
前言
话说有一天,产品经理突然找到正在摸鱼的你。
产品:『我们要加一个聚合搜索功能,当用户在我们网站查询一件商品时,我们分别从 A、B、C 三个网站上查询这个信息,然后再把得到的结果返回给用户』
你:『哦,就是写个爬虫,从 3 个网站上抓取数据是吧?』
产品:『呸,爬虫是犯法的,这叫数据分析,怎么样,能实现吧?』
你:『可以』
产品:『好的,明天上线』
你:『。。。』
Code 1.0
你很快完成了开发,代码如下:
/*** * ** * * blog.coder4j.cn* * * Copyright (C) B0A6-B0B0 All Rights Reserved.* ***/package cn.coder4j.study.example.thread;import cn.hutool.core.thread.ThreadUtil;import com.google.common.collect.Lists;import java.util.List;/*** @author buhao* @version TestCompletionService.java, v 0.A B0B0-0B-A8 A9:0C buhao*/public class TestCompletionService {public static void main(String[] args) {// 查询信息String queryName = "java";// 调用查询接口long startTime = System.currentTimeMillis();List<String> result = queryInfoCode1(queryName);System.out.println("耗时: " + (System.currentTimeMillis() - startTime));System.out.println(result);}/*** 聚合查询信息 code 1** @param queryName* @return*/private static List<String> queryInfoCode1(String queryName) {List<String> resultList = Lists.newArrayList();String webA = searchWebA(queryName);resultList.add(webA);String webB = searchWebB(queryName);resultList.add(webB);String webC = searchWebC(queryName);resultList.add(webC);return resultList;}/*** 查询网站 A** @param name* @return*/public static String searchWebA(String name) {ThreadUtil.sleep(5000);return "webA";}/*** 查询网站B** @param name* @return*/public static String searchWebB(String name) {ThreadUtil.sleep(3000);return "webB";}/*** 查询网站C** @param name* @return*/public static String searchWebC(String name) {ThreadUtil.sleep(500);return "webC";}}
你运行了一下代码,结果如下:
耗时: 8512[webA, webB, webC]
我去,怎么请求一下要8秒多?上线了,产品还不砍死我。
debug 了一下代码,发现问题出在了请求的网站上:
/*** 查询网站 A** @param name* @return*/public static String searchWebA(String name) {ThreadUtil.sleep(5000);return "webA";}/*** 查询网站B** @param name* @return*/public static String searchWebB(String name) {ThreadUtil.sleep(3000);return "webB";}/*** 查询网站C** @param name* @return*/public static String searchWebC(String name) {ThreadUtil.sleep(500);return "webC";}
网站 A、网站 B 因为年久失修,没人维护,接口响应很慢,平均响应时间一个是 5秒,一个是 3秒(这里使用 sleep 模拟)。网站 C 性能还可以,平均响应时间 0.5 秒。 而我们程序的执行时间就是 网站A 响应时间 + 网站 B 响应时间 + 网站 C 响应时间。
Code 2.0
好了,问题知道了,因为请求的网站太慢了,那么如何解决呢?总不能打电话找他们把网站优化一下让我爬吧。书上教导我们要先从自己身上找问题。先看看自己代码哪里可以优化。
一分析代码发现,我们的代码全是串行化, A 网站请求完,再请求 B 网站,B 网站请求完再请求 C 网站。突然想到提高效率的第一要义,提高代码的并行率。为什么要一个一个串行请求,而不是 A、B、C 三个网站一起请求呢,Java 的多线程很轻松就可以实现,代码如下:
