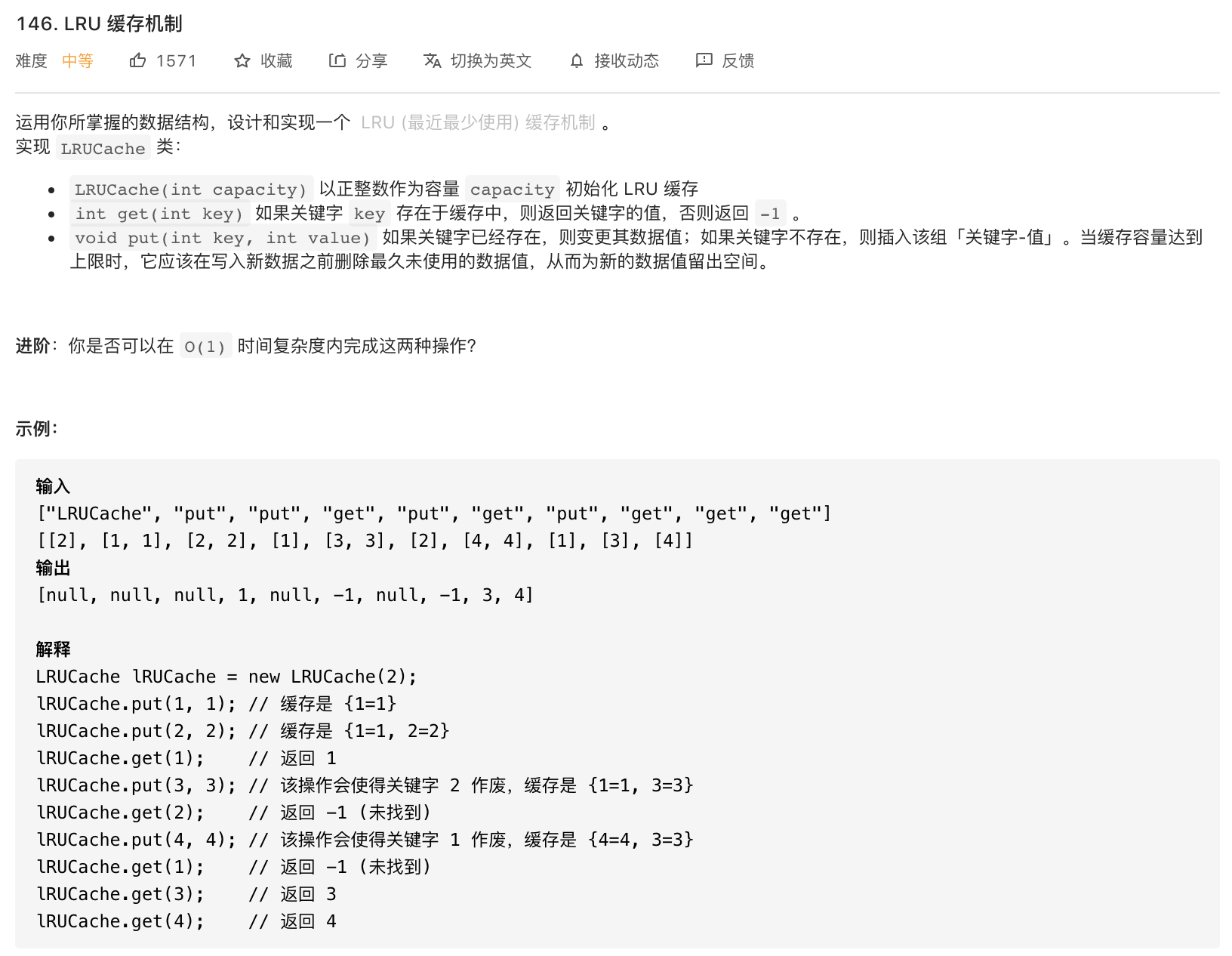
146-LRU缓存机制
代码:
package com.bxk.leetcode.design;import java.util.HashMap;import java.util.Map;import java.util.Set;public class LRUCache_146 {/**** 容量限制为capacity的Map,删除最近最少未使用的元素** put和get操作* 随机读:hash数据结构* 支持删除和插入:链表结构,node(key,value)** get逻辑:* 1、key存在,直接返回value,并将链表中该node移到头部* 2、key不存在,返回-1** put逻辑:* 1、key不存在,插入数据到链表头部,如果链表大小超过capacity容量限制,删除链表尾部元素* 2、key存在,更新hash中对应key的value,并将链表中该node移到头部*/// 定义双向链表结构class DLinkedNode {int key;int value;DLinkedNode prev;DLinkedNode next;public DLinkedNode(){}public DLinkedNode(int key, int value) {this.key = key;this.value = value;}}// 定义hash结构Map<Integer, DLinkedNode> cache = new HashMap<>();int size;int capacity;DLinkedNode head, tail;public LRUCache_146() {}public LRUCache_146(int capacity) {this.capacity = capacity;head = new DLinkedNode();tail = new DLinkedNode();head.next = tail;tail.prev = head;}public int get(int key) {DLinkedNode node = cache.get(key);if (node == null) {return -1;}moveToHead(node);return node.value;}public void put(int key, int value) {DLinkedNode node = cache.get(key);// key 不存在if (node == null){DLinkedNode newNode = new DLinkedNode(key,value);cache.put(key, newNode);addToHead(newNode);size++;if (size > capacity) {// 注意先后顺序,先删除hash中链表的最后一个元素,再从链表中移除cache.remove(tail.prev.key);removeTail();--size;}} else {// key 存在node.value = value;moveToHead(node);}}/*** get存在或put存在时,将node移动到链表头部* @param node*/public void moveToHead(DLinkedNode node) {// 删除nodenode.prev.next = node.next;node.next.prev = node.prev;addToHead(node);}/*** 更新node到链表头部* @param node*/public void addToHead(DLinkedNode node) {// 添加到 head 头部node.prev = head;node.next = head.next;head.next.prev = node;head.next = node;}/*** 删除链表尾部元素*/public void removeTail() {tail.prev.prev.next = tail;tail.prev = tail.prev.prev;}public void printDLinked(DLinkedNode head) {System.out.print("linked out: ");while (head.next != tail) {System.out.print(head.next.value + " ");head = head.next;}System.out.println();}public void printCache() {Set<Map.Entry<Integer, DLinkedNode>> set = cache.entrySet();System.out.print("cache out: ");for (Map.Entry entry : set) {System.out.print(entry.getKey() + " ");}System.out.println();}public void out() {LRUCache_146 lRUCache = new LRUCache_146(2);lRUCache.put(1, 1); // 缓存是 {1=1}lRUCache.put(2, 2); // 缓存是 {1=1, 2=2}lRUCache.printDLinked(lRUCache.head); lRUCache.printCache();System.out.println(lRUCache.get(1)); // 