Generative Adversarial Network
1.基本概念介绍
1.Genrator Model
generative model不只是有GAN,还有FLOW-based model、Variational Autoencoder(VAE)。
生成式网络不一样的地方是,现在网络的输入会加上一个随机变量z,这个z是从某个Distribution中sample出来的。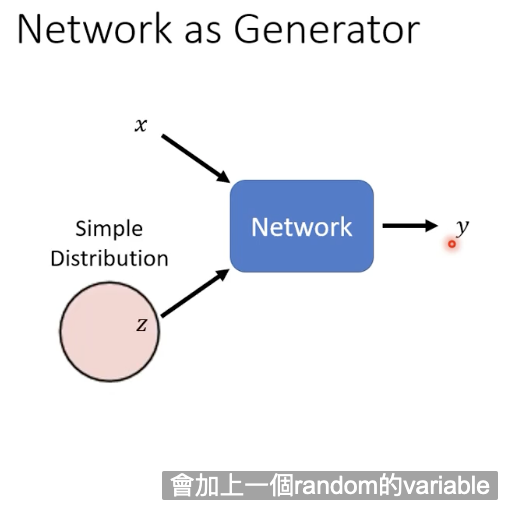
同样的x作为输入,我们每次从分布中sample到不一样的z,经过复杂的Network转换后,生成的结果就会变成一个复杂的分布,我们的Network的输出就变成了一个复杂的Distribution。
这种能够输出一个Distribution的Network我们就叫它Generator。
有时候,我们希望网络的输出不是一个固定的值,而是一个分布。
比如吃豆人游戏,我们希望网络能够预测接下来是左转还是右转,而我们的训练资料里从当前状态出发,既有左转的、又有右转的,我们的机器就会觉得向左、向右都是对的,就会分裂开来,同时向左向右,而我们的期望是从中选一个方向。
那么,怎么处理这个问题呢?一个可能性就是,让机器的输出是有概率的,让它不再输出一个单一的输出,让它输出一个几率的分布。
当我们给这个网络加上一个z的时候,它的输出就不再是固定的了,而是一个分布。
那么,什么时候,我们需要这种generator的model呢?
当我们的任务需要一点创造力的时候。(我们想找到一个function,对于同样的输入有不同的输出,而这些不同的输出都是对的)。
eg:聊天机器人。
2.GAN
Generator Model中一个比较知名的就是Generative Adversarial Network(GAN)。