/*** * ** * * blog.coder4j.cn* * * Copyright (C) B0A6-B0B0 All Rights Reserved.* ***/package cn.coder4j.study.example.thread;import cn.hutool.core.thread.ThreadUtil;import com.google.common.collect.Lists;import java.util.List;import java.util.concurrent.ExecutionException;import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors;import java.util.concurrent.Future;/*** @author buhao* @version TestCompletionService.java, v 0.A B0B0-0B-A8 A9:0C buhao*/public class TestCompletionService {public static void main(String[] args) throws ExecutionException, InterruptedException {// 查询信息String queryName = "java";// 调用查询接口long startTime = System.currentTimeMillis();List<String> result = queryInfoCode2(queryName);System.out.println("耗时: " + (System.currentTimeMillis() - startTime));System.out.println(result);}/*** 聚合查询信息 code 1** @param queryName* @return*/private static List<String> queryInfoCode1(String queryName) {List<String> resultList = Lists.newArrayList();String webA = searchWebA(queryName);resultList.add(webA);String webB = searchWebB(queryName);resultList.add(webB);String webC = searchWebC(queryName);resultList.add(webC);return resultList;}/*** 聚合查询信息 code 2** @param queryName* @return*/private static List<String> queryInfoCode2(String queryName) throws ExecutionException, InterruptedException {List<String> resultList = Lists.newArrayList();// 创建3个线程的线程池ExecutorService pool = Executors.newFixedThreadPool(3);try {// 创建任务的 featureFuture<String> webAFuture = pool.submit(() -> searchWebA(queryName));Future<String> webBFuture = pool.submit(() -> searchWebB(queryName));Future<String> webCFuture = pool.submit(() -> searchWebC(queryName));// 得到任务结果resultList.add(webAFuture.get());resultList.add(webBFuture.get());resultList.add(webCFuture.get());} finally {// 关闭线程池pool.shutdown();}return resultList;}/*** 查询网站 A** @param name* @return*/public static String searchWebA(String name) {ThreadUtil.sleep(5000);return "webA";}/*** 查询网站B** @param name* @return*/public static String searchWebB(String name) {ThreadUtil.sleep(3000);return "webB";}/*** 查询网站C** @param name* @return*/public static String searchWebC(String name) {ThreadUtil.sleep(500);return "webC";}}
这里的重点代码如下:
