一.Convolutional Neural Network
1.举例子理解CNN,使用Receptive field
假设我们现在有一张100100的猫的彩色图片,则它应该有三个channel,如果将其用一个一维向量表示,应该具有3100100=30000个特征。
如果我们采用fully-connection NN,第一个隐藏层有1000个隐藏单元,则,第一层的W参数有31e7个,数据量太大。采用全连接的方式的话,弹性比较大,越容易overfitting。
对于图像识别来说,我们需要做的是找出图片中的一些Pattern,通过这些Pattern组合起来,判断究竟是什么动物。比如,对于一只鸟来说,可能我们通过鸟嘴、鸟爪、眼睛就可以辨识出这是一只鸟,而这些Pattern的提取并不需要整张图片作为输出,所以,我们可以不采用全连接神经网络。

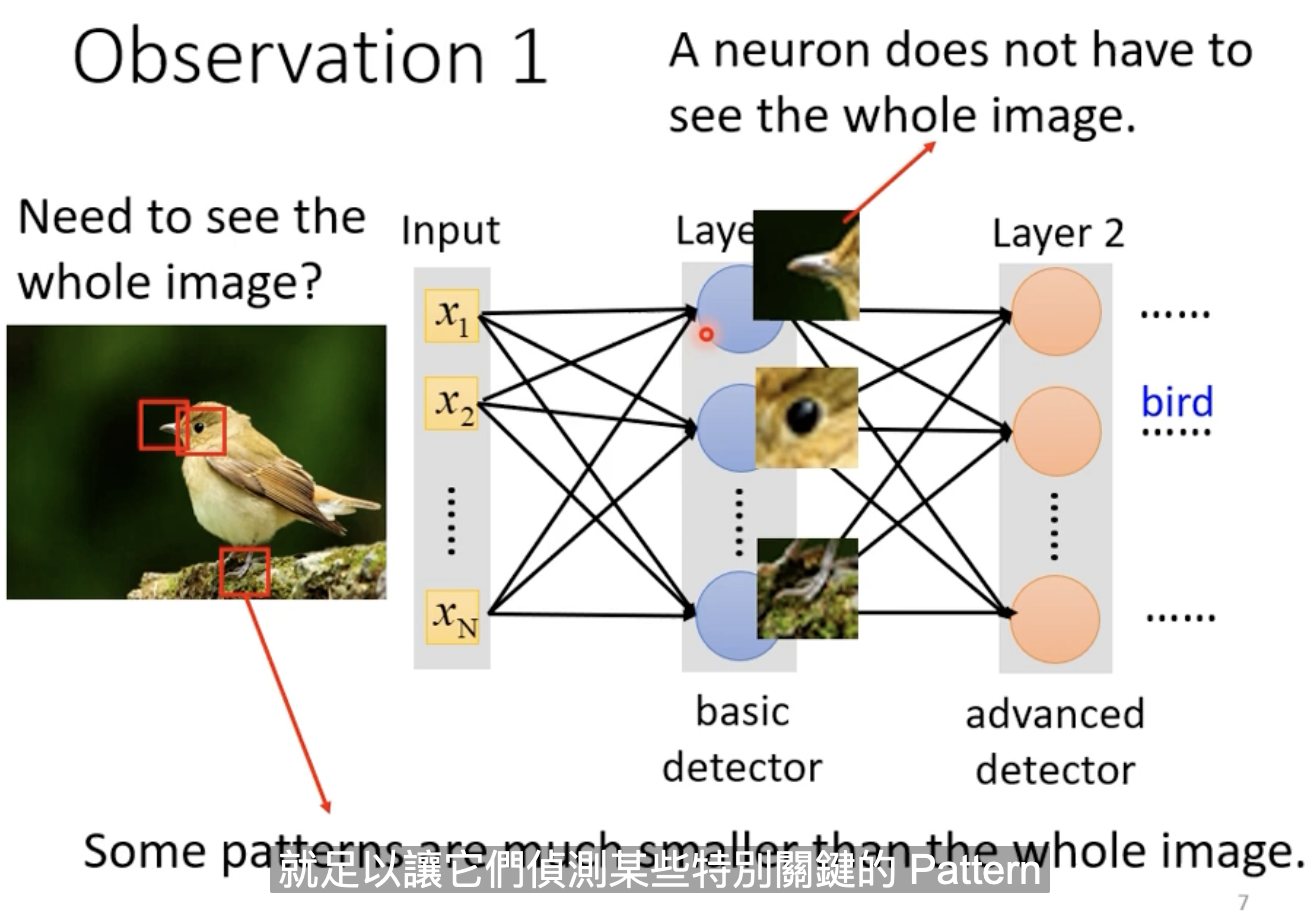
2.Receptive field-感受野
每个Neuron只关注自己的Receptive field。Neuron之间的Receptive field是可以重叠的。(甚至两个不同的Neuron,观测同一个Receptive field)
问:1.不同的Neuron的Receptive field的大小可不可以不一样?
可以
2.Receptive field可不可以只覆盖1个channel?
可以
3.Receptive field的形状可不可以不是正方形的呢?
可以
最经典的方式:
- 会看所有的channel。所以,一般就考虑W和H,因为C都是要放在Receptive filed里的。高跟宽合起来叫kernel size(卷积核大小),eg:(3*3)
- 同一个Receptive filed会有多个Neuron去守备它。
- 一般Receptive filed之间的步长是1或2。(所以,Receptive field之间是有高度重叠的,这也是我们希望的。因为如果没有重叠,Pattern出现在交界处怎么办?)
如果最右边/最下面的Receptive filed超出范围了怎么办?
使用padding,可以补0或采取其他填充的方式。

