1.什么是seq2seq呢?
输入是一个序列,输出是一个序列,且输出序列的长度由模型来决定。
一个模型,输入台语、输出中文文字,就是语音辨识;
一个模型,输入文字,输出语音讯号,就是语音合成。
Seq2Seq在NLP的领域使用相当广泛,其实很多自然语言处理的任务都可以当作是QA任务。所谓的QA就是给机器一段文字,希望它能够给你一个正确的答案。而很多可能我们觉得和QA没什么关系的任务都可以想象成是QA。比如翻译,机器读入的是一段英文句子,那么问题就是这个句子的中文翻译是什么;比如文本摘要,机器读入的是文档,那么问题就是这段文字的摘要是什么;比如情感分析,输入一段句子,那么问题就是这个句子的情感是正面的还是负面的。
NLP的问题可以看作是QA的问题,而QA的问题可以用Seq2Seq来解决。硬train一发!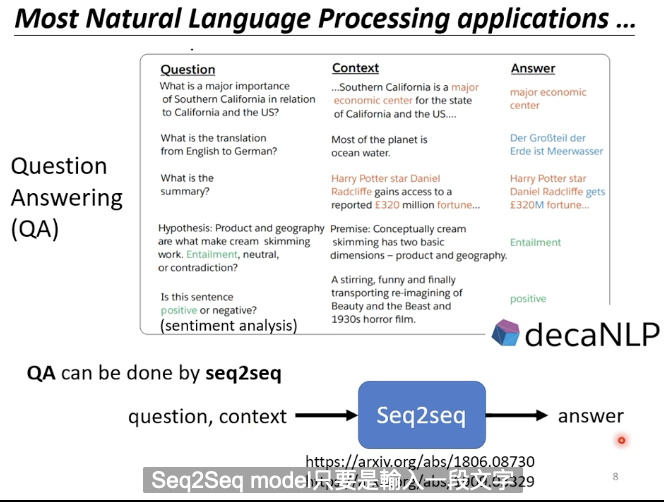
Seq2Seq还能用来处理多标签分类问题。多标签分类问题和多分类不一样。多分类是,输出的结果只属于一个class,多标签分类问题是输出的结果可以有多个标签。
现在我们提到Seq2Seq,首先想到的都是Transformer。它由两个部分构成,一个encoder,一个decoder。
2.Encoder
Encoder做的事情是input一排向量,输出等长的一排向量。这件事可以用Self-Attention、RNN、CNN,都可以。
Transformer的设计中到处都是ResNet的痕迹。Bert其实就是Transformer的Encoder。
像论文中介绍的,由于Transformer中没有循环以及卷积结构,为了使模型能够利用序列的顺序,作者们需要插入一些关于tokens在序列中相对或绝对位置的信息。因此,作者们提出了“Positional Encoding”(位置编码)的概念。



3.Decoder
1.Autoregressive Decoder—-自回归的Decoder
Decoder的输入有Encoder的输出和BEGIN这个特殊符号,表示句子的开头。
后面Decoder的输入是前一个时间点自己的输出。

Masked Self-attention与Self-attention的区别是,只看前面的序列。比如,在计算b2时,我们只知道a1和a2的key和a2的query,然后用它来计算attention。也就是说,后续序列不可见。
因为Decoder输入是一个一个的,输出的东西也是一个一个产生的,所以,它没有办法考虑右边的东西, 要用masked Self-attention。而Self-Attention的输入是一整个序列。

因为Seq2Seq模型的输出长度是由模型自己决定的,所以,我们希望机器能够习得什么时候应该结束。那,我们把END符号也加入到词汇表中,当然,我们可以把END和BEGIN用同一个符号表示。我们希望当输出END的时候,结束序列输出。
2.Non-Autoregressive Decoder NAT
AT和NAT的比较:
- NAT是输入一排的BEGIN,然后产生一排的输出,使用的是Self-Attention。
- 那么如何决定输出的长度呢?
- 可以将Encoder的输出输入一个Classifier,用来预测句子的长度。
- 可以设置一个句子长度的最大值,如300,然后,对于输出句子截取到END符号出现。
- 那么如何决定输出的长度呢?
- NAT的优点是:可以并行处理,且能够控制输出的长度(BEGIN个数)
- NAT的表现一般没有AT的好。