返回 1lRUCache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3}lRUCache.printDLinked(lRUCache.head); lRUCache.printCache();System.out.println(lRUCache.get(2)); // 返回 -1 (未找到)lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3}lRUCache.printDLinked(lRUCache.head); lRUCache.printCache();/*lRUCache.get(1); // 返回 -1 (未找到)lRUCache.get(3); // 返回 3lRUCache.get(4); // 返回 4*/}public static void main(String[] args) {LRUCache_146 lruCache = new LRUCache_146();lruCache.out();}}
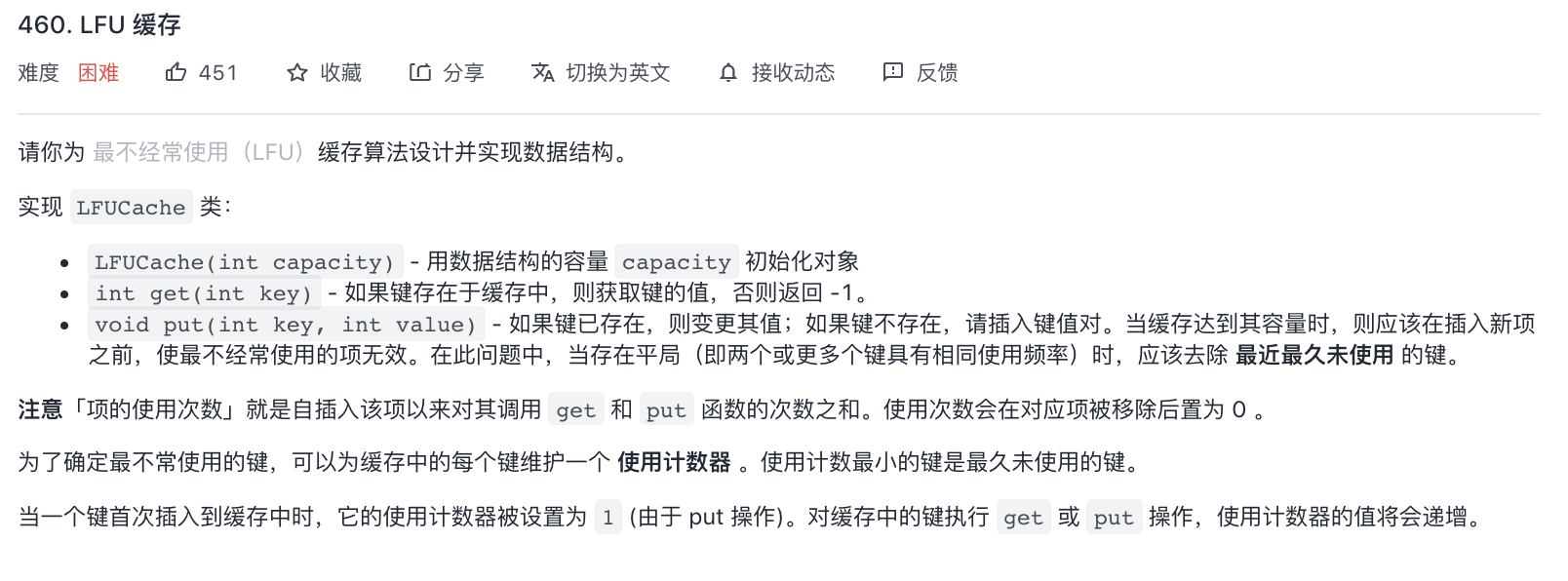
460-LFU缓存

题意分析:
- LRU是超容量删除最近最少使用的元素,LFU稍微复杂一点,在LRU基础上添加元素访问频次,先根据频次删除元素,再根据最近最少使用删除元素。
解题思路:
- 思路一:借助 cache HashMap和双向链表。双向链表用于元素访问频次的节点。
- 时间复杂度:O(capacity),每次 get/put 都要更新元素的频次(访问链表位置)
- 空间复杂度:O(capacity) ,Map需要存储所有节点信息
- 思路二:借助 cache HashMap和频次 freqMap HashMap。freqMap 存储
- 时间复杂度:O(1)
- 空间复杂度:O(capacity)
注意点:
- node 属性不一定需要用数据结构存储,可以采用 class Node 方式存储 node 属性。
- LinkedHashSet 添加元素是有序的,执行 insert/remove 的时间复杂度都为 O(1)。LinkedHashSet 也可以用 LinkedList 实现。
扩展:
代码:
package com.bxk.leetcode.design;import java.util.HashMap;import java.util.LinkedHashSet;import java.util.Map;/**** https://cloud.tencent.com/developer/article/1645636** 设计思路:(先思考设计变量数据结构,再开始具体设计逻辑实现)* 1、存储数据用于 put 和 get 操作。put => hashMap. 容量超过限制就需要溢出 最近最少使用的* 2、双向链表 cache(容量:capacity)维护最后一次使用的顺序(多 move 操作)* 3、数组 cnt[capacity] 统计每个 key 的访问次数(复杂度高:每次 put 超容量删除时都需要比较所有 key 访问次数)***/public class LFUCache_460 {public static void main(String[] args) {LFUCache1 cache = new LFUCache1(2);cache.put(1, 1);cache.put(2, 2);// 返回 1System.out.println(cache.get(1));cache.put(3, 3); // 去除 key 2// 返回 -1 (未找到key 2)System.out.println(cache.get(2));// 返回 3System.out.println(cache.get(3));cache.put(4, 4); // 去除 key 1// 返回 -1 (未找到 key 1)System.out.println(cache.get(1));// 返回 3System.out.println(cache.get(3));// 返回 4System.out.println(cache.get(4));System.out.println("----------");LFUCache2 cache2 = new LFUCache2(2);cache2.put(1, 1);cache2.put(2, 2);// 返回 1System.out.println(cache2.get(1));cache2.put(3, 3); // 去除 key 2// 返回 -1 (未找到key 2)System.out.println(cache2.get(2));// 返回 3System.out.println(cache2.get(3));cache2.put(4, 4); // 去除 key 1// 返回 -1 (未找到 key 1)System.out.println(cache2.get(1));// 返回 3System.out.println(cache2.get(3));// 返回 4System.out.println(cache2.get(4));}}/*** 借助自定义的双向链表 + HashMap** 时间复杂度:O(1)* 空间复杂度:O(capacity)** 设计启发:* 1、Node 对象优先用 Class 存储,比如 key/value/freq,数据结构以Node类型作为存储对象*/class