1.芝麻街与进击的巨人
大致意思是,虽然bert有340M的参数,但是相比更大的模型来说,微不足道。GTP3、Switch Transformer要大的多得多。




2.Bert简介
1.supervised model 与self-supervised model
supervised model:用带标签的数据训练的模型。
self-supervised model:自监督模型。自己在没有标签的情况下,想办法做supervised学习。它是属于无监督学习的。
把一堆资料分成两部分,一部分作为模型的输入,另一部分作为模型的标注。
2.MASK与Next Sentence Prediction
随机mask单词。
NSP:NSP任务被一些论文指出没有太大用处(eg:RoBERTa)。可能是因为这个任务太简单了。
怎么形容简单?就好像一个二分类问题,两个类(句子相邻的example、句子不相邻的example)之间的分界线很明显。很容易分辨出来。
SOP:原来的句子1和2,按照1、2和2、1的顺序作为输入句子A和B,判断哪一种情况是正确的顺序,这个问题就相对NSP要更难,目前SOP看起来是有用的,然后被用在ALBERT中。
因为句子1和2相邻,所以语义上相关,比较相似,所以,二分类为题要复杂些。
SOP和NSP的区别是,反例的选择。SOP是把1、2反过来变成2、1,希望预测结果是NO,而NSP是随机从语料库里抽出一个不同的句子,输出NO。
虽然Bert只是做了完形填空的工作,但是,却可以应用到很多下游任务中。只要给Bert一点有标注的数据,它就可以分化到各式各样的任务。Bert分化成各式各样任务这件事情,叫做fine-tune。而产生bert的过程就叫做Pre-train。
对Bert的评估是通过将Bert分化成各式各样的任务,在各个任务上进行微调,看在各个任务上的表现。

3.Bert的应用
1.情感分析——Ty=1
线性层的参数是随机初始化的,而bert的参数使用预训练的结果进行初始化,然后都通过gradient descent方式进行更新。
使用预训练的方式相比于随机初始化的方式,loss收敛更快,且多次迭代后,效果也更优。
2.词性标注——Ty=Tx

3.自然语言推理——Ty=1,sentence=2
sentence1:输入一个前提
sentence2:输入一个假设
应用:立场分析/检测。输入一篇文章,输入一个评论,看看这个人的评论是赞成还是反对还是中立。

4.阅读理解:基于信息抽取的问答
输入:
sentence1:问题
sentence2:文章
输出:
s和e
假设问题长度为12,文章长度为100.
那么,我们需要重头训练的参数是两个向量(一个用来找start,一个用来找end),记作start_vector和end_vector。
用start_vector与document输出的每一个embedding向量做内积,经过softmax处理,找到概率最大的位置s;同样的操作应用于end_vector,得到位置e;
如果s<=e,则答案就是s到e中间的内容;
如果s>e,则说明文章中没有答案。
5.FAQ
1.Bert的输入长度有限制吗?
理论上没有,实际上有。
2.为什么Bert就做了完形填空,却能应用于那么多的下游任务,且表现效果很好,怎么学会的?
https://arxiv.org/abs/2010.02480
来自李宏毅实验室的论文
Bert会考虑context,具有相似意义的单词的embedding也比较接近。
比如“果汁”的果和“苹果公司”的果,意义是不同的,我们可以通过计算两个词对应的向量的预先相似度看到。
下图是5个“水果”的果,和5个“苹果公司”的果计算cosine的结果。(越黄越相似)
说明bert在训练过程中学会了每个中文的意思。
一个语言大师说,我们可以通过一个词常常出现的上下文了解到这个词的真实含义。
bert做的事和用CBOW方法的word embedding很相似,不过,word embedding只是用了简单的线性层,而bert用到了深度学习,考虑了完整的上下文(同一个单词在不同上下文的意义不同),所以,bert也可以叫做Contextualized word embedding。
用到CBOW的词嵌入,每次用来预测单词的窗口大小是固定的,即如用左边3个,右边3个来预测中间的单词。
用到CBOW的词嵌入,只用了简单的线性层;
用到CBOW的词嵌入,没有考虑距离预测单词的距离(Bert考虑了,因为有Positional Embedding)
6.Bert的延伸
BART模型:是一个seq2seq模型。输入是打乱的句子,输出是还原的句子。
怎么打乱呢?
mask、删除单词、调整两个句子的顺序、把第二个句子的尾部头插、加一些空白位置等等。训练后的效果比只进行mask的效果要好。
3.GPT的野望
GPT很像是Transformer的decoder。用到的Attention也是masked Self-Attention。
训练过程是预测下一个单词的任务。
在预训练好GPT模型后,直接将其应用于翻译任务:
分为给几个例子、给1个例子、不给例子几种情况。当然,最终的正确率不太高。