/*** 聚合查询信息 code 2** @param queryName* @return*/private static List<String> queryInfoCode2(String queryName) throws ExecutionException, InterruptedException {List<String> resultList = Lists.newArrayList();// 创建3个线程的线程池ExecutorService pool = Executors.newFixedThreadPool(3);try {// 创建任务的 featureFuture<String> webAFuture = pool.submit(() -> searchWebA(queryName));Future<String> webBFuture = pool.submit(() -> searchWebB(queryName));Future<String> webCFuture = pool.submit(() -> searchWebC(queryName));// 得到任务结果resultList.add(webAFuture.get());resultList.add(webBFuture.get());resultList.add(webCFuture.get());} finally {// 关闭线程池pool.shutdown();}return resultList;}
请求网站的代码其实一行没变,变的是我们调用请求方法的地方,把之前串行的代码,变成了多线程的形式,而且还不是普通的多线程的形式,因为我们要在主线程获得线程的结果,所以还要使用 Future 的形式。(这里可以参考之前的文章【并发那些事】创建线程的三种方式)。
好的运行一下代码,看看效果,结果如下:
耗时: 5058[webA, webB, webC]
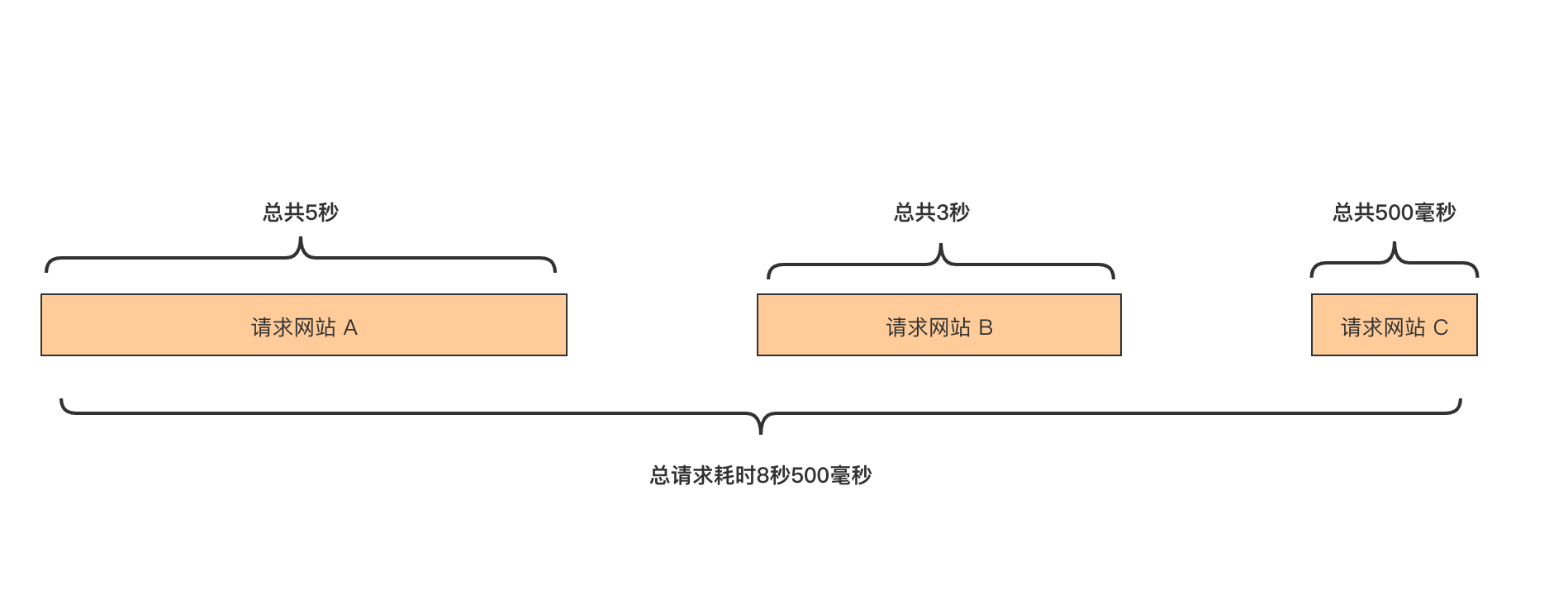
嗯,效果明显,从 8 秒多下降到了 5 秒多,但是还是很长,没法接受的长。做为一个有追求的程序员,还要去优化。我们分析一下,刚开始代码是串行的,流程如下,总请求时间是三次请求的总时长。
然后我们优化了一下,把串行请求给并行化,流程如下: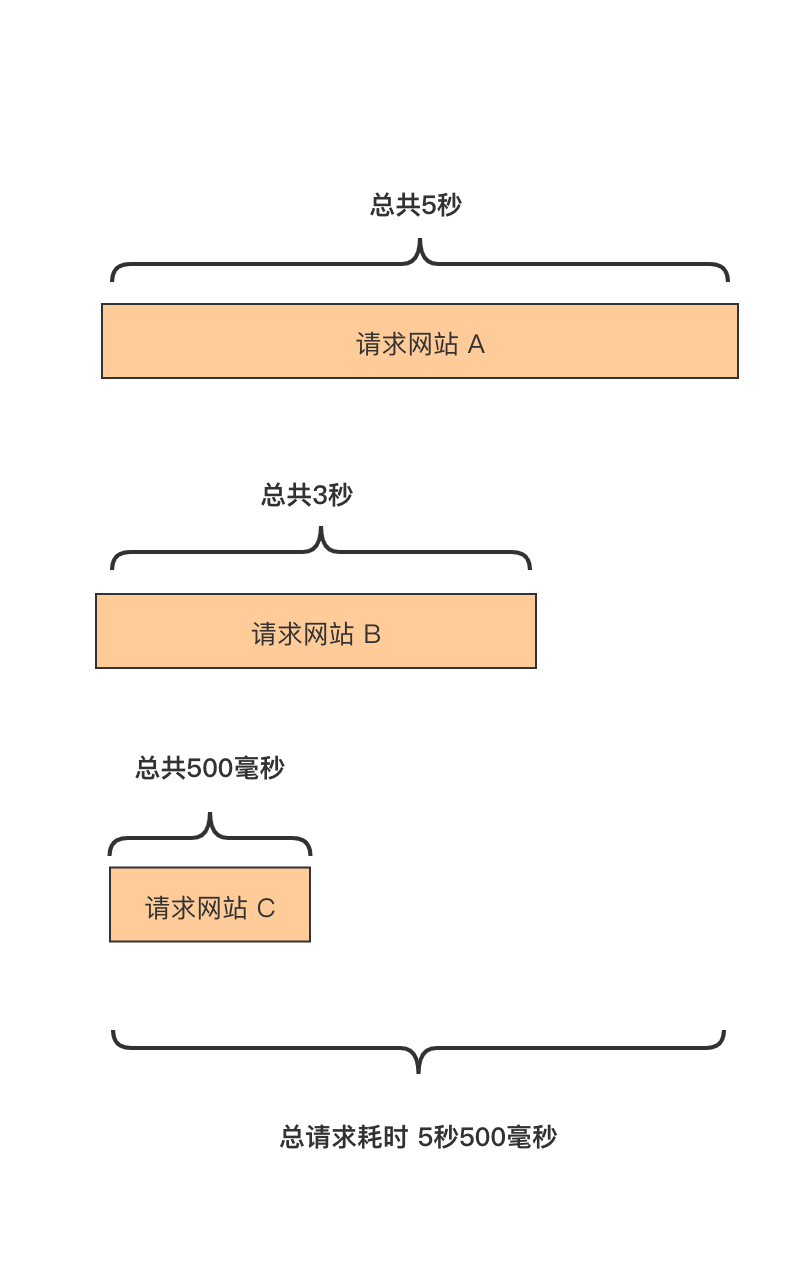
因为是并行化,类似木桶效应,决定最长时间的因素,是你请求中最耗时的的那个操作,这里是时间为 5 秒的请求 A 网站操作。
Code 3.0
其实分析到这里,在不能优化 AB 网站的请求时间的前提下,已经很难优化了。但是方法总比困难多,我们的确没办法再去压缩总请求时间,但是可以让用户体验更好一点,这里需要引入两个技术一个是 Websocket,一个是 CompletionService。其中websocket 可以简单的理解成服务端推送技术,就是不需要客户端主动请求,而是通过服务端主动推送消息(ws 在本文中不是重点,会一笔带过,具体实现可以参考前文【websocket】spring boot 集成 websocket 的四种方式),下面我们直接上代码
/*** * ** * * blog.coder4j.cn* * * Copyright (C) B0A6-B0B0 All Rights Reserved.* ***/package cn.coder4j.study.example.thread;import cn.hutool.core.thread.ThreadUtil;import com.google.common.collect.Lists;import java.util.List;import java.util.concurrent.ExecutionException;import java.util.concurrent.ExecutorCompletionService;import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors;import java.util.concurrent.Future;/*** @author buhao* @version TestCompletionService.java, v 0.A B0B0-0B-A8 A9:0C buhao*/public class TestCompletionService {public static void main(String[] args) throws ExecutionException, InterruptedException {// 查询信息String queryName = "java";// 调用查询接口long startTime = System.currentTimeMillis();queryInfoCode3(queryName);System.out.println("耗时: " + (System.currentTimeMillis() - startTime));}/*** 聚合查询信息 code 1** @param queryName* @return*/private static List<String> queryInfoCode1(String queryName) {List<String> resultList = Lists.newArrayList();String webA = searchWebA(queryName);resultList.add(webA);String webB = searchWebB(queryName);resultList.add(webB);String webC = searchWebC(queryName);resultList.add(webC);return