现在GAN网络已经有超过500种变体了,每加一个变体,就在前面加个英文字母。
1.Unconditional generation
Unconditional generation的输入是一个Distribution,输出是另一个Distribution。
我们假设z是从正态分布中sample出来的一个向量。我们自己选的输入方的distribution可以是简单的distribution,如正态分布;而Generator会想办法对应到一个复杂的distribution。
在二次元图像生成任务中,generator做的事情就是输入一个低维向量,输出一个具有概率分布的高维向量。
除了要训练Generator之外,我们还要多训练一个东西,这个东西是Discriminator(辨别器) 。
这个Discriminator也是一个神经网络,它的作用是输入一张图片,输出一个标量,标量越大,说明这个图像越接近二次元。像这个问题中,输入是图片,那我们很可能用CNN的架构来设计Discriminator。
第一代的Generator的参数是随机的,产生出来的都是一些杂讯,而Discriminator辨别二次元头像的方式是看有没有眼睛;然后第二代的Generator就会想办法骗过第一代的Discriminator,产生出眼睛,而二代Discriminator就会对比Generator产生的图片和真实图片之间的差异,发现生成的图片都是没有嘴巴的;然后第三代生成图片有了嘴巴,想办法骗过第二代Discriminator…
他们之间的关系就像是捕食者(Discriminator)和被捕食者(Generator),所以就用了Adversarial(对抗)来描述他们之间的关系。
算法过程
- 初始化generator和discriminator。