LFUCache1 {private Map<Integer, DLinkedNode> cache;int size;int capacity;DLinkedNode head, tail;public LFUCache1(int capacity) {this.capacity = capacity;this.cache = new HashMap<>();head = new DLinkedNode();tail = new DLinkedNode();head.next = tail;tail.prev = head;}public int get(int key) {DLinkedNode node = cache.get(key);if (node == null) return -1;node.freq++;// 移动到频次排序位置moveToPosition(node);return node.value;}public void put(int key, int value) {if (capacity == 0) return;;DLinkedNode node = cache.get(key);if (node != null) {node.value = value;node.freq++;moveToPosition(node);} else {// 如果容量满了if (size == capacity) {cache.remove(head.next.key);removeNode(head.next);size--;}DLinkedNode newNode = new DLinkedNode(key, value);addNode(newNode);cache.put(key, newNode);size++;}}/*** 添加节点到头部,然后根据 freq 移动到指定位置* @param node*/private void addNode(DLinkedNode node) {node.prev = head;node.next = head.next;head.next.prev = node;head.next = node;moveToPosition(node);}/*** 只要当前 node 的 freq 大于等于后边的节点,就一直向后找,知道找到第一个比 node freq 大的节点,插入。* @param node*/private void moveToPosition(DLinkedNode node) {DLinkedNode nextNode = node.next;// 链表中删除当前节点removeNode(node);// 遍历到符合要求的节点while (node.freq >= nextNode.freq && nextNode != tail) {nextNode = nextNode.next;}// 把当前节点插入到 nextNode 前面node.prev = nextNode.prev;node.next = nextNode;nextNode.prev.next = node;nextNode.prev = node;}/*** 移除元素* @param node*/private void removeNode(DLinkedNode node) {node.prev.next = node.next;node.next.prev = node.prev;}// 定义双向链表结构class DLinkedNode {int key;int value;int freq = 1;DLinkedNode prev;DLinkedNode next;public DLinkedNode(){}public DLinkedNode(int key, int value) {this.key = key;this.value = value;}}}class LFUCache2 {private Map<Integer, DLinkedNode> cache;int size;int capacity;private Map<Integer, LinkedHashSet<DLinkedNode>> freqMap;// 记录最次频次int minFreq;public LFUCache2(int capacity) {this.capacity = capacity;cache = new HashMap<>();freqMap = new HashMap<>();}public int get(int key) {DLinkedNode node = cache.get(key);if (node == null) return -1;// 更新访问频次freqUpdate(node);return node.value;}public void put(int key, int value) {if (capacity == 0) return;DLinkedNode node = cache.get(key);if (node != null) {node.value = value;freqUpdate(node);} else {if (size == capacity) {DLinkedNode delNode = freqRemoveNode();cache.remove(delNode.key);size--;}DLinkedNode newNode = new