4.Auto-encoder
关键词:压缩重建。
在bert和GPT之前,还有更古老的任务Auto-encoder,也是自监督式学习的一种pre-train的方法。
它做的事情很像是CycleGAN。把x-domain的东西映射到y-domain中,然后再映射回去。
我们希望呢,一张图片经过Encoder处理后,维度变得很低,也就是进行了压缩,然后进行重建,希望重建后的结果和输入越接近越好。
为什么图片压缩再重建能成功呢?
举个栗子,33的图片压缩成2维向量后重建。
因为图片的变化是有限的,可能只有两种,对应下图方块1和方块2,这样的话, 我们就可以用一个不同的二维向量来表示这两种变化。
所以,Encoder的作用呢,就是化繁为简,只要找到有限的变化,就可以把本来很复杂的东西,用比较简单的方法来表示。
De-noising Auto-encoder是加了杂讯的Auto-encoder,把加了杂讯的图片作为输入,试图输出加入杂讯之前的图片。
*这个加杂讯的操作很像是bert的mask过程,试图让模型能够根据上下文“纠错”。

1.Feature Disentangle——特征解耦
关键词:知道embedding的向量每个维度代表的内容。
当我们把输入特征经过Encoder处理变成一个向量后,我们有没有办法知道这个向量的每个维度表示什么内容呢?这样的技术就叫做Feature Disentangle。
Feature Disentangle能够实现什么下游任务?
变声器/语者转换。
经过Encoder处理后得到的向量中,能够知道哪些维度表示的是说话内容的信息,哪些维度表示的是说话人的特征。
2.Discrete Latent Repressentation——离散潜在表示
一张图片经过Encoder处理之后得到一个连续的vector,然后和codebook中的一排向量计算相似度;codebook中的向量也是学习得到的。
选出codebook中相似度最高的向量,然后丢到Decoder中。


3.异常检测
应用于不对称数据应用。即正面例子很多,几乎没有多少负面例子,没办法训练分类器。
eg:真人人脸检测系统。
训练时,使用真人人脸训练一个Auto-encoder
测试时,当用真人人脸时,经过压缩重建后,照片之间差异性较小;
当用动画人脸时,经过压缩重建后,照片之间差异性很大;因为Encoder出的向量和真人照片差异比较大,Decoder针对这样的输入进行还原处理后,效果不好,因为Decoder之前没有看过这样类型的照片,这样的话,输入和输入之间的差距就比较大,就能够找出非人脸。