4.Encoder和Decoder之间的信息传递
Encoder先用Self-Attention处理输入,产生一排等长输出;同时Decoder用Masked Self-Attention处理BEGIN这个特殊的符号,产生一个输出。Decoder产生的输出经过一个transform得到q,q与Encoder的输出做Self-Attention,得到v。(案例上没有让q与自己的key进行结合),然后交给一个FC处理。这个步骤叫做Cross Attention。
当然,Encoder和Decoder之间的信息传递的方式还有很多。
5.训练
当我们输入一段“机器学习”的语音,我们希望经过模型处理后能够得到“机器学习END”五个字,也就是说,END也是要学习的。其中,每一个字的学习都可以当作是一个多分类的问题,然后我们要求所有字加起来的交叉熵损失最小。
注意,我们看到decoder的输入是什么?是正确答案。 在训练的时候,我们会给decoder看正确的答案。这个训练方式叫做Teacher Forcing,使用真实值作为输入。
(也不能都用正确答案,要人为地添加一些错误的东西,要不然的话,一旦有一个字错了,就会步步错。要让decoder看一些错误的东西,可能表现效果更好。)
而在测试的时候,显然没有正确答案给Decoder看,所以存在数据的不匹配问题。
训练时的Tips:
1.Copy Mechanism 复制机制
之前我们都是要求Decoder自己产生输出,也许Decoder没必要自己创造输出,它需要做的事情也许是从输入中复制一些东西出来。
这种机制可能在聊天机器人任务中使用。
也可能在文本摘要中使用。
6.Non-Autoregressive Sequence Generation 非自回归句子生成
像条件语句生成任务,如语音辨识、看图说话、机器翻译等等。
自回归模型(Decoder用的masked Self-Attention)。像机器翻译使用RNN,先把输入的句子Encode成一排vector,然后在解码时,后一个字依赖于前一个字,属于自回归模型。这种自回归模型的缺点是,如果我们要解码的句子很长,解码的时间就和句子的长度成正比。