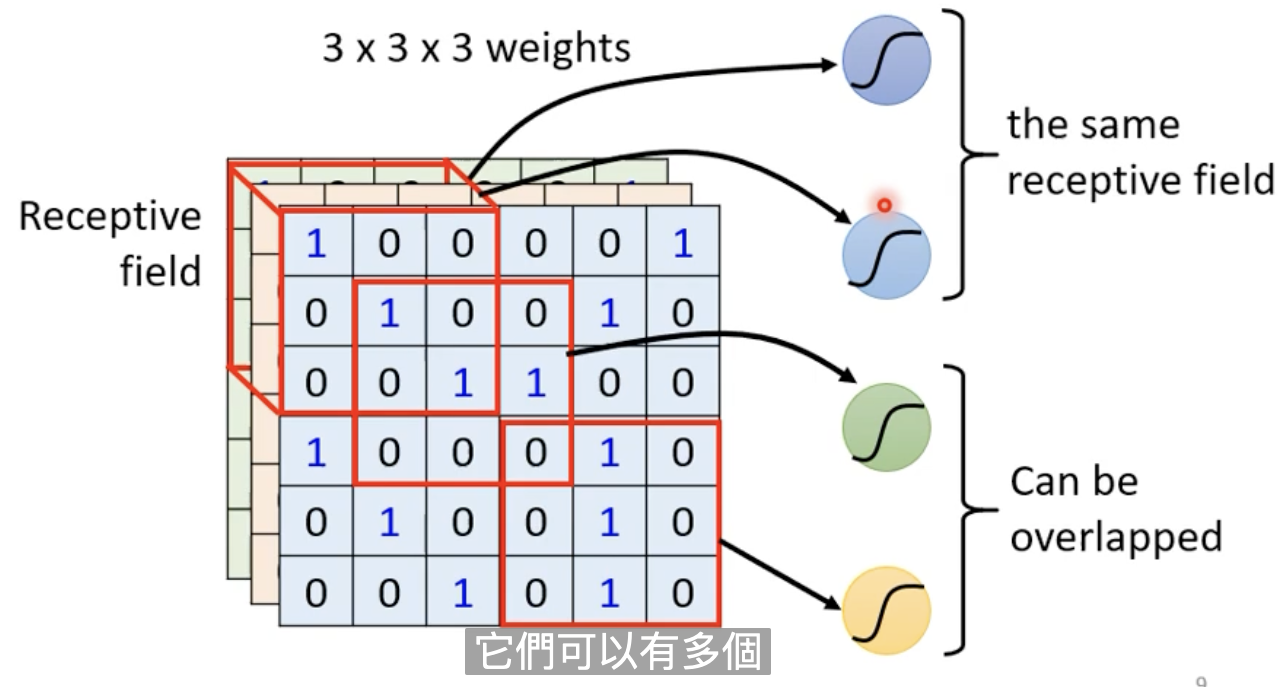

3.相同的Pattern出现在不同的区域
对于左上角的这个鸟嘴对应的Receptive field来说,会有一组Neuron来监测它,假设有个Neuron的工作是侦测鸟嘴的话,鸟嘴就会被检测出来。
同样的,对于鸟嘴出现在中间的图片,一样有一个Neuron来监测出鸟嘴。
这两个Neuron的工作是一样的,只是守备的范围是不一样的。那,我们有必要在每一个Receptive field都放一个监测鸟嘴的Neuron吗?
我们采用共享参数的方式。即两个工作内容一样的Neuron使用相同的weight。
CNN的Model Bias会比较大。但是,CNN是专门为图像识别设计的,能够很好地cover图像识别的任务,所以,它的表现能力仍然很好。


2.举例子理解CNN,使用Filter
图1
我们假设图片是66的黑白图片。我们的Filter的大小是33。我们在图片上不断地移动Filter,并做内积。
图2
每一个filter都会给我们一组数字。这一组数字又有一个名字,叫做feature map。
如果我们有64个filter,那么就会产生64个44的数字。
这个feature map可以看作另外一张新的图片,只不过这张图片的channel数量是64(Filter的数量)。
图3
我们对于这张新产生的图片继续用刚才的方式不断地移动filter,产生新的“图片”。不过,此时的filter的大小为33*64。因为我们要覆盖所有的channel。
图4
问题:我们使用33的filter,会不会看到的范围太小了?
不会。对于第一层卷积来说,我们使用33的filter,每次移动filter,都会让覆盖的区域与filter做内积,然后求和,作为新图片的一个位置,那么新图片33的范围,相当于原图片的范围是55那么大的。即是25/9个filter的大小。卷积层越深,看到的范围就越大。