5.Bert and its family与fine tune
1.Bert family
Elmo的实现用的是双向LSTM;
Bert的实现用的是Self-Attention Layer。
ALBERT:每个Block做同样的事情(即参数相同)。
Bert比较大, 那就有穷人用的比较小的bert。其中最有名的就是ALBERT。原来的Bert12层、24层是不同的参数,而ALBERT12层、24层参数竟然都相同,而且表现效果不仅没有变差,反而有提升。神奇~
下图中的论文记录了怎么去压缩bert的技术。
网络剪枝、知识提取、参数量化?、重新设计架构。
现在新的架构也趋向于去让我们可以有更长的输入,如一篇文章,甚至一本书。原来的bert一般可能输入长度512,Transformer-XL可以读跨segment的token(XLNET)。
还有Reformer、Longformer,试图减少self-Attention的计算量。因为如果输入是一本书,长度为n,进行一次self-Attention计算时,时间复杂度就是O(n2),难以接受。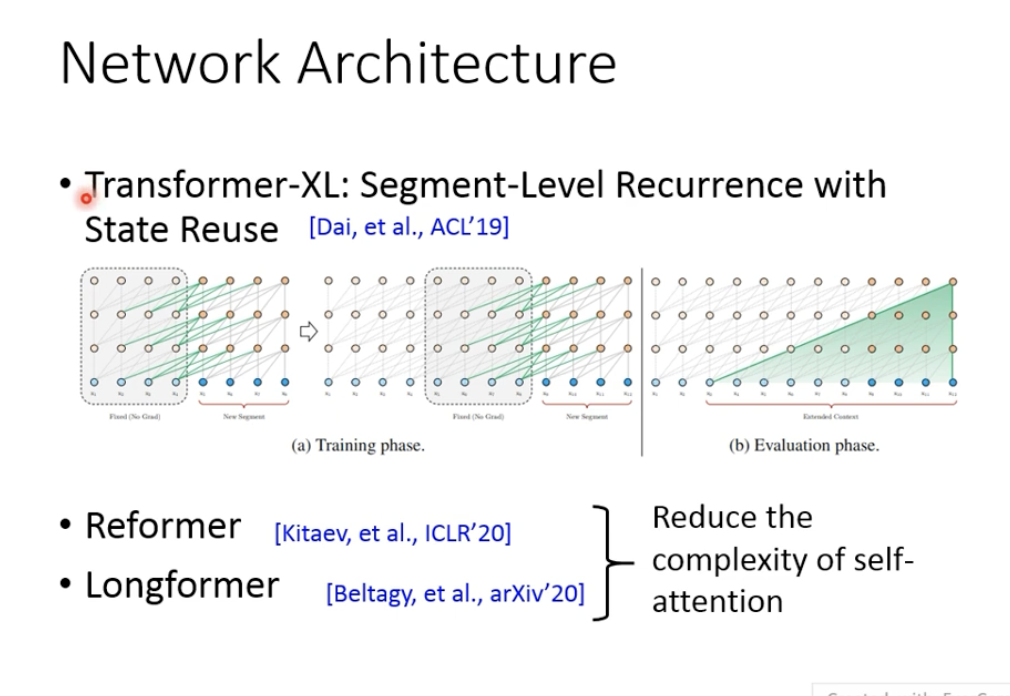
2.fine tune
我们希望在预训练好的bert模型上再加一些任务相关的层,然后直接将模型应用于特定NLP任务。
将Pre-trained的model应用于seq2seq的一个做法是,把bert当作encoder,然后和具体任务相关的层作为decoder;但是这样不太好,因为我们希望大多数参数都是预训练过的,因为我们使用预训练的模型时,一般资料比较少。所以,可能表现结果不尽人意。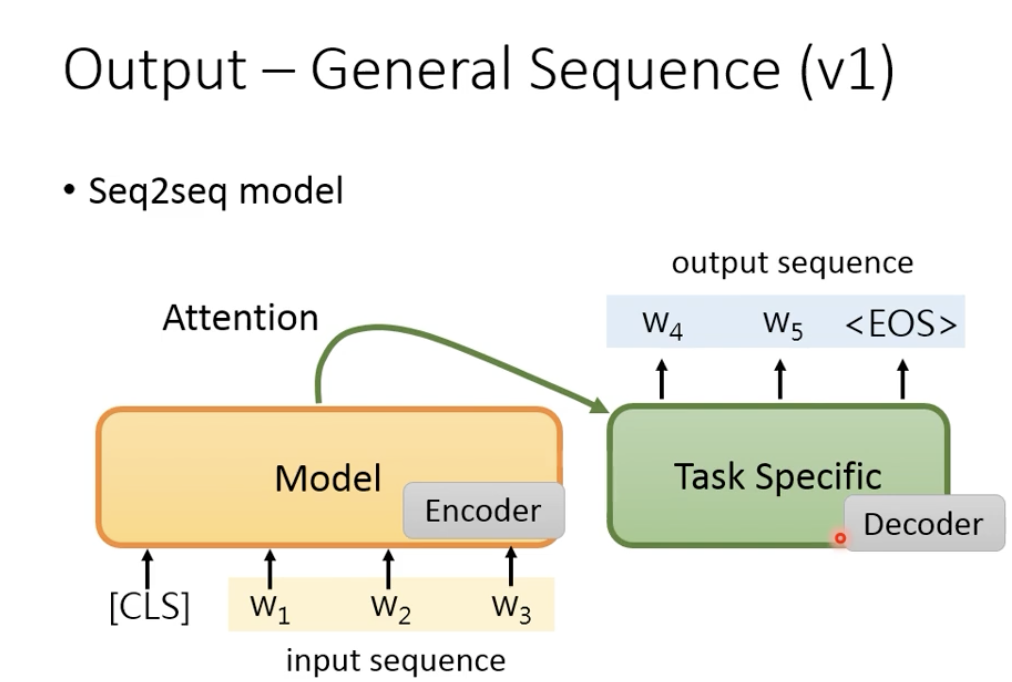