DLinkedNode(key, value);cache.put(key, newNode);freqAddNode(newNode);size++;}}/*** freqMap 超容量删除元素** 逻辑:* 1、删除频次最小的* 2、删除相同频次最久未被访问的* @return*/private DLinkedNode freqRemoveNode() {LinkedHashSet<DLinkedNode> set = freqMap.get(minFreq);// 迭代找到第一个元素,就是最久未访问的元素,删除DLinkedNode node = set.iterator().next();set.remove(node);// 如果当前node频次等于最小频次,并且移除元素后,set为空,则 min+1if (node.freq == minFreq && set.size() == 0) {minFreq++;}return node;}/*** freqMap 新增元素** 逻辑:* 1、freq=1 频次是否存在,存在直接获取并添加到set,不存在创建新的freq=1的set* @param node*/private void freqAddNode(DLinkedNode node) {LinkedHashSet set = freqMap.get(1);if (set == null) {set = new LinkedHashSet();freqMap.put(1, set);}set.add(node);// 更新最小频次minFreq = 1;}/*** 更新 freqMap 的频次** 逻辑:* 1、从原来freq表中删除node* 2、添加到新的频次表* @param node*/private void freqUpdate(DLinkedNode node) {LinkedHashSet<DLinkedNode> set = freqMap.get(node.freq);// 从原来频次表中删除当前nodeif (set != null) {set.remove(node);}if (node.freq == minFreq && set.size() == 0) {minFreq = node.freq + 1;}// 添加到新的频次对应的链表node.freq++;LinkedHashSet<DLinkedNode> newSet = freqMap.get(node.freq);if (newSet == null) {newSet = new LinkedHashSet<>();freqMap.put(node.freq, newSet);}newSet.add(node);}// 定义双向链表结构class DLinkedNode {int key;int value;int freq = 1;public DLinkedNode(){}public DLinkedNode(int key, int value) {this.key = key;this.value = value;}}}
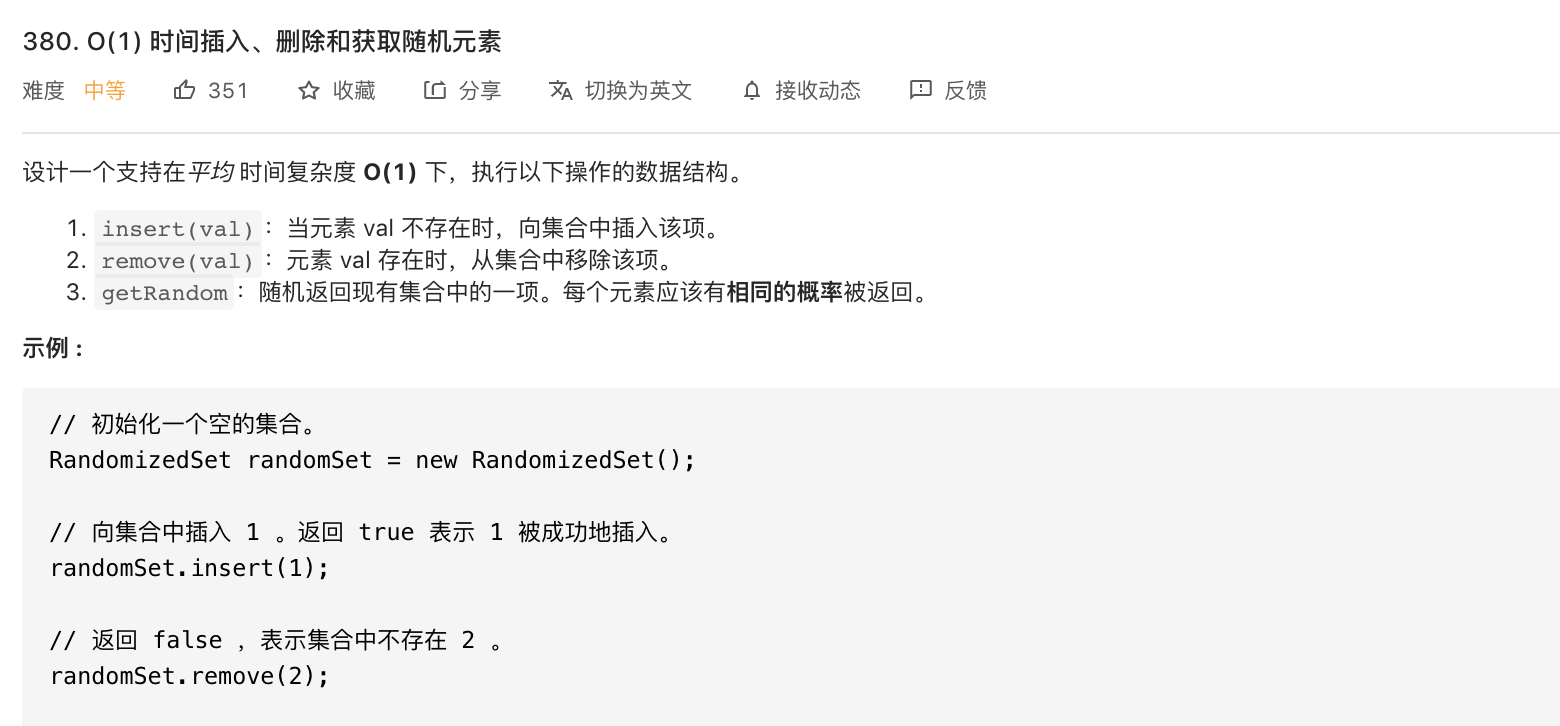
380-O(1)时间插入/删除和获取随机元素
题意分析:
- 选取合适的数据结构,将常数时间复杂度内完成元素的插入、删除和获取。
解题思路:
- 数据结构选取(动态数组 ArrayList 和 哈希表 HashMap)。熟悉各种数据结构对于插入/删除/获取等等操作的时间复杂度,比如数组读取高效,链表插入/删除高效。HasMap 对于读取索引位置数据高效。
- 插入操作和获取元素实现比较简单,最复杂的是删除元素,需要调整元素在 List 和 Map 中的位置。
注意点:
- 熟悉数据结构不常用的操作。
- ArrayList 如何交换两个位置元素。Collections.swap(list, fromIdx, toIdx)
- ArrayList 如何更新某个索引位置元素。list.set(idx, data)
- ArrayList 如何在O(1)元素。list.remove(list.size() - 1)
- HashMap 如何删除某个元素。map.remove(key)
- 调试。如何简单打印 ArrayList 和 HashMap。
代码:
package com.bxk.leetcode.design;import java.util.ArrayList;import java.util.HashMap;import java.util.List;import java.util.Map;import java.util.Random;/***设计一个支持在平均 时间复杂度 O(1) 下,执行以下操作的数据结构。insert(val):当元素 val 不存在时,向集合中插入该项。remove(val):元素 val 存在时,从集合中移除该项。getRandom:随机返回现有集合中的一项。每个元素应该有相同的概率被返回。*/public class RandomizedSet_380 {/*** 解题思路:* 1、确定数据结构选用。数组。ArrayList* 2、数组长度如何确定,以及如何扩容。(ArrayList 动态数组)* 3、是否需要辅助数据结构。