结合例子1和例子2,例子2中的Filter扫过整张图片,实际上就是例子1中所讲的共享参数的实现机制。
图1
图2
图3
图4
3.Pooling-池化(主要作用是减少运算量)
我们先对一张图片进行下采样,比如把偶数的column和奇数的row都拿掉,图片变为原来的1/4,仍然能够看出这是一只鸟。
Pooling本身没有参数,所以,不是一个Layer,没有weight,没有要学习的东西,就是一个operator。
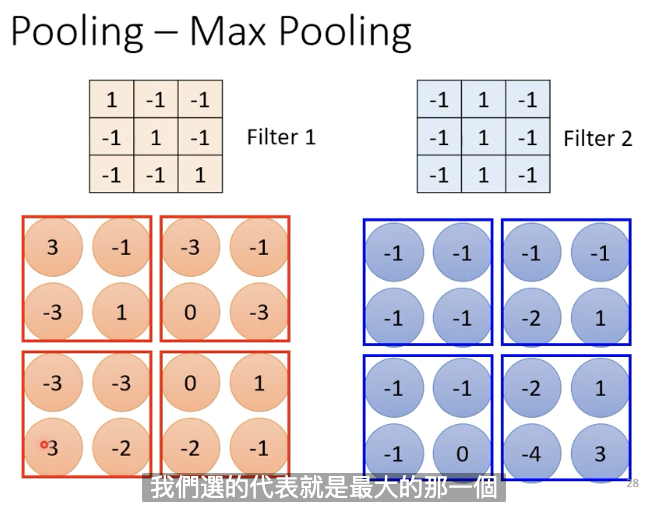
Pooling有很多的版本。这里讲解Max Pooling。
在例子2中我们讲过,每一个Filter都会产生很多数字,我们把这些数字分成几个几个一组,如2*2一组。每一组里选一个代表。在Max Pooling里面,我们选择的就是最大的那一个。
当然了,我们也可以有不同的选择方式。如Mean Pooling,选择一组中的平均值,等等。我们也可以让23一组,33一组。这个完全没有限制,由我们自己来决定。
所以,我们做完卷积之后,还会做Pooling,Pooling的作用就是把图片变小。做完卷积之后,会有很多channel,做Pooling不会改变channel的数量,但是会让图片W和H变小。
比如下图中的44的图片,分成22一组,做池化,就可以变成2*2的图片。
一般实践中,convolution和Pooling是穿插着做的。一般是先做几次convolution,然后做一次Pooling。当然,当我们做非常细微的监测的话,Pooling是会对最终的结果有伤害的。对于影像电视的NetWork的话,现在一般都不用Pooling,用的是full convolution,即只使用卷积操作。