在每一次迭代中:
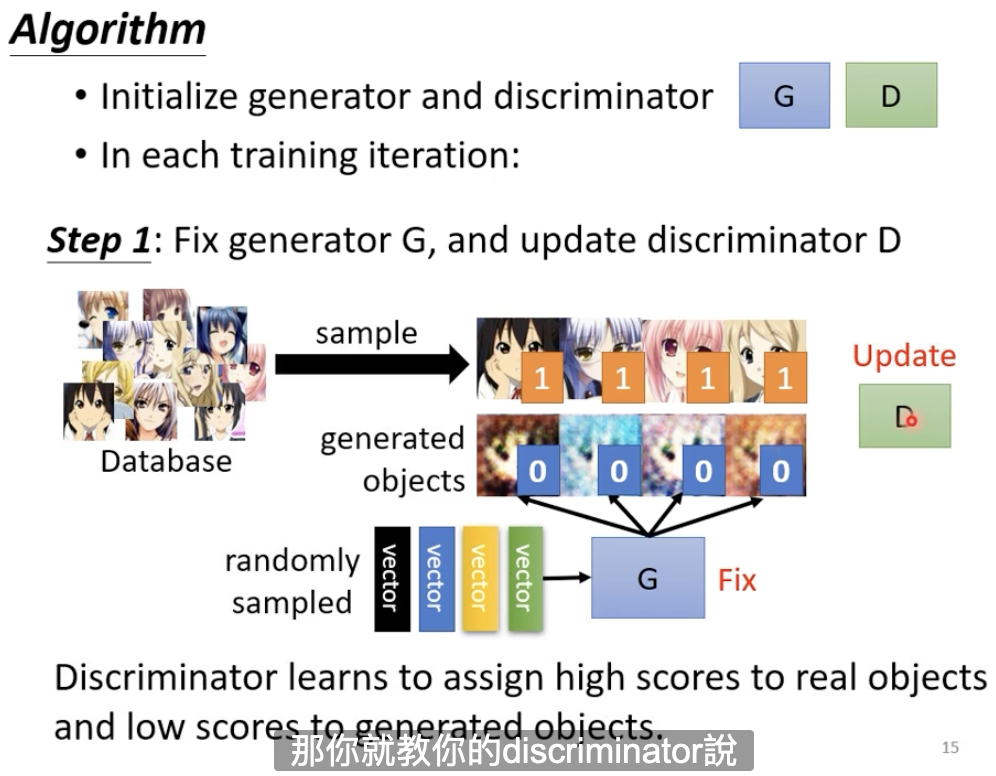
固定住generator,更新discriminator。
- 我们从高斯分布(正态分布)中sample出一些向量,输入到generator中,因为generator的参数是随机输出化的,所以产生出来的图片都是杂讯;
- 从数据库中sample出来一些真实的二次元头像
将generator出的图片和真实图片丢给Discriminator进行训练。Discriminator的目标是发现两者之间的差异。
固定住discriminator,更新generator。因为刚才discriminator已经学会了分别真图和假图之间的差异,generator的目标是骗过discriminator。
<br />假设**generator的网络有5层,discriminator的网络有5层,把两个网络接起来,其中某一层的hidden layer的大小刚好是图片大小,我们把这一层hidden layer的输出拿出来作为图片。我们的目标是不改变discriminator参数的同时,调整generator的参数,让整个网络最终的打分越高越好。**<br /> 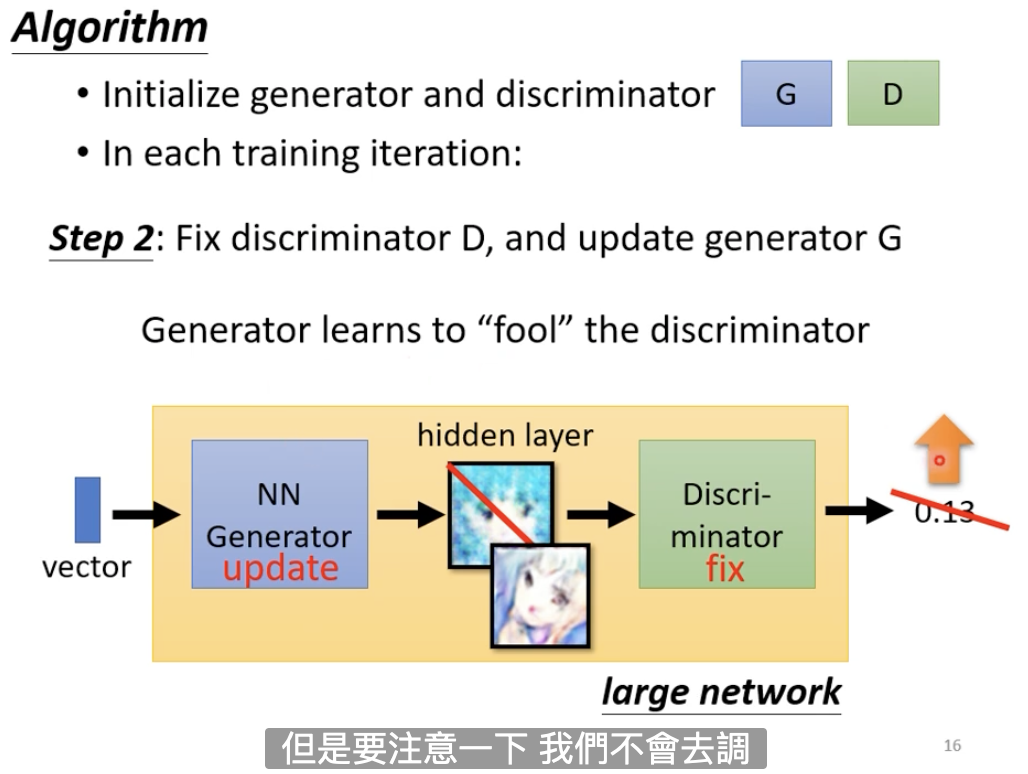<br />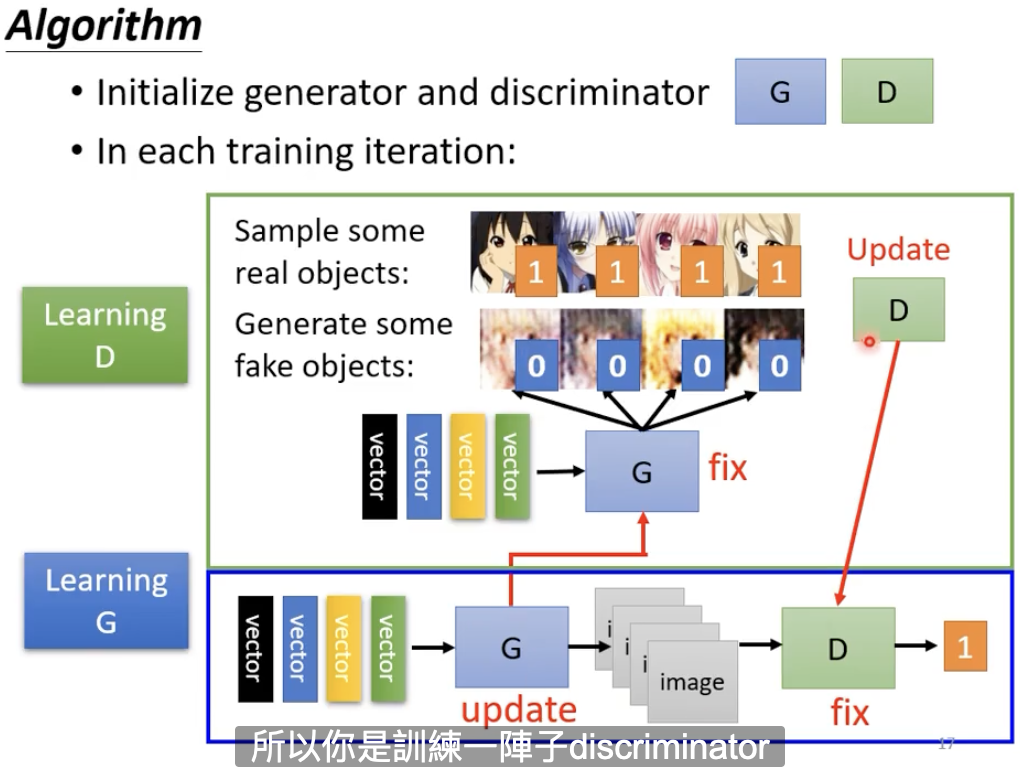
2.理论介绍与WGAN
Pg是Generator处理后的分布,Pdata是真实数据的分布。我们的目标是让Pg和Pdata之间的散度(Divergence)越小越好。
可是,我们根本无法算出这个Divergence,该怎么找到一个Generator去Minimize这个Divergence?
