Adversarial Attack
我们希望我们的类神经网络不仅要正确率高,还希望能有应付来自人类的恶意攻击。
eg:垃圾邮件过滤。人类会想方设法骗过Network。
1.Targeted and Non-targeted Attack
为什么加入非常小的杂讯,可以让Network产生错误这么离谱的结果呢?
我们在原来的图片上的每个维度加上小小的资讯,希望network把它识别成其他东西。
这种攻击任务分为无目标的和有目标的。
Non-targeted:只要Network判断的结果和原来不一样就行。
Targeted:让Network判断结果就是某一个确定的值。
Benign Image是原始图片,Attacked Image是加过人肉眼看不到的杂讯的图片。
我们的网络并不差,用的是ResNet-50,但是为什么会出现这种情况?这是人类通过某种手段故意让网络识别不出来的。

有的时候,我们加入一些人眼可见的杂讯,Network仍能识别出这是猫。
假设我们的网络输入是x0,及🐱图片,输出是各种动物类别的概率。假设Network的参数是固定的。(因为Network是服务端的,其他人是不可能去改这个东西的)
因为是攻击,加入杂讯后的图片和原图差距越小越好d(x0, x)
Targeted:y_hat和y0的距离越大越好,y_hat与y_target距离越小越好。 
怎么计算d(x0, x)?
在图片任务上,这里给出了两种计算距离的方式,一种是计算L2范式,一种是计算最大差距。
假设差距为delta。
L2范式:如果每个维度都分配相同的差距,那可能就很小,人眼很难看出来。
L-infinity:可能某些维度差距很大,而其他很小,人眼能看出与原图的差别。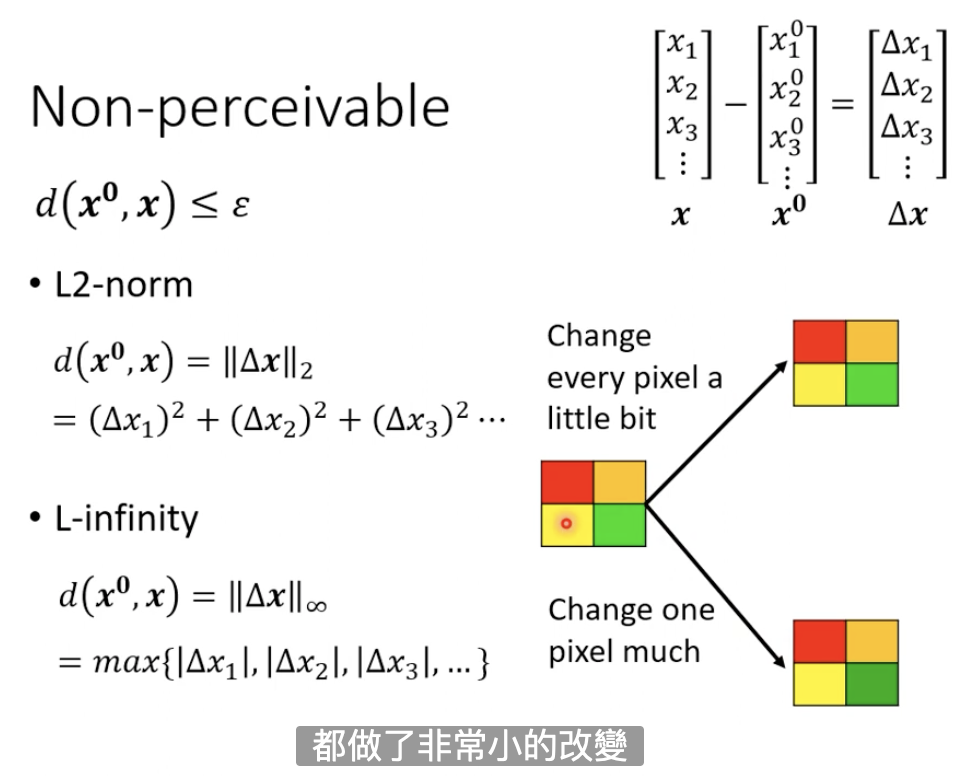
训练这个系统的过程:
如果不考虑加入杂讯的图x和原图x0之间的差距,那么这个问题就是通过更新x来实现最小化L(x),及尽可能地增大y和y_hat之间的差距。
当考虑x和x0之间的距离,且用L-infinity方式计算距离时(每个维度做比较,输出最大值),让L-infinity的结果小于delta。在实做中其实就是当x的范围超出方块内时,就修正到边框上。 
有个人发了一篇论文,FGSM。希望只进行一次gradient descent。做法就是当gradient<0时,输出-1,gradient>0时输出1,learning_rate为delta。这样的话,每个维度处理完后就跑到了拐角上。
2.类神经网络能否躲过人类的恶意?
白盒攻击:知道模型的参数。
黑盒攻击:不知道模型的餐食,只能通过接口访问服务。

若有收获,就点个赞吧
0 人点赞