我们也可以把pre-trained model当作decoder来用。
模型先输入input sequence,然后输入特殊字符SEP,让SEP对应的embedding表示生成序列的第一个字符w1,然后把w1作为下一个输入,预测w2,….直到输出为EOS符号。
【待填坑:句子总长度是不是有限制啊,不然的话,自回归不知道究竟多长,而且原来的Query、Key、Value矩阵使用Self-Attention计算的,这里SEP之后的就是Masked Self Attention了。】
一个batch的输入总长度是固定的。
1.fine-tune的方式:fix pre-trained model和fine tune pre-trained model
一种方式是,我们Pre-trained model的参数固定住,在用labeled资料训练下游任务时,不更新;
一种方式是,Pre-trained model的参数也参与更新,起到初始化的作用,实做中的效果更好。
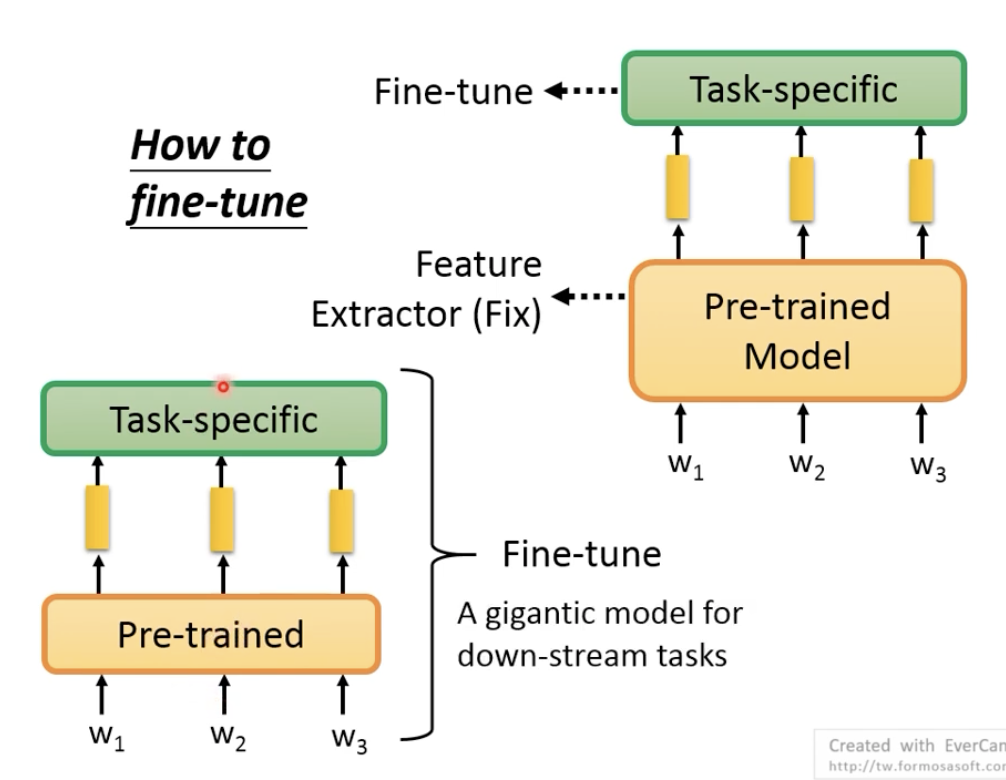
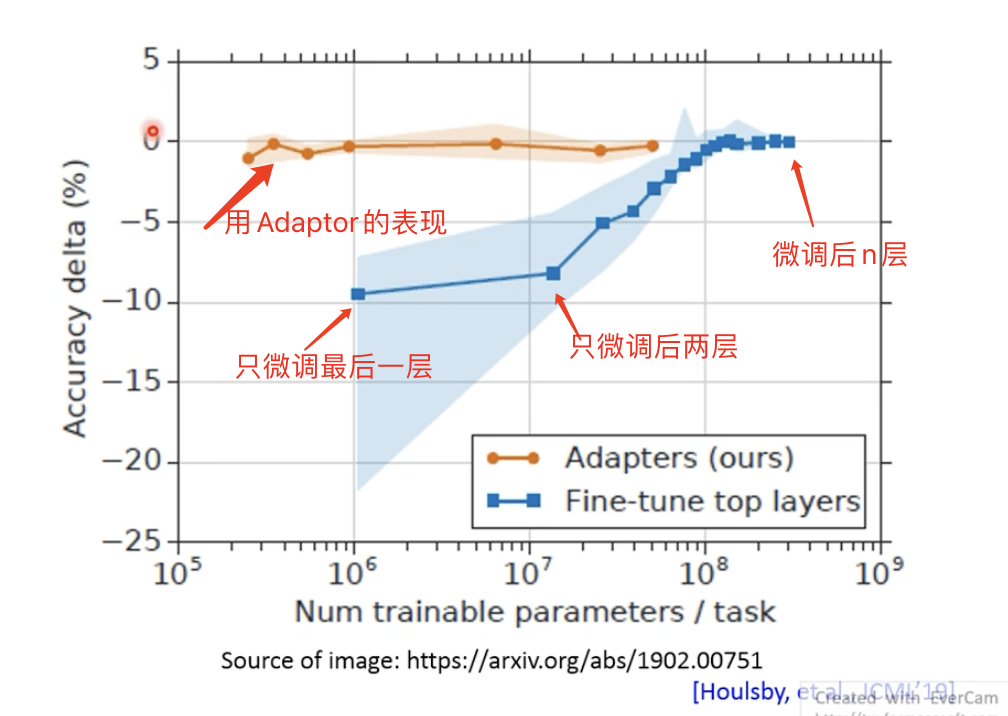
还有一个问题,如果我们fine tune整个pre-trained model 的参数的话,因为现在模型越来越大了,保存是个问题、fine tune是个问题。所以,可能会只更新一部分参数。
Adaptor只是在fine tune时插入到原模型的,在预训练时,是不存在的。一种做法是把Adaptor加在每一个Block的FC层之后,在微调时,预训练模型中只更新这部分参数。在实做中表现挺好的。