哈希表*/List<Integer> list;Map<Integer, Integer> map;/** Initialize your data structure here. */public RandomizedSet_380() {list = new ArrayList<>();map = new HashMap<>();}/** Inserts a value to the set. Returns true if the set did not already contain the specified element. */public boolean insert(int val) {// 如果集合中包含该 val,则 insert 失败if (map.containsKey(val)) {return false;}map.put(val, list.size());list.add(val);// System.out.println("list = " + list.toString());// System.out.println("key = " + map.keySet().toString() + "; valus = " + map.values().toString());return true;}/** Removes a value from the set. Returns true if the set contained the specified element. */public boolean remove(int val) {// 如果集合中不包含 val,则remove失败if (!map.containsKey(val)) {return false;}// 获取集合的最后一个元素int lastEle = list.get(list.size() - 1);// 获取哈希表中 val 对应集合的索引int idx = map.get(val);// 交换后更新末尾元素在集合中的索引map.put(lastEle, idx);map.remove(val);// 交换 idx 元素和集合中末尾元素,并删除末尾元素。list.set(idx, lastEle); // 等效Collections.swap(list, idx, list.size() - 1);list.remove(list.size() - 1);// System.out.println("list = " + list.toString());// System.out.println("key = " + map.keySet().toString() + "; valus = " + map.values().toString());return true;}/** Get a random element from the set. */public int getRandom() {int rand = (new Random()).nextInt(list.size());return list.get(rand % list.size());}public static void main(String[] args) {RandomizedSet_380 obj = new RandomizedSet_380();System.out.println("-------- insert operation ---------");System.out.println("insert ret = " + obj.insert(1));System.out.println("insert ret = " + obj.insert(2));System.out.println("insert ret = " + obj.insert(3));System.out.println("insert ret = " + obj.insert(3));System.out.println("-------- get random ---------");for (int i = 0; i < 5; i++) {System.out.println("get random= " + obj.getRandom());}System.out.println("-------- remove operation ---------");System.out.println("list = " + obj.list.toString());System.out.println("key = " + obj.map.keySet().toString() + "; valus = " + obj.map.values().toString());System.out.println("remove ret = " + obj.remove(1));System.out.println("remove ret = " + obj.remove(1));System.out.println("remove ret = " + obj.remove(2));}}
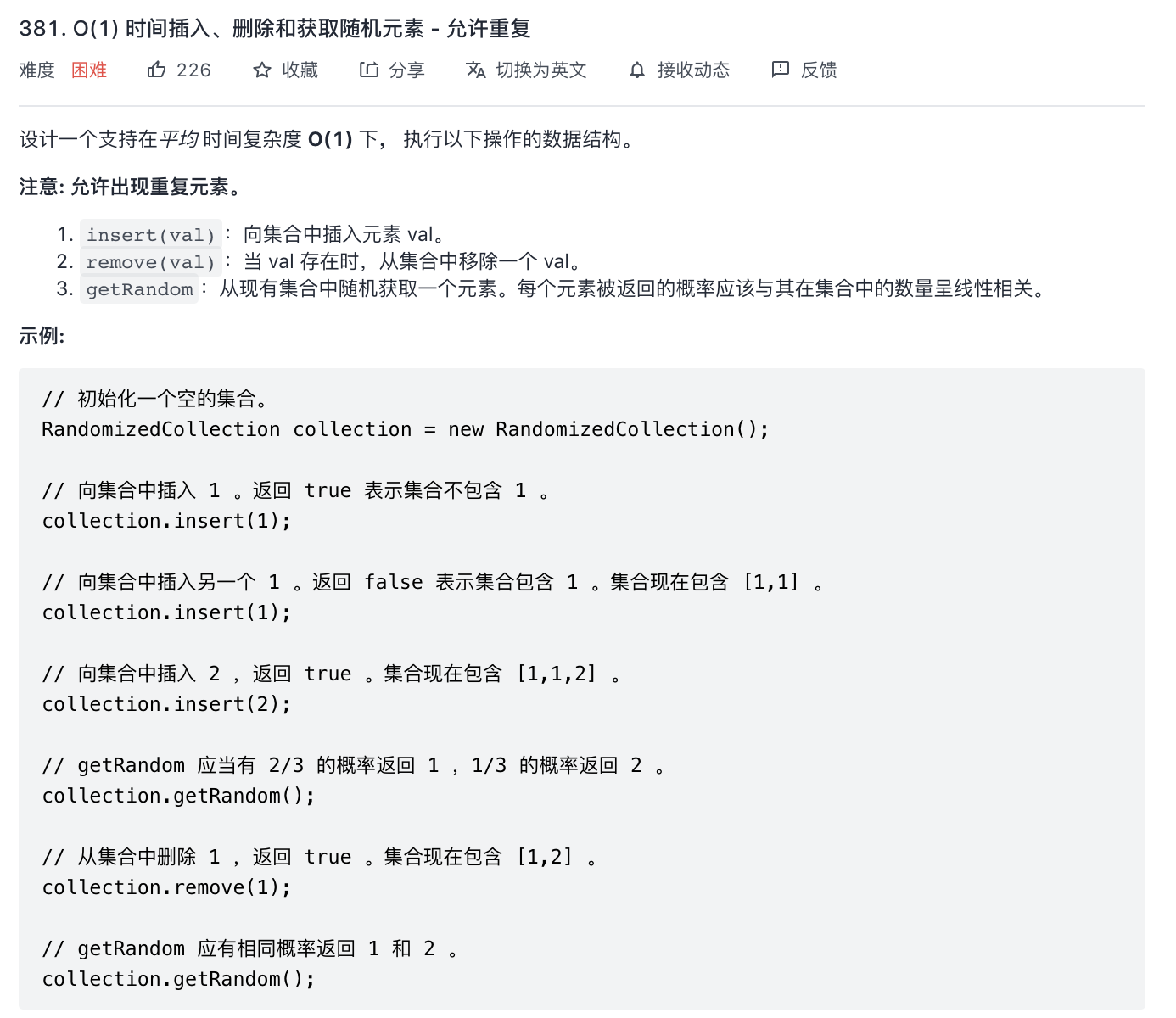
381-O(1)时间插入、删除和获取随机元素-允许重复
题意分析:
- 和 380 题类似,增加了允许元素重复的条件,这要 HashMap 就需要重新设计,保存某个 value 的在 numsList 中的所有索引。
解题思路:
- 元素信息用 ArrayList numsList 存储。
- 元素位置信息用 HashMap
注意点:
- remove 时如果是删除 numsList 末尾元素,修改该元素的 idx 信息要判断是否是删除最后一个元素。
扩展:
代码:
