- https://www.qingfenghangzhou.com/cn/?a=dnxe2#zero
 ">https://www.qingfenghangzhou.com/cn/?a=dnxe2#zero
">https://www.qingfenghangzhou.com/cn/?a=dnxe2#zero - 1.高偏差与高方差(欠拟合)
- 2.CNN与Fully-connection NN
- 3.N折交叉验证-用于模型选择或模型评估。
- ">

- 4.怎么判断当前是陷入局部最小值(local minimize),还是鞍点(saddle point)?
- 5.Mini-batch的优势
- 6.学习率-LearningRate的影响
- 7.Batch Normalization-批次标准化
- 8.Optimizer算法
- 9.由贝叶斯到sigmoid
https://www.qingfenghangzhou.com/cn/?a=dnxe2#zero
1.高偏差与高方差(欠拟合)
高偏差
原因:
- 模型太简单
- 梯度下降没有优化好,应该迭代更多的次数
高方差:
原因:
- 在训练集上loss小,测试集上loss大
- 过拟合—-可以搜集更多的数据、或者使用数据增强、或减少特征数量、早停、正则化、dropout、减少参数。
- 数据不匹配(即测试集和训练集的数据分布不同)
为了判断bias和square,我们可以先用一个浅层神经网络训练或者不用神经网络,用传统的机器学习方法,如线性模型或者SVM的方式,进行一个快速的训练,作为对照。
2.CNN与Fully-connection NN
CNN相比于全连接神经网络来说,不是那么有弹性,它会根据图片的特性来限制模型的弹性。
3.N折交叉验证-用于模型选择或模型评估。
在划分trainset和devset时,一般是将trainsetshuffle,然后分出10%作为devset,为了避免偶然性因素,我们可以把训练集分为N份,其中N-1份拿来训练,1份拿来测试。
eg:十折交叉验证。
模型评估:9份作为trainset,1份作为devset。把模型跑10次。对devset结果求平均。
模型选择:如果我们有3个模型,每个模型上跑一遍十折交叉验证,对devset结果求平均,选出最好的模型。(3个模型一般是指三个超参数不同的模型,看看不同的超参数选择的影响)
4.怎么判断当前是陷入局部最小值(local minimize),还是鞍点(saddle point)?
对critical point点进行二阶求导,判断是不是极值点。
求海塞矩阵的特征值,即使|H-λE|行列式的值为标量λ的值。
当λ全为正数=》陷入局部最小值
当λ全为负数=》陷入局部最大值
当λ有正有负=》陷入鞍点



5.Mini-batch的优势
mini-batch的大小一般根据GPU的核数确定,有几个核,mini-batch就设置多大,充分利用计算资源。
mini-batch在优化时,表现的更好。因为,相比于full batch,不容易陷入鞍点附近。因为,可能对于整个trainset来说,在鞍点附近,优化速度缓慢;但是 ,对于mini-batch来说,有noisy反而是优点,每次选用不同的mini-batch,可能参数对于 一个mini-batch靠近鞍点,但对其他的不是。所以,使用mini-batch优化速度更快。


6.学习率-LearningRate的影响
当我们的loss不再下降时,首先要去看一下我们的gradient是什么样的。不一定是卡在critical point。下面图示中,虽然loss已经很小了,但是gradient仍然还有比较明显的上跳,gradient也不是很小,这是,我们就可能陷入了左边的这种情况,即来回反复横跳。
learning_rate的自动调整:
如果在某一个方向上的gradient值很小,我们就增大这个方向的学习率。
如果在某一个方向上的gradient值很大,我们就减小这个方向的学习率。
具体实现方式,用原有的learning_rate除以之前计算过的梯度的均方根误差。这个方法被用在优化算法Adagrad中。——之前的每个gradient具有相同的权重
原理解释:
如果gradient小,RMS就小,因为RMS在分母上,就会放大这个方向上的学习率;
如果gradient大,RMS就大,因为RMS在分母上,就会缩小这个方向上的学习率;
RMSProp:之前的gradient权重不同,标号越小的,权重越小
学习率衰减:无论是RMSprop、Momentum还是Adam,它的输入的学习率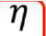 是不变的。当然,各个方向的学习率会有变化(加速度)。而随着时间的变化,我们希望学习速率变小,希望缓慢逼近最优值,就可以让
是不变的。当然,各个方向的学习率会有变化(加速度)。而随着时间的变化,我们希望学习速率变小,希望缓慢逼近最优值,就可以让 和时间相关,成为
和时间相关,成为 ,
,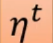 会随着时间越来越小。
会随着时间越来越小。

现在的优化方法,一般需要同时考虑时间、放缓步伐以及平均方向。
Momentum的作用是加速下降,RMS是平缓梯度,但是Momentum的另一个作用是确定梯度下降的方向。所以,他们并不会抵消。
7.Batch Normalization-批次标准化
问:为什么叫batch Normalization?
因为一般情况下数据量很大,我们不会一次性把所有数据加载到内存中,一次只会加载一个mini-batch,所以,是对一个batch 进行标准化,所以叫做Batch Normalization。
如果x1很小,那么deltaw1 * x1就很小,对y_hat的影响就比较小,就会对loss影响小,所以,要对特征进行归一化。
均值化之后,平均值为0,方差为1。
当然,经过一层的hidden layer处理之后,输出就不再服从N(0,1)分布了。
每一层都进行标准化。可以对Z标准化,也可以对A标准化。
因为均值为0,所以,为了防止神经网络学习到这个特性,对训练结果产生什么不好的影响,引入两个参数β和γ。(Lhy说,当模型训练的loss比较小时,再加入β和γ参数???)
优化方法不只是Batch Normalization,还有以下的可参考。
8.Optimizer算法

1.Adam和SGDM的比较
- Adam:训练比较快,但是泛化能力没那么强,不稳定。
- SGDM:稳定,泛化能力较强 ,更好收敛。

2.Adam with Warm up
让Adam先变大,再变小。
优点:
- 有助于减缓模型在初始阶段对mini-batch的提前过拟合现象,保持分布的平稳
- 有助于保持模型深层的稳定性
9.由贝叶斯到sigmoid



若有收获,就点个赞吧
0 人点赞