GAN告诉我们,只要我们能从Pg和Pdata里面sample出来东西,就能够算Divergence。我们不需要知道Pg和Pdata实际的formulation是什么样的就能够算Divergence。

Discriminator的目标是看到来自Pdata的图片打高分,看到来自Pg的图片打低分。所以其作用就是最大化下面的V(D,G)。其中D(y)是Discriminator给图片打的分。
我们发现V(D,G)前面加上负号就是BCELoss,问题就可以转化为最小化loss。所以,我们可以像训练二分类一样,训练Discriminator。
之前,我们不知道该怎么计算Pg和Pdata之间的散度。现在,我们知道可以利用V(D,G)来间接的计算Divergence。

之前Generator和Discriminator之间的对抗过程的目标就是达到这么一种效果。当固定Generator时,让Discriminator发现生成图片和真实图片之间的差异(MAX);当固定Discriminator时,让Generator学会欺骗Discriminator,即减小Pg和Pdata之间的散度(MIN)。
1.JS Divergence is not suitable
我们知道,Pg和Pdata之间重叠的部分其实是很小很小的。
-2plogp p=1/2。 -log1/2 = log2
对于JS Divergence来说,只要Pg和Pdata没有重叠,就意味着Pg和Pdata彼此独立,则它们俩之间的信息熵就是log2。(-2plogp p=1/2。 -log1/2 = log2)
但是我们人眼能够看出来,中间的这个效果比左边的好啊,但是JS不知道。因为JS不知道,所以,在train的时候,update参数时就不会从左边的这种情况变成中间的这种情况。
如果Pg和Pdata之间完全没有重叠,我们用二分类来训练Discriminator的话,只要训练下去,一定能达到100%的准确率。这种情况的话,每次迭代Discriminator的accurancy都是100%,这个值对于Generator来说,没有什么帮助,因为我们不知道此次迭代Generator有没有提升。
2.Wasserstein Distance->WGAN
把P挪到Q位置的平均移动距离就是Wasserstein Distance。
当我们用Wasserstein Distance取代JS divergence时,我们的GAN就是WGAN。
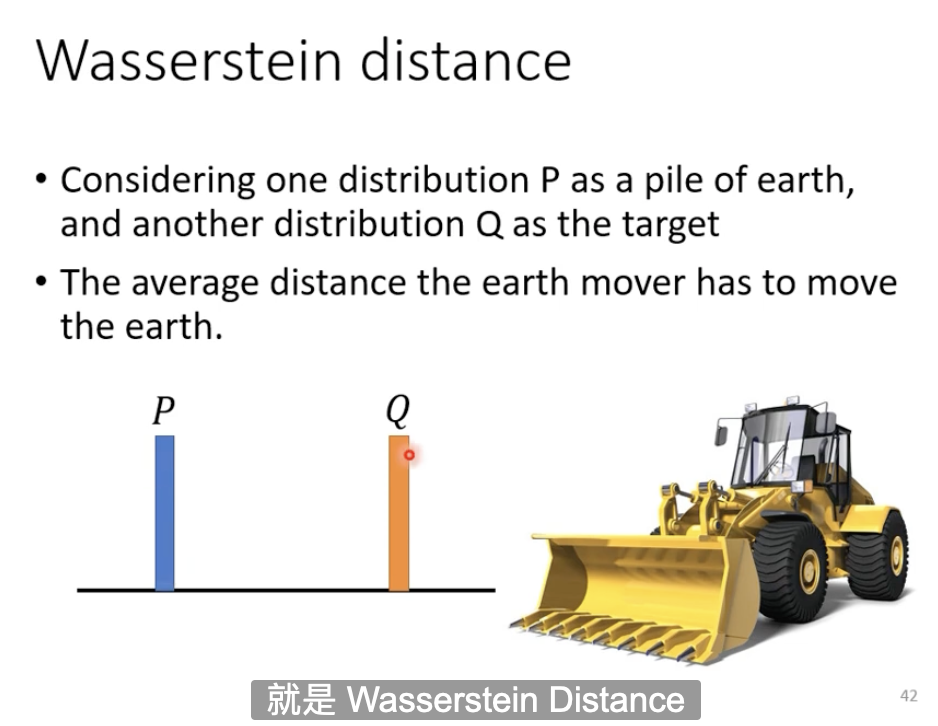
因为推土的方式有很多种,即有多种方式把P变成Q,那么,哪个才是Wasserstein Distance呢?