resultList;}/*** 聚合查询信息 code 2** @param queryName* @return*/private static List<String> queryInfoCode2(String queryName) throws ExecutionException, InterruptedException {List<String> resultList = Lists.newArrayList();// 创建3个线程的线程池ExecutorService pool = Executors.newFixedThreadPool(3);try {// 创建任务的 featureFuture<String> webAFuture = pool.submit(() -> searchWebA(queryName));Future<String> webBFuture = pool.submit(() -> searchWebB(queryName));Future<String> webCFuture = pool.submit(() -> searchWebC(queryName));// 得到任务结果resultList.add(webAFuture.get());resultList.add(webBFuture.get());resultList.add(webCFuture.get());} finally {// 关闭线程池pool.shutdown();}return resultList;}/*** 聚合查询信息 code 3** @param queryName* @return*/private static void queryInfoCode3(String queryName) throws ExecutionException, InterruptedException {// 开始时间long startTime = System.currentTimeMillis();// 创建 CompletionServiceExecutorCompletionService executorCompletionService = new ExecutorCompletionService(Executors.newFixedThreadPool(3));// 创建任务的 featureexecutorCompletionService.submit(() -> searchWebA(queryName));executorCompletionService.submit(() -> searchWebB(queryName));executorCompletionService.submit(() -> searchWebC(queryName));for (int i = 0; i < 3; i++) {Future take = executorCompletionService.take();System.out.println("获得请求结果 -> " + take.get());System.out.println("通过 ws 推送给客户端,总共耗时" + (System.currentTimeMillis() - startTime));}}/*** 查询网站 A** @param name* @return*/public static String searchWebA(String name) {ThreadUtil.sleep(5000);return "webA";}/*** 查询网站B** @param name* @return*/public static String searchWebB(String name) {ThreadUtil.sleep(3000);return "webB";}/*** 查询网站C** @param name* @return*/public static String searchWebC(String name) {ThreadUtil.sleep(500);return "webC";}}
核心代码如下:
/*** 聚合查询信息 code 3** @param queryName* @return*/private static void queryInfoCode3(String queryName) throws ExecutionException, InterruptedException {// 开始时间long startTime = System.currentTimeMillis();// 创建 CompletionServiceExecutorCompletionService executorCompletionService = new ExecutorCompletionService(Executors.newFixedThreadPool(3));// 创建任务的 featureexecutorCompletionService.submit(() -> searchWebA(queryName));executorCompletionService.submit(() -> searchWebB(queryName));executorCompletionService.submit(() -> searchWebC(queryName));for (int i = 0; i < 3; i++) {Future take = executorCompletionService.take();System.out.println("获得请求结果 -> " + take.get());System.out.println("通过 ws 推送给客户端,总共耗时" + (System.currentTimeMillis() - startTime));}}