特征加权:还有一种微调方式,就是把每一层block的输出拿出来,加权平均(w1、w2、w3也可以学到),然后作为Encoder的输出。因为也许不同层学到了不同的特征。
微调方法还有很多。
3.Elmo、Bert、GPT、XLNet、ENIRC
1.Elmo
Elmo模型使用的是LSTM框架,训练时使用的是无监督学习的方法,输入一个单词w1,预测下一个单词w2,然后用w2作为下一个输入。

当然,Elmo使用的是双向LSTM。eg:对于w5,既要考虑从w1~w4传过来的记忆单元,好要考虑w7->w6传过来的记忆单元。
但是,这仍然有不足,因为从左到右也只考虑了w1~w4,没有考虑w5后面的,从右到左的也一样。总之,看到的资讯是不完整的,不是整个句子的语义。
2.GPT
GPT、Megatron、Turing NLG模型在做预测下一个token的时候,使用的是带约束的self-attention,即masked self-Attention。因为self-atttenion是把整个句子平行地读进去,然后每个位置都可以attent其他位置。 
3.Bert
Bert的训练不是通过Predict Next Token完成的;而是通过Masking input完成的。
Bert输入整个句子,然后随机mask,使用的是self-Attention;每个位置都能看到其他所有位置的资讯。
4.ERNIE
在原始Bert论文中,是随机mask input;但是,随机mask一定好吗?也许不够好
- Whole Word Masking(WWM):一次mask一个word,一个word是一个词汇或英文单词,而不是方块字或字母。也就是说,Bert mask一个字或character、WWM mask一个词汇或英文单词。(不是ERNIE)
- Phrase level&Entity-level:(ERNIE)
- Phrase level:一次盖住好几个word;
- Entity-level:先做NER,把实体找到,再mask这些实体。