/*** 思路:* 1、get 操作需要 ArrayList 或者 HashMap 才能实现 O(1) 时间复杂度。(只有 value,所以这里选取 ArrayList)* 2、remove 操作需要知道要删除的元素在 ArrayList 中的位置, 所以需要辅助 HashMap 结构,由于这里元素可以重复,* 因此同一个 value 在 HashMap 中的值可能存在多个。*/public class RandomizedCollection_381 {List<Integer> numsList;Map<Integer, HashSet<Integer>> valueToIdxMap;public RandomizedCollection_381() {numsList = new ArrayList<>();valueToIdxMap = new HashMap<>();}/*** insert 逻辑:* 1、更新 numsList 集合* 2、更新 valueToIdxMap 集合* 3、返回 valueToIdxMap 的 value(HashSet).size 是否等于 1 (即是否是第一次添加)* @param val* @return*/public boolean insert(int val) {// numsList 中添加元素numsList.add(val);// HashMap 中添加元素对应索引HashSet<Integer> set = valueToIdxMap.getOrDefault(val, new HashSet<>());set.add(numsList.size()-1);valueToIdxMap.put(val, set);return set.size() == 1;}/*** remove 逻辑:* 1、元素不存在则直接返回 false。* 2、由于 numsList 删除元素必须要知道元素 idx 才能实现 O(1) 的时间复杂度。* 所以先得访问 valueToIdxMap 获取元素 value 对应在 numsList 的 idx,再值具体删除操作* @param val* @return*/public boolean remove(int val) {if (!valueToIdxMap.containsKey(val))return false;// 获取 val 对应的 idx 集合,并拿到要删除的元素位置 idxHashSet<Integer> set = valueToIdxMap.get(val);int idx = set.iterator().next();// 获取 numList 最后一个元素,用作与 idx 位置元素交换,然后删除末尾元素int lastEle = numsList.get(numsList.size() - 1);// 交换后,删除 idx 元素在 valueToIdxMap 信息,并更新 lastEle 元素在 valueTOIdxMap 信息set.remove(idx);valueToIdxMap.get(lastEle).remove(numsList.size() - 1);// 如果不是删除最后一个元素,则更新 lastEle 元素在 valueToIdxMap 的位置if (idx < numsList.size() - 1) {valueToIdxMap.get(lastEle).add(idx);}// 删除元素后 idx 的 Set 为空,则删除 valueToIdxMap 中 key 为 idx 的对象if (set.size() == 0) {valueToIdxMap.remove(val);}// 交换 numList 中 idx 元素和末尾元素numsList.set(idx, lastEle);numsList.remove(numsList.size() - 1);return true;}public int getRandom() {return numsList.get((int)(Math.random() * numsList.size()));}public static void main(String[] args) {// 初始化一个空的集合。RandomizedCollection_381 collection = new RandomizedCollection_381();// 向集合中插入 1 。返回 true 表示集合不包含 1 。collection.insert(1);// 向集合中插入另一个 1 。返回 false 表示集合包含 1 。集合现在包含 [1,1] 。collection.insert(1);// 向集合中插入 2 ,返回 true 。集合现在包含 [1,1,2] 。collection.insert(2);// getRandom 应当有 2/3 的概率返回 1 ,1/3 的概率返回 2 。collection.getRandom();// 从集合中删除 1 ,返回 true 。集合现在包含 [1,2] 。collection.remove(1);// getRandom 应有相同概率返回 1 和 2 。collection.getRandom();}}
1603-设计停车系统
题意分析:
- 判断空车位与停车的容量,不同大小车位停放不同汽车类型。
解题思路:
- if判断或者switch语句的使用。
注意点:
扩展:
- 如果考虑大容量车位可以停放满足它需求的汽车,该如何解决。比如 big 车位可以执行addCar(3)/addCar(2)/addCar(1),如何设计能够停放最多的车。
- 如果考虑到有 removeCar 操作,又该如何设计?