4.经典的图像识别的网络架构
先对图片进行多次Convolution和Pooling操作,最后对产生的结果进行Flatten,展开成一个一维向量,然后将这个一维向量传入一个全连接的神经网络进行处理,最后经过一个softmax层进行预测。
5.CNN除了可以用于图像识别,还可以下围棋
CNN是为图像处理设计的。只有和图像处理具有共性的任务,才能用CNN。
对于围棋来说,有一个1919的棋盘。下一步可能走的位置也有1919个。所以,我们完全可以用一个全连接的神经网络,处理一个分类数为19*19的分类问题。
当然,我们还可以使用CNN的方式,因为,我们可以把整个棋盘看作是一个19*19的图片。关于Alpha go的论文里,有48个channel,即用48个数字来描述这个位置发生了什么。

6.CNN还可以用在语音识别和文本处理上

7.CNN不能处理图像放大、旋转的问题
如果我们把图片放大、或者旋转后,CNN可能就无法正确识别这个图片究竟是什么动物了,所以我们需要把图片放大、缩小、旋转后,也作为训练集扔给CNN进行训练。
这个问题可以通过Spatial Transformer Layer解决。
二.Self-Attention 自注意力机制
最大的问题是运算量大
Bert里面有用到Self-Attention
之前我们说的图像识别、分类、回归等任务,都是说输入的是一个向量。那有没有可能输入的是一个sequence,且长度是不定的呢?
有。像文本处理。
如果我们把一个句子的每个单词用One-hot独热编码的形式表示,没有办法表示出单词和单词之间的相关性,单词之间彼此独立、正交;
还可以用Word embedding(词嵌入)的方式来表示单词,能够反映出单词的特征。


1.输入和输出的对应
- 输入Tx = 输出Ty,eg:词性标注任务
- 输入Tx,输出Ty=1,eg:情感分析任务
- 输入Tx,输出Ty,Tx不等于Ty,eg:机器翻译 —- sqe2seq任务