5.SpanBert
关键点:mask方式不同、预测被mask的词的方式不同。
一次盖住连续的多个单词,究竟mask几个?按照概率分布来。
SpanBert在某些任务上表现好。
事实上,没有哪一个bert能够在所有的任务上都是做到第一名。
SpanBert的Mask任务还有一点不一样的地方是,Bert里预测被mask的单词是通过这个mask的单词对应的embedding来预测的;而SpanBert是mask几个连续的单词,然后用这段被mask短句的左右两边的单词的embedding来预测的,通过输入1,2,3,4来预测短句对应位置的单词。
为什么这样呢?原来bert的不好吗?我们期望的是被mask短句周围的单词能学到被mask短句的内容。
6.XLNET—— Transformer-XL
可以跨segment读资讯。
XLNET可以从Predict Next Token的观点来看,也可以从Bert的观点来看。
从LM(Language Model),即Predict Next Token观点来看:
随机打乱单词顺序,然后去预测下一个单词。其实是想让单词学到与其他单词之间的关系。(还是不太懂为啥能成功)
从Bert的观点来看:
XLNET mask机制不一样,它不是根据整个sentence预测被mask的单词,而是根据一部分(这个地方我迷了,意思就是用的不是完整的Self-Attention呗?待填坑)
而且,不用mask单词去替换被mask的单词,而是告诉模型要预测的位置【Bert是用“mask”覆盖单词,作为输入】。
Bert不擅长做generation的任务。生成任务应该是给定部分句子,预测下一个单词。
在采用AutoRegressive model的情况下,bert是不善言辞的,因为它看的是整个句子。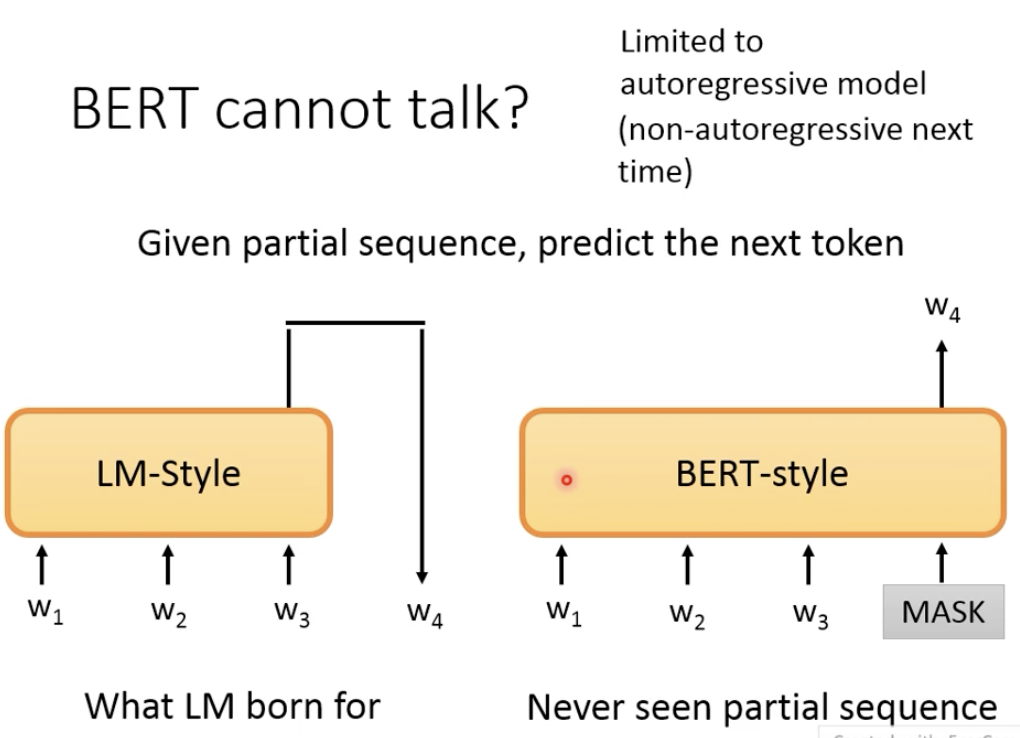
所以说,Bert不太适合做Seq2Seq的任务,只能当作是Seq2Seq任务的Encoder。
7.BART/MASS
BART和MASS能训练Seq2Seq模型,中心思想是:corrupted(破坏)与Reconstruct(重建)。
tips:Auto-encoder的思想是压缩重建。
破坏方式:
- 随机mask(用mask替换被mask单词)
- 随机删除
- sentence1和sentence2换顺序(效果不好)
- 尾部插头(效果不好)
- 填充空白(效果最好)