代码:
public class ParkingSystem {private int big;private int medium;private int small;public ParkingSystem(int big, int medium, int small) {this.big = big;this.medium = medium;this.small = small;}public boolean addCar(int carType) {if (!(carType == 1 || carType == 2 || carType == 3))return false;switch (carType) {case 1:if (big >= 1) {big--;return true;}break;case 2:if (medium >= 1) {medium--;return true;}break;case 3:if (small >= 1) {small--;return true;}break;}return false;}}
1472-设计浏览器历史记录
题意分析:
- 实现浏览器的访问/前进/后退功能。
解题思路:
- 双向链表。既要走 next 也要走 prev,双向链表是最好的选择。
注意点:
- 访问过程中新 visit 节点,需要将其后续节点置空,因此此时从当前 page 只能后退不能前进。即代码中 addNode 方法 node.next = tail 操作。
扩展:
代码:
package com.bxk.leetcode.design;/*** 设计思路:* 1、双向链表记录浏览器访问记录,需要设计链表 addNode 操作。* 2、back 操作至多 steps 步,如果 back 到链表 head 节点则返回 head。* 3、forward 操作至多 steps 步,如果 forward 到链表 tail 节点则返回 tail。*/public class BrowserHistory {// 记录单标签浏览器page页private String homepage;// 设计双向链表private DLinkedNode head;private DLinkedNode tail;// 记录链表当前访问节点private DLinkedNode curr;public BrowserHistory(String homepage) {// homepage 添加到链表中this.homepage = homepage;// 增加哨兵初始化双向链表head = new DLinkedNode();tail = new DLinkedNode();head.next = tail;tail.prev = head;curr = head;visit(homepage);}/*** 设计逻辑:* 1、新访问 page 后先将 page 添加到链表中* 2、并将 curr 当前访问页面指向新访问的页面* @param url*/public void visit(String url) {DLinkedNode visitNode = new DLinkedNode(url);addNode(visitNode);curr = visitNode;}/*** 设计逻辑:* 1、向链表 head 节点方向开始走,遇到 head 节点直接结束* @param steps* @return*/public String back(int steps) {while (steps > 0) {if (curr.prev == head) {break;} else {curr = curr.prev;}steps--;}return curr.value;}/*** 设计逻辑:* 1、向链表 tail 节点方向开始走,遇到 tail 节点直接结束* steps = 3* a-b-c(cur)-d-e-f-g* @param steps* @return*/public String forward(int steps) {while (steps > 0) {if (curr.next == tail) {break;} else {curr = curr.next;}steps--;}return curr.value;}/*** visit 时将 page 添加到链表(尾插法)* @param node*/public void addNode(DLinkedNode node) {node.prev = curr;node.next = curr.next;curr.next.prev = node;curr.next = node;// head->a->b(curr)->c->tail,此时访问 d 时,c 应该被删除掉node.next = tail;}class DLinkedNode {String value;DLinkedNode prev;DLinkedNode next;public DLinkedNode() {}public DLinkedNode(String value) {this.value = value;}}public static void main(String[] args) {String homepage = "leetcode.com";BrowserHistory browserHistory = new BrowserHistory("leetcode.com");browserHistory.visit("google.com"); // 你原本在浏览 "leetcode.com" 。访问 "google.com"browserHistory.visit("facebook.com"); // 你原本在浏览 "google.com" 。访问 "facebook.com"browserHistory.visit("youtube.com"); // 你原本在浏览 "facebook.com" 。访问 "youtube.com"browserHistory.back(1); // 你原本在浏览 "youtube.com" ,后退到 "facebook.com" 并返回 "facebook.com"browserHistory.back(1); // 你原本在浏览 "facebook.com" ,后退到 "google.com" 并返回 "google.com"browserHistory.forward(1); // 你原本在浏览 "google.com" ,前进到 "facebook.com" 并返回 "facebook.com"browserHistory.visit("linkedin.com"); // 你原本在浏览 "facebook.com" 。 访问 "linkedin.com"browserHistory.forward(2); // 你原本在浏览 "linkedin.com" ,你无法前进任何步数。browserHistory.back(2); // 你原本在浏览 "linkedin.com" ,后退两步依次先到 "facebook.com" ,然后到 "google.com" ,并返回 "google.com"browserHistory.back(7); // 你原本在浏览 "google.com", 你只能后退一步到 "leetcode.com" ,并返回 "leetcode.com"}}
1396-设计地铁系统


题意分析:
- 思路比较明确,就是记录用户进站和出站的信息,然后对其进行分析,比如求平均时间。
解题思路:
- 问题关键点在于数据结构的选取,进出站数据结构如何选取,存储哪些信息。这道题用了两个 Map 结构,一个是 Map
注意点:
- Map 采用 健值对 作为key,不太容易想到的思路。
- 判断 Map 是否包含某个 key 是根据 key 的 hashCode 比较的,因此这里要重写 hashcoe 和 equals 方法。
扩展:(很有实际意义的一道题,有了进出站用户信息,可以来进行大量数据分析)
- 如果记录相同进出站的所有用户?
- 每个站(进站/出战)每个时间段的人流量有多少?找出人流量最大 Top-k 个站。
- 进站/出站相同的用户有多少?
- 如果涉及到多条地铁线路换乘呢,同样的进出站又该如何判断,是根据时间收费还是根据进站-出站点收费呢?
代码:
package com.bxk.leetcode.design;import java.util.HashMap;import java.util.Map;/*** 设计地铁系统* 逻辑:* 1、<id,<startStation, time>> 记录进站用户信息* 2、<<startStation,endStation>, List<time>> 记录进出站对应的时间消耗* 3、时耗 List 可优化,不然 getAverageTime 需要遍历集合. <<startStation,endStation>, <totoalTime, personNum>>** 扩展:* 1、进出站相同的用户有哪些?* 2、相同进站/出站的用户有哪些?*/public class UndergroundSystem_1396 {Map<Integer, StartInfo> startMap;Map<CrossInfo, TimeSum> crossMap;public UndergroundSystem_1396() {startMap = new HashMap<>();crossMap = new HashMap<>();}/*** 进站* @param id* @param stationName* @param t*/public void checkIn(int id, String stationName, int t) {startMap.put(id, new StartInfo(stationName,t));}/*** 出站* @param id* @param stationName* @param t*/public void checkOut(int id, String stationName, int t) {// 获取进站信息StartInfo startInfo = startMap.get(id);// 构造进出站时间信息// 问题:这个构建 key 时 new 出新对象,<a,b>,<a,b> 当作两个对象放进了 Map 中,导致结果错误,应该重写 equal 方法CrossInfo crossInfo = new CrossInfo(startInfo.startStation, stationName);TimeSum timeSum = crossMap.getOrDefault(crossInfo, new TimeSum(0,0));timeSum.totalSum += t - startInfo.time;timeSum.personNum++;crossMap.put(crossInfo, timeSum);}/*** 