2.Self-Attention的使用
对于词性标注任务来说,比如I saw a saw(我看见一把锯子)。我们希望标注的是“名词 动词 量词 名词” ,这就需要考虑上下文之间的关系。
我们也可以让self-attention和fully connected交替使用。self-attention负责处理整个sequence的资讯,fully connected用来处理某一个位置的资讯。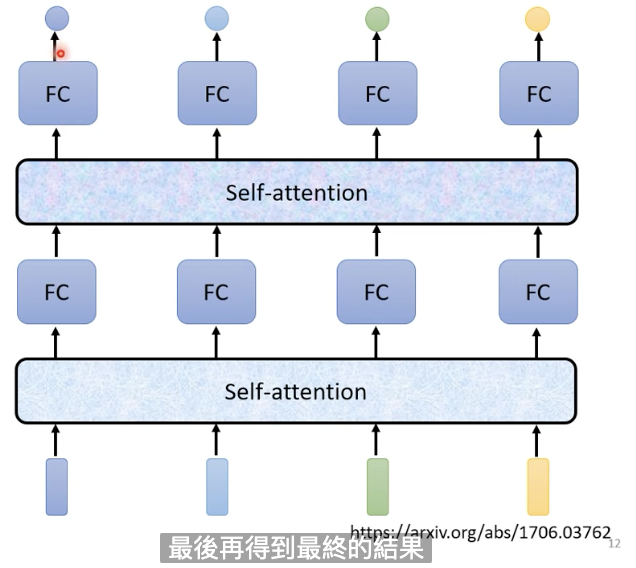
3.详解self-attention
self-attention的输入是一串vector。这些vector可能是整个network的input,也可能是hidden layer的output。
eg:
这里的b1,b2,b3,b4都是综合考虑了a1~a4产生的。
问:那么b1,b2,b3,b4是怎么产生的呢?
- 根据a1找出sequence中所有和a1相关的向量。(最终得到的是αij’,其是经过softmax方法处理过的,每列求和为1,如图3—-当然也不一定非要用softmax,也可以用其他激活函数—玄学)
每一个向量跟a1关联的程度用α来表示。那么,怎么计算α呢?见图2
1. **Dot-product方法**:把输入的两个vector分别乘上两个不同的矩阵Wq跟Wk,得到q跟k这两个向量,然后对q跟k做内积,然后sum求和,得到一个标量α。(也是如今用在transformer中的方法)1. Additive方法:把输入的两个vector分别乘上两个不同的矩阵,得到q跟k这两个向量,然后将q跟k串起来,然后经过激活函数处理,然后再过一个transform,然后得到α。
- 我们已经计算出了α,然后根据关联性抽取重要资讯。
把a1~a4乘上Wv,得到新的向量V1~V4,然后让V1~V4去乘上对应的α’,并求和,得到b1。哪个输入向量和a1关联性越大,越能主导b1的值。
图1
图2
图3
图4
由a得到q、k、v。
图5
由q、k得到α。
图6
由α’和v得到b
图7
总:self-attention输入是I,输出是O。需要学习的参数就是Wq、Wk、Wv。
4.Multi-head Self-attention 多头自注意力机制
如2-head Self-attention,用来找输入sequence之间的两种不同的相关性。
这样我们就会有双倍的q、k、v。q到两个q要乘上一个矩阵,同样的对于k、v。
在计算α和b的时候,两组q、k、v单独计算。(因为这是两个不同的相关性) 
对于得到的两个b向量,通过一个矩阵进行transform,得到b,用来传给下一层处理。
5.缺点:忽略了位置的信息=》Positional Encoding
对于self-attention来说,我们在求相关性的时候,对每个输入做的都是同样的操作,1和4的距离与1和2之间的距离对于它来说,没什么区别,“天涯若比邻”。
Positional Encoding:每一个位置都有一个专属的向量ei,这个是由人来设定的。目前仍是一个尚待研究的问题。
6.Self-Attention应用于语音
语音一般来说向量都比较大,而Attention-Matrix(就是α)的大小是向量的平方大小,很消耗内存。
在做语音的时候,会用Truncated Self-attention(截断的自注意力机制)。
这个方法就是,不需要看整个输入的句子,而只需要考虑一个小范围就好,这样就可以加快运行的速度。
7.Self-Attention应用于图像
我们可以把图像当作是一个Vector set,下图可以看作每个位置是3维向量,然后Vector set大小是5*10。
8.CNN和Self-Attention的对比
CNN相当于是简化版的Self-Attention,因为CNN只考虑Receptive field的资讯,而Self-Attention考虑整张图片的资讯。
Self-Attention只要设定合适的参数,就能够做到跟CNN一模一样的事情。

CNN就是一种受限制的Self-Attention。Self-Attention弹性比较大,当数据量比较小的时候,就会overfitting(其实就是参数多,数据量小,而我们的模型训练过程中会不断地减小损失函数,去拟合训练数据,最后的结果就是过拟合); 而CNN在数据量小的时候表现比较好。当数据量比较多的时候,CNN无法从数据中获取足够多的资讯,表现能力就比Self-Attention弱。
9.RNN和Self-Attention的对比
- RNN相比于Self-Attention的话,记忆时间受限;而Self-Attention具有“天涯若比邻”的特点。
- Self-Attention还有另外一个特点就是可以平行处理所有的输出,而RNN只能按顺序处理一个个的Vector。