8.UniLM
UniLM既是Encoder、也是Decoder,还能当作Seq2Seq模型。

9.ELECTRA
ELECTRA不做mask,而是置换。
eg:cooked替换为ate
ELECTRA的输出Embedding经过一个二分类,输出结果是对应单词又没有被置换。
当然,单词不是随便替换的。
优点:
- 预测比重建任务简单
- 每一个单词的Embedding都有用到(都进行了二分类),而bert是只对mask的单词进行预测。

我们不能把单词随便替换成其他词,因为很容易找出来。而是用一个小的bert(不能用好的bert,因为不希望预测准确)模型的输出来作为替换单词。
(这一点有点像GAN,Bert生成一个单词用来替换,然后ELECTRA把它抓出来。当然也不是,因为GAN的话,是Generator和Discriminator对抗的过程,而这里的bert和ELECTRA是独立的,不会进化。

6.Multilingual Bert——多语言Bert
Bert学到的可能是语义,而非语言,不同语言在它看来区别不大。
没有必要为每一个语言训练一个bert。
用多种语言的数据来训练一个bert,当然,这样的话,词汇表会很大。
Google用104种语言训练了bert。 
对于QA任务,使用英文数据训练,中文数据测试,发现表现还不错;
使用中、英文数据混合训练,中文数据测试,发现效果比只用中文训练要好。
说明多任务学习是有帮助的。


Mean Reciprocal Rank——平均倒数排名;
值越高,说明同样语义,不同的两种语言越接近(可能两种语言是属于同一个语系的)。
继续探讨为什么用英文训练、中文测试,表现效果还很好呢?
是因为语言中有杂糅吗,如:DNA是双螺旋结构,这句话参杂了英文;
是因为中介语言吗?A跟B很像,B跟C很像。所以,用A训练,用C测试也很好。
这里有个实验,对英文的每个单词,我们创建fake的单词进行替换,暂且叫做fake-english。
然后用fake-english训练、用english测试,发现效果也很好的,说明啥?说明Bert能学到语义啊。
7.GPT3-1700亿参数!!!
GPT3是在“Language Models are Few-shot Learners” 这篇文章中提出来的。
一个只需要很少下游任务数据的model。
GPT3和GPT2没太大不同,他们都是LM,即通过Predict Next Token任务训练出来的。
对于Bert而言,要想将模型应用于下游任务,还是要有一部分标注数据拿来训练的,用来fine tune。
而GPT的目标是拿掉fine tune的过程,直接应用于下游任务!!!太狂了吧!
GPT要实现的目标是,只看到题型说明、和少数范例,就知道该怎么答题!
而且,不需要进行梯度下降!(没有啥数据,没必要梯度下降)
GPT3用少量的数据训练,在TriviaQA任务上的表现效果,超过了之前的SOTA模型!
因为GPT3是LM模型,所以,可以用GPT3做生成任务。
GPT3不适合做NLI的任务。可能是因为GPT3的训练任务是预测下一个单词。 
8.无监督学习——Linear method
无监督学习分为两种:
一种是“化繁为简”:eg:clustering&Dimension Reduction
一种是“无中生有”:eg:generation
对于“化繁为简”的任务来说,我们只有function的input;
对于“无中生有”的任务来说,我们只有function的output;
1.Cluster算法
1.K-means:常用的聚类算法

