算法评价(20210314)
快速排序的时间复杂度是O(nlongN),而冒泡排序的时间复杂度是O(N)。比较起来,看似快速排序的时间复杂度最高。
由于快速排序的实质是递归,所以随着规模的增大,有可能超过最大可递归深度,需要单独修改;
算法复杂度最坏的情况描述:
知识点延伸
1,装饰器; 2, 深度复制; 3,如何给递归增加装饰器; 4, 修改最大可递归深度;
5, 需要参考分治法
快速排序的原理
在一个小区域内重新排序,递归小区域,得到整个列表的排序
排序是波峰状的,中间的数字是一个中值,左边都比中间小,右边都比中间大
三个默认参数,一个是列表,一个是左端点值,一个是右端点值
两个极值用来确定排序算法执行的数据范围
每实现一次交换,指针的索引值就需要加一,左边最小区的指针就要向右移动,右边最大区的指针移动方向则反之
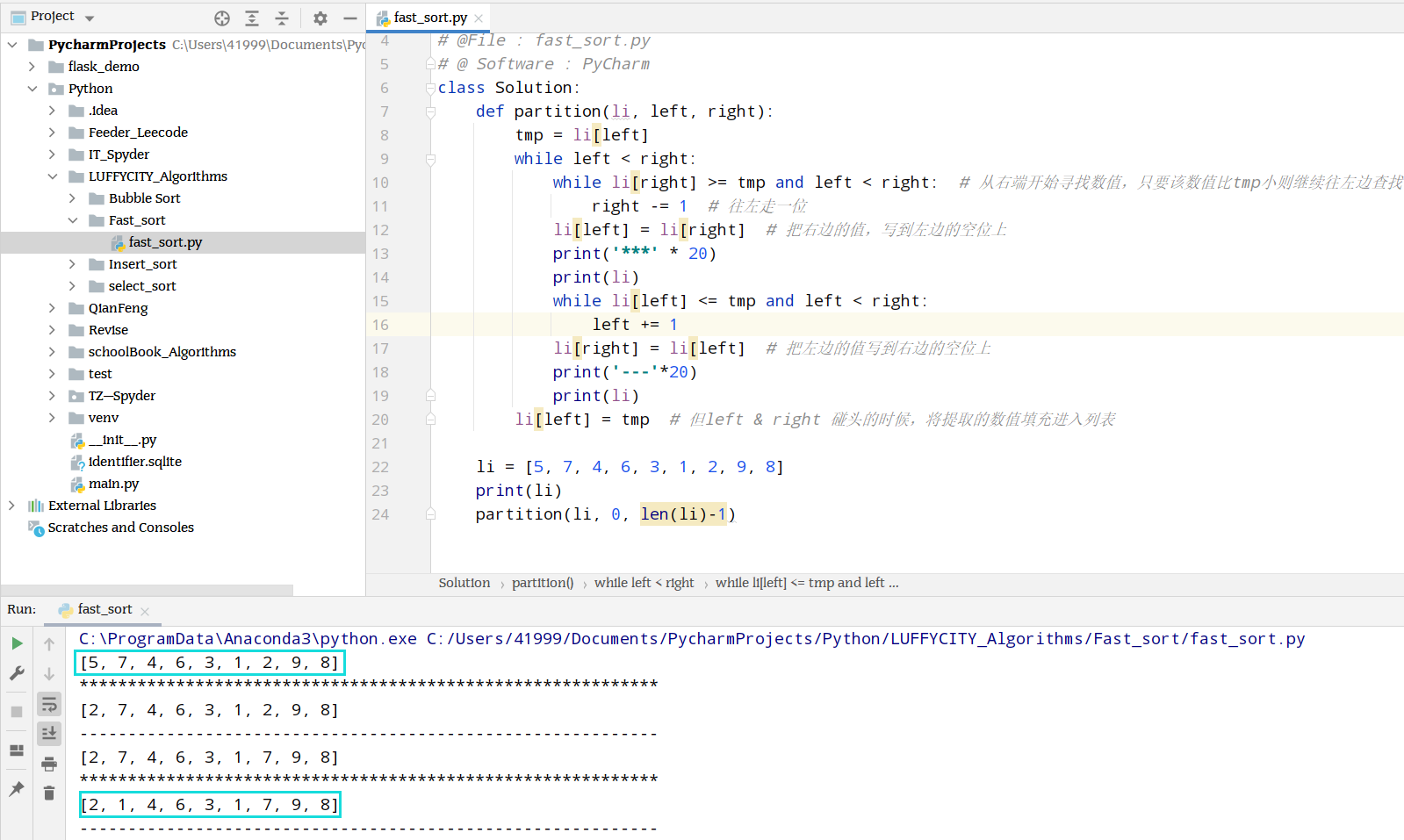
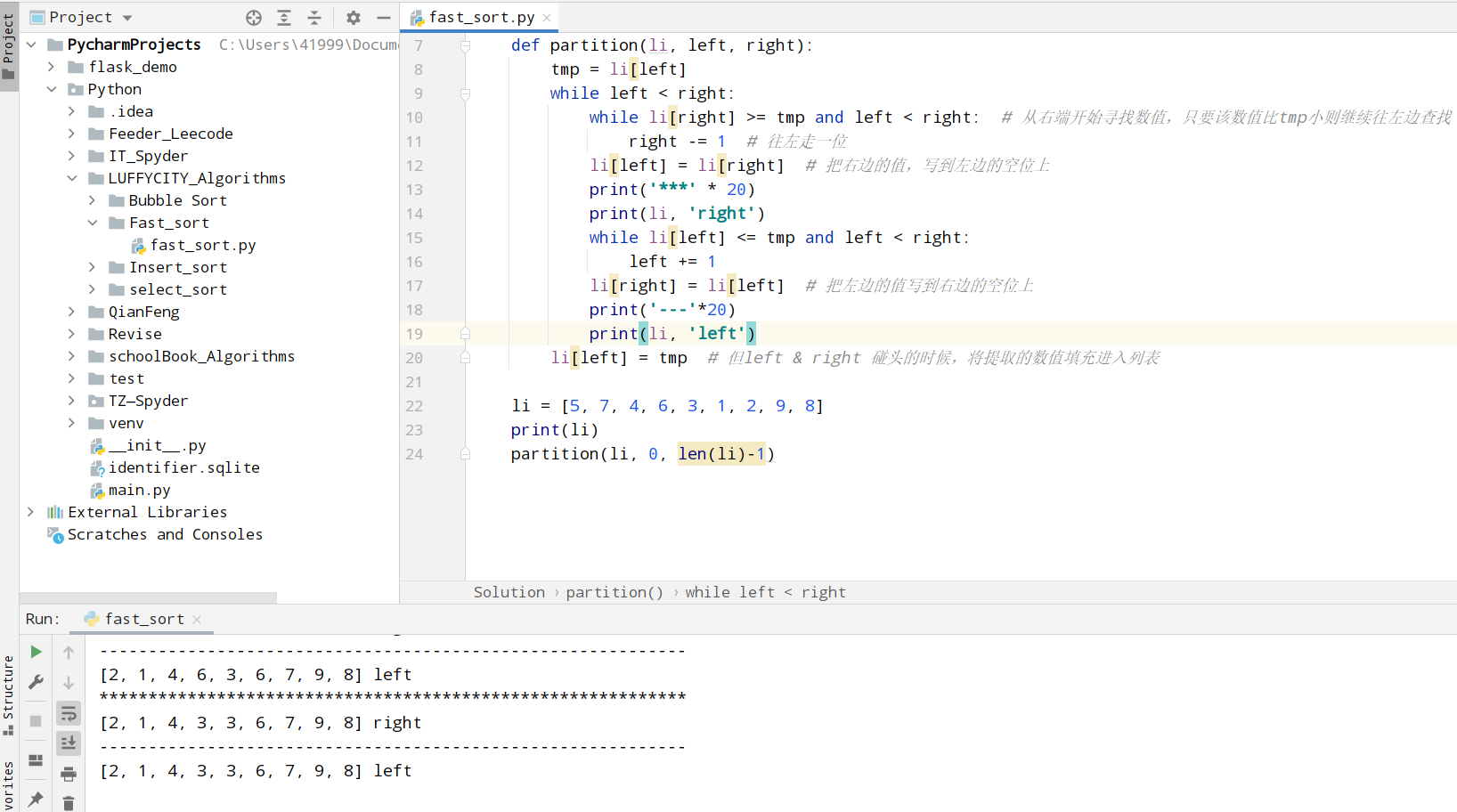
算法实现
选取第零个位置的元素作为标的,将默认参数中的左指针作为标的, 在最坏算法复杂度中,我们会随机指定一个标的,所以左指针不一定是零位置的元素
循环遍历列表中的元素,成立的条件是左指针永远小于右指针
当排序完成,我们要将取出作为标的的元素,重新填充进列表。由于俩指针相遇,即搜索过程中的匹配完成,所以填充的位置就是left和right两个指针相遇的地方,左指针,右指针均可
开始在右边区域寻找比标的小的元素,遍历到的元素,它的值大于标的,就要往左边继续寻找,如果在右边的区域找到一个比标的小的数据,则将数据填充给左指针
在左边的区域寻找比标的大的元素,遍历到的元素如果小于标的,那么继续往右边寻找,如果找到大于标的的元素,则将元素交给右指针,右指针向左移动一个位置
考虑极限情况, 如果右边的数据都比标的大,那么循环完成,右边的指针就和左边的指针碰到一起;
执行条件分析
left < right说明至少有两个元素,left等于right只有一个元素


若有收获,就点个赞吧
0 人点赞