10.Self-Attention应用于Graph

三.无监督学习之Word Embedding
word embedding是降维的一个广为认知的应用。
图1
如果我们用one-hot的方式来表示单词的话,那就没办法知道单词和单词之间的相关性了。
我们可以建一些word class,把具有同样性质的word,cluster成一群一群的,然后就用那一个word所属的class来表示这个word。
从one-hot encoding到word embedding,是一个降维的过程,可能是从10w dimensions到100或200dimensions。我们希望具有类似语义的单词在这个图上是比较接近的。
图1
1.如何实现词嵌入
我们只需要给machine阅读大量的文章,它就可以自动学习每一个单词的feature vector应该是什么样子的。(比如训练Bert的过程中,会训练出一个Word Embedding)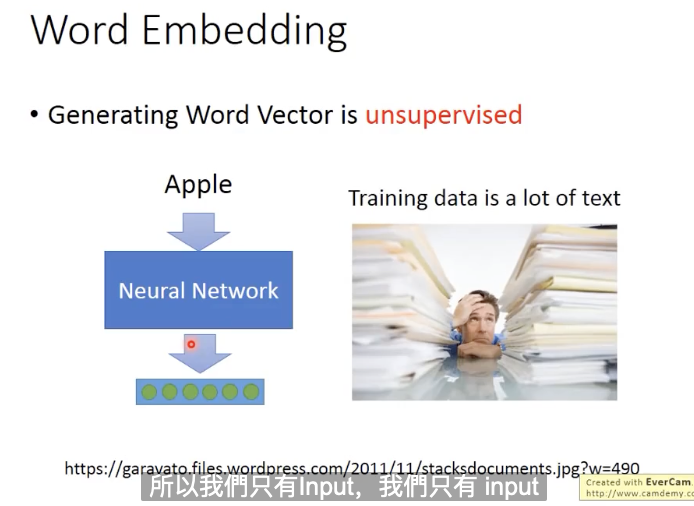
我们可以通过上下文来了解单词。比如,“马英九520宣誓就职”“蔡英文520宣誓就职”,机器就能知道“蔡英文”“马英九”代表了某种有关系的object。
1.实现方式之一:count based
- 如果两个单词Wi跟Wj常常在同一篇文章中出现,那么V(Wi)跟V(Wj)就会比较接近。
2.实现方式之二:prediction based
基本思想是实现一个Neural Network,输入是单词Wi-1的one hot向量,输出是每一个单词可能是Wi的概率。
我们把第一个隐藏层的输入z1,z2用来表示单词。不同的单词对应的z1、z2是不同的,我们将其用二维图像展示出来,大致如右下角所示。
对于“马英九520宣誓就职”“蔡英文520宣誓就职”这两个句子来说,wi-1是名字,wi是“宣誓就职”。蔡英文和马英九虽然是不同的input,但是为了要让最后output的地方,“宣誓就职”对应的dimension对应的概率最高。就必须让中间的hidden layer 做一些事情,中间的hidden layer必须要学到这两个不同的词汇:“蔡英文”、“马英九”必须要通过参数的转换后,把它们对应到同样的空间。在input进入hidden layer之前,必须把它们对应到接近的空间。这样在output的时候,它们才能够有同样的概率。
当然,我们可能需要考虑之前更多的单词,来预测下一个单词。
基于预测的方式还有一些变体:
- CBOW:根据上下文预测中间的单词—如Bert训练过程中的Mask单词任务
- Skip-gram:根据中间的词来预测周围的词。

2.词向量可以用来发现单词的特性

3.多领域嵌入

四.Spatial Transformer—空间Transformer
CNN没办法适应图片缩放和旋转。
在CNN之前加上一层,专门用来处理图片的缩放和旋转。
向下平移一个单位:
图片缩放:
图片旋转:
现在我们如果要对图片进行旋转、缩放、平移的话,只需要6个参数:
所以,Spatial Transformer Layer的功能就是学习到这6个参数