推土问题平均移动距离最短的最优解就是Wasserstein Distance。
使用Wasserstein Distance的话,就能够对左边的图和中间的图进行比较了,就能看出中间的图效果更好。
Wasserstein Distance的计算公式是下面这个,其中,方法D是一个足够平滑的函数,目标是看到真实的图片打高分,看到生成图片打低分;但是,我们要用一个平滑的函数限制,防止看到真实图片给∞,看到生成图片给-∞;
因为D足够平滑,如果生成图片和真实图片距离很近,就没有办法让真实图片分很大,生成图片分很低,这就说明Generator生成能力比较强。

3.生成器效能评估和条件式生成
GAN应用于文字生成比较难。
Seq2Seq模型可以看作是Generator;Discriminator对生成的文字打分。
当Decoder的参数有微小的变化时,Generator输出的文字并没有什么变化,这就导致整个网络的输出,也就是Discriminator的打分没有变化,这就导致没有办法用梯度下降的方式更新参数。
1.评估
刚开始的时候,评估的方式是用人眼来看,但是不客观,评价标准不一样。
在作业6里面,会用一个动画人物人脸监测系统,来监测生成的图片里面有多少动画人物的人脸。
针对其他任务,我们也可以跑一个图像分类系统,输入图片,输出标签,当分布比较集中时,说明生成效果比较好。
但是,只用这一种评估方式并不太行,会出现Model Collapse(模型崩溃)的事情,也就是说,生成的图片只是接近真实图片分布的一小块区域,这个地方产生的图片都能够骗过Discriminator,所以,产生的图片就一直围绕这个区域。

衡量多样性:生成1000张图片,丢到图片识别系统中,看分布。分布平均,说明多样性够。感觉好像和前面的Quality评估有冲突。
Quality评估是针对一张图片的分布,要求集中;而Diversity看的是一堆图片,要求一堆图片的分布平均。
2.Conditional Generator
Conditional Generator的输入是x和一个随机分布z,希望能够操控Generator的输出。
eg:Text-to-Image 监督学习问题
x:文字; z:概率分布
每次生成的图片不一样,这个取决于sample出来的z。

Generator的输入是文本x和正态分布中sample出来的向量z,输出是一张图片。
如果Discriminator的输入只是Generator的输出的话,Discriminator的作用就是判断图片是真实的还是生成的。Generator会产生能够骗过Discriminator的非常清晰的图片,但是跟输入x完全没有任何关系。
所以,Discriminator的输入应该包括文本x和生成的图像y,只有当y足够真实且和x配对的时候,才能打出高分。
3.GAN用在Unsupervised Learning
如果完全没有标注的资料,该怎么使用GAN?
Cycle GAN:
Cycle GAN有两个generator,一个generator看到x-domain里的图输出y-domain的图;另一个generator看到y-domain里的图输出x-domain的图;我们希望经过两次转换后,输入和输出越接近越好。
当然,看起来似乎生成的图片仍然可能会跟输入人脸没太大关系。比如,第一个generator的作用是看到眼镜换成一颗痣;第二个generator做反向操作。
但是,这种情况不容易出现;甚至于在实际操作时,即便我们只有一个Generator去做无监督学习,仍然会得到一个比较好的结果。
真正的Cycle GAN,还需要反过来训练,输入动画头像,输出真实人脸。


若有收获,就点个赞吧
0 人点赞