先看执行结果:
获得请求结果 -> webC通过 ws 推送给客户端,总共耗时561获得请求结果 -> webB通过 ws 推送给客户端,总共耗时3055获得请求结果 -> webA通过 ws 推送给客户端,总共耗时5060耗时: 5060
我们来分析一下执行结果,首先总耗时时间还是 5 秒多没变,但是我们不是等全部执行完再推送给客户端,而是执行完一个就推送一个,并且发现了一个规律,最先推送的是请求最快的,然后是第二快的,最后推最慢的那一个。也就是说推送结果是有序的。给用户的体验就是点击按钮后,1秒内会展示网站 C 的数据,然后过了2秒又在原有基础上又添加导示了网站 B 数据,又过了2秒,又增加展示了网站 A数据。 这种体验要比用户一直白屏 5 秒,然后一下返回所有数据要好的多。
是不是很神奇,这背后的功臣就是 CompletionService,他的源码如下:
package java.util.concurrent;/*** A service that decouples the production of new asynchronous tasks* from the consumption of the results of completed tasks. Producers* {@code submit} tasks for execution. Consumers {@code take}* completed tasks and process their results in the order they* complete. A {@code CompletionService} can for example be used to* manage asynchronous I/O, in which tasks that perform reads are* submitted in one part of a program or system, and then acted upon* in a different part of the program when the reads complete,* possibly in a different order than they were requested.** <p>Typically, a {@code CompletionService} relies on a separate* {@link Executor} to actually execute the tasks, in which case the* {@code CompletionService} only manages an internal completion* queue. The {@link ExecutorCompletionService} class provides an* implementation of this approach.** <p>Memory consistency effects: Actions in a thread prior to* submitting a task to a {@code CompletionService}* <a href="package-summary.html#MemoryVisibility"><i>happen-before</i></a>* actions taken by that task, which in turn <i>happen-before</i>* actions following a successful return from the corresponding {@code take()}.*/public interface CompletionService<V> {/*** Submits a value-returning task for execution and returns a Future* representing the pending results of the task. Upon completion,* this task may be taken or polled.** @param task the task to submit* @return a Future representing pending completion of the task* @throws RejectedExecutionException if the task cannot be* scheduled for execution* @throws NullPointerException if the task is null*/Future<V> submit(Callable<V> task);/*** Submits a Runnable task for execution and returns a Future* representing that task. Upon completion, this task may be* taken or polled.