ST-CNN:
五.RNN - Recurrent Neural Network 循环神经网络
1.槽填充-Slot filling

如果我们考虑说用一个前馈神经网络来实现槽填充的话。
这个神经网络的输入是一个词对应的向量,输出是这个词属于这些slots的概率。
上图的例子里有两个slots,一个是终点,一个是到达时间。那我们输入台北时,输出的就是台北属于终点和到达时间的概率。
如果我们要表达的是 “离开台北”,那就不行了。对NN来说,输入一样的input,就会输出相同的output。所以,我们需要网络具有记忆,能够考虑上下文。在看到“taipei”之前,看到“arrive”或“leave”,这样当输入“taipei”时,就会根据记忆输出不同的output。

2.RNN的变体
Elman Network:把隐藏层上一个时间点的值存起来,输入给下一个时间点。
Jordan Network:把上一个时间点最终的输出,输入给下一个时间点。
Bidirectional RNN:双向RNN。
LSTM:长短时记忆网络


3.LSTM
本文引自:理解LSTM。
理解GRU。
这里主要讲了LSTM的处理过程。
每个time step的输入:C
处理:三个门—输入门(对标AndrewWu讲的更新门)、遗忘门和输出门、候选C
输出:更新后的记忆单元C
三个门决定:添加什么、忘记什么、输出什么
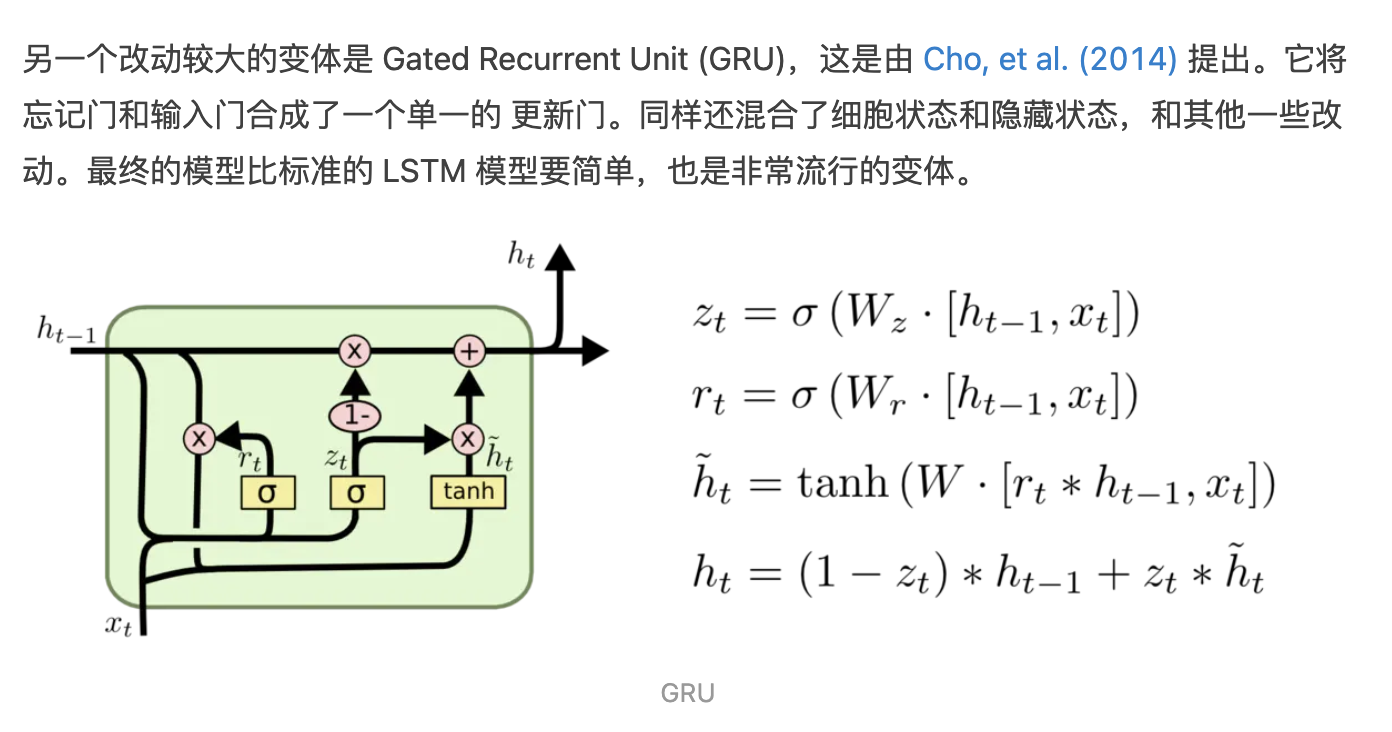
还延续到了LSTM的变体,如带peephole(窥视孔)的LSTM,即每一个门不仅考虑当前的输入和上一个隐藏状态,还考虑上一个记忆单元状态;还有简化版的GRU,其把输入门和遗忘门合并为更新门,同时让隐藏状态和记忆单元同值,大大地简化了网络的结构,提高了网络的运行速度,但是,效果上来说,会比LSTM稍微差点。