2.HAC:Hierarchical Agglomerative Clustering
关键词:根据数据的相似度,类似Huffman编码树的方式构造这棵树,然后根据K的个数,进行切分。

2.Dimension Reduction
一种方法是特征选择,即选择比较重要的特征,去除不太重要的特征;但是,当数据分布复杂时,不太好;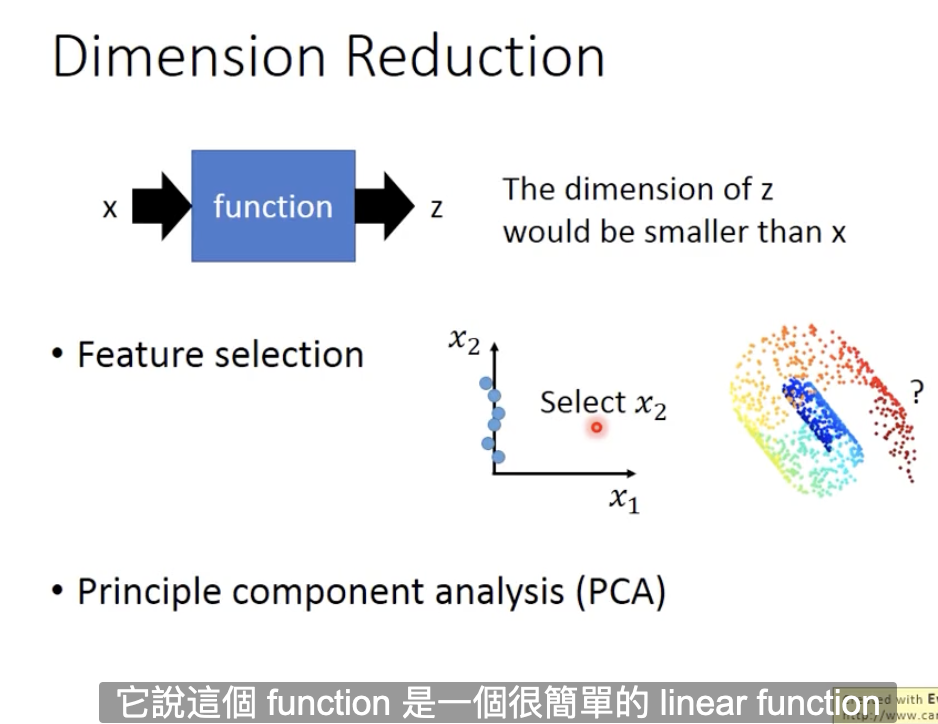
PCA:
t-SNE
t-SNE(t-distributed stochastic neighbor embedding)是用于降维的一种机器学习算法,由 Laurens van der Maaten 和 Geoffrey Hinton在08年提出。t-SNE 作为一种非线性降维算法,常用于流行学习(manifold learning)的降维过程中并与LLE进行类比,非常适用于高维数据降维到2维或者3维,便于进行可视化。
t-SNE是由SNE(Stochastic Neighbor Embedding, SNE; Hinton and Roweis, 2002)发展而来。
mainfold要做的事情就是把高维空间摊平,然后在摊平后的二维平面上,就可以用欧式举例计算两个点之间的距离了。
t-SNE会计算每个点之间的相似度,计算量比较大。所以,一般不会直接将高维数据直接降维到2维或3维,而是先用如PCA,将数据降至50维,然后再用t-SNE从50维降至2维。
t-SNE会放大point之间的距离,聚类效果更好。

若有收获,就点个赞吧
0 人点赞