引入Transformer之后,如果用自回归模型,相比于RNN来说,只是Encode操作变成了parallel的,但是Decode过程和RNN一样,一个接一个。

多模态问题(multi modality problem):同一个输入,可能对应很多不同模式的output。
这就是Non-Autoregressive可能遇到的问题,因为它的输出是并行产生的,所以,就会出现每个位置输出的随机组合问题。这个问题在Autoregressive中不存在。
一种解决这种问题的方法是,预测输入的每个字对应输出的字的个数,提前规划好输出的结构。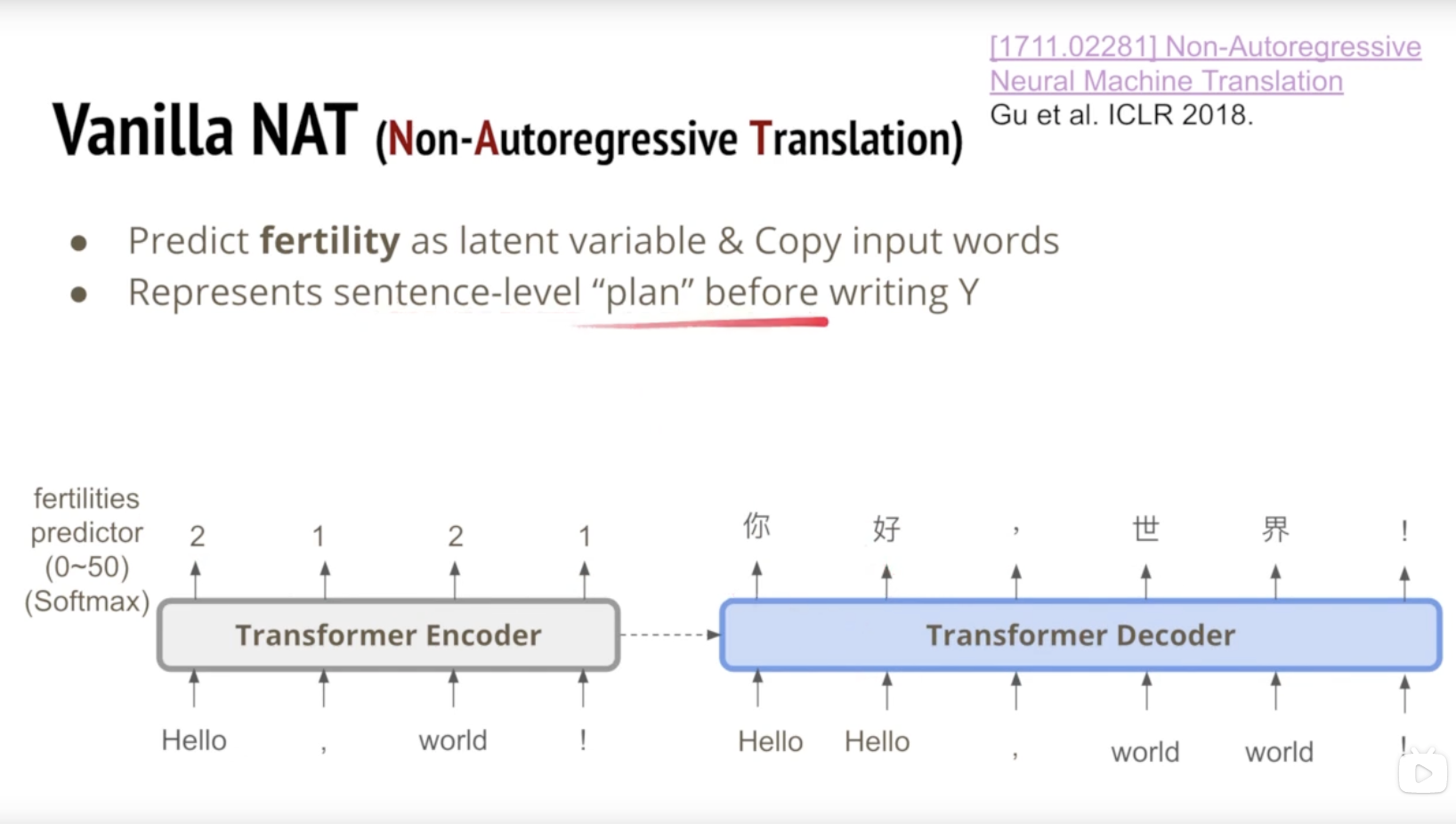
1.Mask-predict
- 首先用一个Encoder来预测句子翻译后的长度,然后得到一版比较烂的翻译。
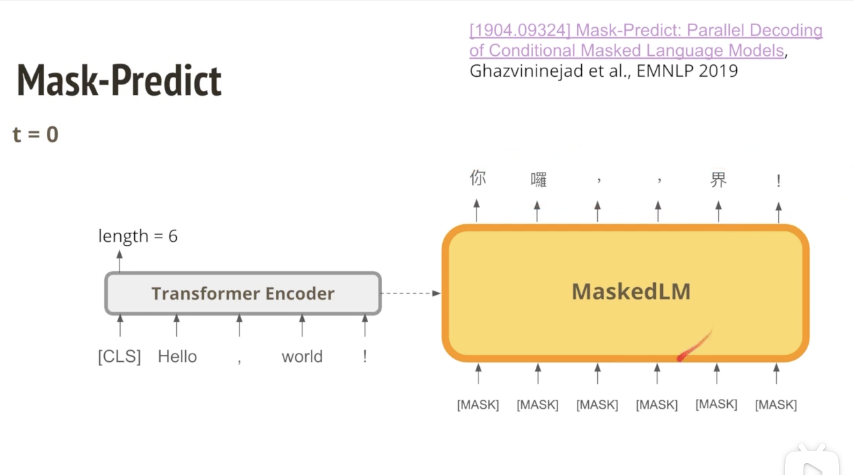
- 然后把这一版烂的翻译作为decoder下一轮的输入,同时,要先把概率比较低的n个词用mask替换,然后解码之后的结果就比较好,因为它可以看到旁边已经生成的字长什么样子。

问:n怎么取?
decoder次数越多,n越小。也就是说,刚开始mask的单词数多点,后面少点。


若有收获,就点个赞吧
0 人点赞