4.LSTM举例
举例1
假设:
- 我们的输入是三维的,输出是一维的。
- 假设X2为1时,会把X1的值放到记忆单元里。
- 假设当X2为-1时,会重置记忆单元。
- 假设当X3等于1的时候,输出门才打开。(要学习的东西)


举例2
假设权重已知,假设计算c
- 当输入(3,1,0),且C初始化位0时。
- 输入门值为1,候选c
为3,遗忘门为1,c 为0,则可得c 为3。(13+10) - 然后,输出门值为0,则无需计算tanh(c
),y值为0。
- 输入门值为1,候选c
- 接着输入(4,1,0)
- 输入门值为1,候选c
为4,遗忘门为1,c 为3,则可得c 为7。 - 然后,输出门值为0,则无需计算tanh(c
),y值为0。
- 输入门值为1,候选c
。。。。。。

5.LSTM与传统神经网络
LSTM的一个单元就相当于标准NN的一个Neuron,只不过,这里的每一个Neuron的参数是标准NN里的4倍(不止。如果只考虑Xt+1的话是4倍,如果再加上Ct和Ht的话,就会更多)
4倍的来由:输入门、忘记门、输出门、以及新的候选记忆细胞向量,都需要用到一个权重矩阵。
LSTM的每一个Neuron有一个MemoryCell,每一层Hidden Layer的MemoryCell和在一起是向量Ct。
与传统神经网络相比呢,我们可以把LSTM处理的这个过程看作是标准神经网络中的一个Neuron。
下图是假设输入一个二维向量,隐藏层有两个LSTM单元。
我们知道,LSTM有四个输入,分别为输入门、遗忘门、输出门、候选Ct;有一个输出,为a值。
所以,LSTM所需要的参数量是原来的一般的神经网络的四倍。
Peelhole:带窥视孔的LSTM。
在时间步t,对于输入Xt+1(当然,正常情况下,会把这个Neuron前一个时间点的输出和Xt拼接起来作为输入;当然,正常情况下还会把该Neuron上一个时间点的C



一般情况下,我们会把LSTM叠上好几层,然后再用一个全连接神经网络处理输出。
六.Graph Neural Network - 图神经网络(没听懂,跳过)


1.如何利用图的结构和节点之间的关系
1.将卷积的概念推广到图上。Spatial-based Convolution 基于空间的卷积
- Aggregate(聚集):用邻居的特征来更新下一层的hidden state。
- Readout(读出):把所有节点的feature集合起来代表整个graph。

假设我们输入的是x0到x4,首先我们对输入进行embedding,得到第0层的hidden layer(其实就是输入)。然后对邻居进行处理,0,2,4是3的邻居,得到h13。


2.回到信号处理中卷积的定义。

七.作业:半监督学习
有时候会有很多未标记的数据,怎么利用呢?
- 先用带标记的数据训练一个模型
- 用模型给未标记的数据加标签
- 从加标签的数据中筛选出可用的数据,加入到我们的训练集中,循环重复1~3的步骤。
怎么筛选?
比如,在经过softmax层处理后,一张图片有80%的几率是🐶,我们就认为这个标记是可靠的


若有收获,就点个赞吧
0 人点赞