** @param task the task to submit* @param result the result to return upon successful completion* @return a Future representing pending completion of the task,* and whose {@code get()} method will return the given* result value upon completion* @throws RejectedExecutionException if the task cannot be* scheduled for execution* @throws NullPointerException if the task is null*/Future<V> submit(Runnable task, V result);/*** Retrieves and removes the Future representing the next* completed task, waiting if none are yet present.** @return the Future representing the next completed task* @throws InterruptedException if interrupted while waiting*/Future<V> take() throws InterruptedException;/*** Retrieves and removes the Future representing the next* completed task, or {@code null} if none are present.** @return the Future representing the next completed task, or* {@code null} if none are present*/Future<V> poll();/*** Retrieves and removes the Future representing the next* completed task, waiting if necessary up to the specified wait* time if none are yet present.** @param timeout how long to wait before giving up, in units of* {@code unit}* @param unit a {@code TimeUnit} determining how to interpret the* {@code timeout} parameter* @return the Future representing the next completed task or* {@code null} if the specified waiting time elapses* before one is present* @throws InterruptedException if interrupted while waiting*/Future<V> poll(long timeout, TimeUnit unit) throws InterruptedException;}
可以看到 CompletionService 方法,分别如下:
- Future
submit(Callable task); submit 用于提交一个 Callable 对象,用于提交一个可以获得结果的线程任务
- Future
submit(Runnable task, V result); submit 用于提交一个 Runnable 对象及 result 对象,类似于上面的 submit,但是 runnable 的返回值 void 无法获得线程的结果,所以添加了 result 用于做为参数的桥梁
- Future
take() throws InterruptedException; take 用于取出最新的线程执行结果,注意这里是阻塞的
- Future
poll(); take 用于取出最新的线程执行结果,是非阻塞的,如果没有结果就返回 null
- Future
poll(long timeout, TimeUnit unit) throws InterruptedException; 同上,只是加了一个超时时间
另外,CompletionService 是接口,无法直接使用,通常使用他的实现类 ExecutorCompletionService,具体使用方法如上面的 demo。
可能看到这里会很好奇 ExecutorCompletionService 实现原理,其实原理很简单,他在内部维护了一个阻塞队列,提交的任务,先执行完的先进入队列,所以你通过 poll 或 take 获得的肯定是最先执行完的任务结果。
其它
1. 项目代码
因为篇幅有限,无法贴完所有代码,如遇到问题可到github上查看源码。
关于
欢迎关注我的个人公众号 KIWI的碎碎念 ,关注后回复 福利,海量学习内容免费分享!

若有收获,就点个赞吧
0 人点赞
