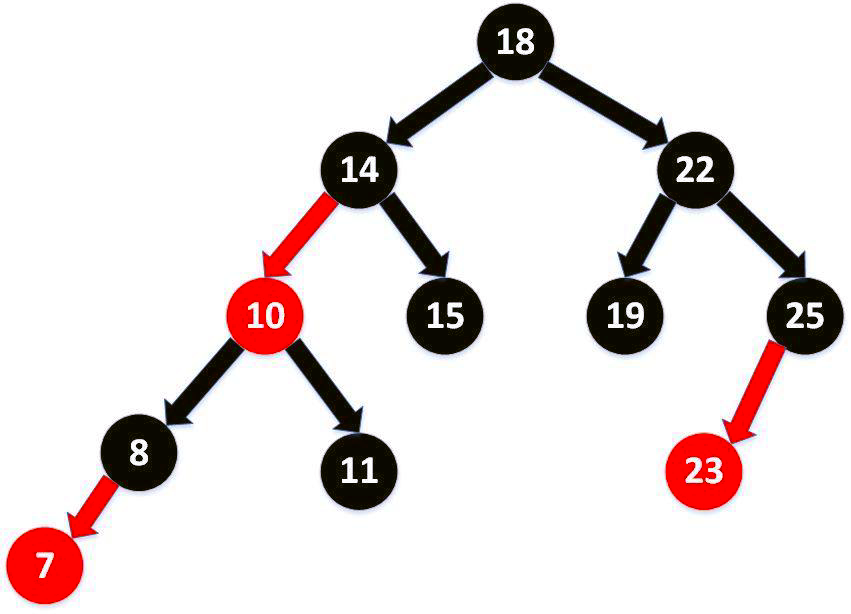
红黑树的特点:有序,查询效率比List快
详细介绍:https://www.cnblogs.com/LiaHon/p/11203229.html
新增的方法如下(了解)**Comparator comparator()****E first()****E last()****E lower(object e)**返回此集合中的最大元素严格小于给定元素,或者null如果没有这样的元素**E higher(object e)****SortedSet subSet(fromElement, toElement)****SortedSet headSet(toElement)****SortedSet tailSet(fromElement)**
使用说明
- 向TreeSet中添加的数据,要求是相同类的对象
- 两种排序方式:自然排序(实现Comparable接口)和定制排序(Comparator)
自然排序
TreeSet会调用集合的compareTo(object obj)方法来比较元素之间的大小,然后将集合元素按升序(默认)排列
- 如果试图把一个对象添加到TreeSet时,则该对象的类必须实现Comparable接口
- 实现Comparable的类必须实现compareTo(Object obj)方法,通过compareTo()方法的返回值来比较大小
- 向TreeSet中添加元素时,只有第一个元素无须比较compareTo()方法,后面添加的所有元素都会调用compareTo()方法进行比较
因为只有相同类的两个实例才会比较大小,所以向TreeSet中添加的应该是同一个类的对象。 对于TreeSet集合而言,它判断两个对象是否相等的唯一标准是:两个对象通过compareTo(Object obj)方法比较返回值 当需要把一个对象放入TreeSet中,重写该对象对应的equals()方法时,应保证该方法与compareTo(Object obj)方法有一致的结果:如果两个对象通过equals()方法比较返回true,则通过compareTo(object ob)方法比较应返回0。否则,让人难以理解
Comparable的典型实现
- BigDecimal、BigInteger以及所有的数值型对应的包装类:按它们对应的数值大小进行比较
- Character:按字符的unicode值来进行比较
- Boolean:true对应的包装类实例大于fase对应的包装类实例
- String:按字符串中字符的unicode值进行比较
Date、Time:后边的时间、日期比前面的时间、日期大
@Testpublic void test1() {TreeSet set = new TreeSet();//失败:不能添加不同类的对象// set.add(123);// set.add(456);// set.add("AA");// set.add(new User("Tom",12));//举例一:// set.add(34);// set.add(-34);// set.add(43);// set.add(11);// set.add(8);//举例二:set.add(new User("Tom",12));set.add(new User("Jerry",32));set.add(new User("Jim",2));set.add(new User("Mike",65));set.add(new User("Jack",33));set.add(new User("Jack",56));Iterator iterator = set.iterator();while(iterator.hasNext()) {System.out.println(iterator.next());}}
定制排序
如果元素所属的类没有实现Comparable接口,或不希望按照compareTo()排序而希望按照其它属性大小进行排序,则考虑使用定制排序
定制排序,通过Comparator接口来实现。需要重写**compare(T o1,T o2)**方法要实现定制排序,需要将实现Comparator接口的实例作为形参传递给TreeSet的构造器
- 仍只能向TreeSet中添加类型相同的对象。否则发生ClassCastException异常
- 利用compare(T o1,T o2)方法,比较o1和o2的大小
如果方法返回正整数,则表示o1大于o2;如果返回0,表示相等;返回负整数,表示o1小于o2
@Testpublic void test2() {Comparator com = new Comparator() {// 照年龄从小到大排列@Overridepublic int compare(Object o1, Object o2) {if(o1 instanceof User && o2 instanceof User) {User u1 = (User)o1;User u2 = (User)o2;return Integer.compare(u1.getAge(),u2.getAge());} else {throw new RuntimeException("输入的数据类型不匹配");}}};TreeSet set = new TreeSet(com); // 注意带参构造器接收的是一个Compatatorset.add(new User("Tom",12));set.add(new User("Jerry",32));set.add(new User("Jim",2));set.add(new User("Mike",65));set.add(new User("Mary",33));set.add(new User("Jack",33));set.add(new User("Jack",56));Iterator iterator = set.iterator();while(iterator.hasNext()) {System.out.println(iterator.next());}}
面试题
存储对象所在类的要求
HashSet/LinkedHashSet
- 要求:向Set(HashSet、LinkedHashSet)中添加的数据,其所在的类一定要重写hashCode()和equals()
- 要求:重写的hashCode()和equals()尽可能保持一致性:相等的对象必须具有相等的散列码
重写两个方法的小技巧:对象中用作equals() 方法比较的Field,都应该用来计算hashCode值
TreeSet
- 自然排序中,比较两个对象是否相同的标准为:compareTo()返回0.不再是equals()
- 定制排序中,比较两个对象是否相同的标准为:compare()返回0.不再是equals() ```java public static List duplicateList(List list) { HashSet set = new HashSet(); set.addAll(list); return new ArrayList(set); }
@Test public void test2() { List list = new ArrayList(); list.add(new Integer(1)); list.add(new Integer(2)); list.add(new Integer(2)); list.add(new Integer(4)); list.add(new Integer(4));
List list2 = duplicateList(list);for (Object integer : list2) {System.out.println(integer);}
}
@Test public void test3() { HashSet set = new HashSet(); Person p1 = new Person(1001, “AA”); Person p2 = new Person(1002, “BB”); set.add(p1); set.add(p2); System.out.println(set);
p1.name = "CC";set.remove(p1); // HashSet 一定是先hashCode() 再equals()System.out.println(set); // 此时还是两个set.add(new Person(1001,"CC"));System.out.println(set); // 3个set.add(new Person(1001,"AA"));System.out.println(set); // 4个
} ```

若有收获,就点个赞吧
0 人点赞