相同进出站的平均耗时(总耗时/总人数)* @param startStation* @param endStation* @return*/public double getAverageTime(String startStation, String endStation) {TimeSum timeSum = crossMap.get(new CrossInfo(startStation, endStation));return 1.0 * timeSum.totalSum / timeSum.personNum;}// 用户 id 对应的进站信息class StartInfo {String startStation;int time;public StartInfo(String startStation, int time) {this.startStation = startStation;this.time = time;}}/*** 维护以 <进站,出站> 为 key 的 map 结构,value 为所有耗时*/class CrossInfo {String startStation;String endStation;public CrossInfo(String startStation, String endStation) {this.startStation = startStation;this.endStation = endStation;}@Overridepublic int hashCode() {return (startStation + endStation).hashCode();}@Overridepublic boolean equals(Object obj) {if (obj instanceof CrossInfo) {CrossInfo crossInfo2 = (CrossInfo)obj;if (this.startStation.equals(crossInfo2.startStation)&& this.endStation.equals(crossInfo2.endStation)) {return true;} else {return false;}} else {return false;}}}/*** 总耗时,总人数*/class TimeSum {int totalSum;int personNum;public TimeSum(int totalSum, int personNum) {this.totalSum = totalSum;this.personNum = personNum;}}public static void main(String[] args) {UndergroundSystem_1396 undergroundSystem = new UndergroundSystem_1396();undergroundSystem.checkIn(45, "Leyton", 3);undergroundSystem.checkIn(32, "Paradise", 8);undergroundSystem.checkIn(27, "Leyton", 10);undergroundSystem.checkOut(45, "Waterloo", 15);undergroundSystem.checkOut(27, "Waterloo", 20);undergroundSystem.checkOut(32, "Cambridge", 22);undergroundSystem.getAverageTime("Paradise", "Cambridge"); // 返回 14.0。从 "Paradise"(时刻 8)到 "Cambridge"(时刻 22)的行程只有一趟undergroundSystem.getAverageTime("Leyton", "Waterloo"); // 返回 11.0。总共有 2 躺从 "Leyton" 到 "Waterloo" 的行程,编号为 id=45 的乘客出发于 time=3 到达于 time=15,编号为 id=27 的乘客于 time=10 出发于 time=20 到达。所以平均时间为 ( (15-3) + (20-10) ) / 2 = 11.0undergroundSystem.checkIn(10, "Leyton", 24);undergroundSystem.getAverageTime("Leyton", "Waterloo"); // 返回 11.0undergroundSystem.checkOut(10, "Waterloo", 38);undergroundSystem.getAverageTime("Leyton", "Waterloo"); // 返回 12.0}}
1797-设计一个验证系统


题意分析:
- 根据 token 的生成时间和更新时间,统计当前时间点的有效 token 数。
解题思路:
- 构造 Map 存储 token 的有效时间,并在 generate 和 renew 时判断 token 是否过期以更新 token 的最新有效时间。
注意点:
- 过期 token 要考虑清理掉,防止 Map 结构 OOM。
- Map 遍历方式,根据要获取的 key/value 信息选择最简单的遍历方式。比如 keys()/values()/entrySet.iterator() 几种方式。
扩展:
- 能够实现时间复杂度为 O(1) 的 countUnexpireTokens
代码:
/*** 设计验证码系统*/public class AuthenticationManager {private int timeToLive;private Map<String, Integer> map;public AuthenticationManager(int timeToLive) {this.timeToLive = timeToLive;map = new HashMap<>();}/*** 逻辑:* 1、生成 token,要考虑 token 是否存在,以及是否重复申请*/public void generate(String tokenId, int currentTime) {if (map.containsKey(tokenId)) {// 更新 tokenId 时间if (map.get(tokenId) <= currentTime) {map.put(tokenId, currentTime);}} else {map.put(tokenId, currentTime);}}/*** 逻辑:* 1、更新时关键是要判断 token 是否过期。过期的不需要移除,因为更新时间不一定是真实时间。*/public void renew(String tokenId, int currentTime) {if (map.containsKey(tokenId)) {int lifecycle = map.get(tokenId) + timeToLive;// 更新时也要考虑过期时间,并且过期时间优于其他操作// 比如 lifecycle = 4 + 5, currentTime = 9,此时 token 已过期,更新无效if (lifecycle > currentTime) {map.put(tokenId, currentTime);}}}/*** 逻辑:(如何不遍历 Map,实现 O(1) 复杂度* 1、遍历 map,判断没过期的 token 数量。*/public int countUnexpiredTokens(int currentTime) {int count = 0;for(int value : map.values()) {// 题目逻辑,过期时间优于其他操作if (value + timeToLive > currentTime) {count++;} else {// 小于等于 currentTime 的 token 都已过期,需要清除掉,避免 map 结构过大map.remove(value);}}return count;}public static void main(String[] args) {AuthenticationManager authenticationManager = new AuthenticationManager(10); // 构造 AuthenticationManager ,设置 timeToLive = 5 秒。authenticationManager.renew("aaa", 1); // 时刻 1 时,没有验证码的 tokenId 为 "aaa" ,没有验证码被更新。authenticationManager.generate("aaa", 2); // 时刻 2 时,生成一个 tokenId 为 "aaa" 的新验证码。int count = authenticationManager.countUnexpiredTokens(6); // 时刻 6 时,只有 tokenId 为 "aaa" 的验证码未过期,所以返回 1 。System.out.println("count = " + count);authenticationManager.generate("bbb", 7); // 时刻 7 时,生成一个 tokenId 为 "bbb" 的新验证码。authenticationManager.renew("aaa", 8); // tokenId 为 "aaa" 的验证码在时刻 7 过期,且 8 >= 7 ,所以时刻 8 的renew 操作被忽略,没有验证码被更新。authenticationManager.renew("bbb", 11); // tokenId 为 "bbb" 的验证码在时刻 10 没有过期,所以 renew 操作会执行,该 token 将在时刻 15 过期。count = authenticationManager.countUnexpiredTokens(15); // tokenId 为 "bbb" 的验证码在时刻 15 过期,tokenId 为 "aaa" 的验证码在时刻 7 过期,所有验证码均已过期,所以返回 0System.out.println("count = " + count);}}
705-设计哈希集合
题意分析:
- 实现 HashSet 的基本功能。
解题思路:
- 问题的关键在于如何选取数据结构。举一反三,参考 Java 中 HashSet 和 HashMap 的实现,选取合适的数组结构:数组 + 链表。
注意点:
- LinkedList#remove() 操作分为 remove(int index) 和 remove(Object o) 两种,前者会进行 index 检测,如果元素数据小于 index 会抛异常。
- LinkedList 的 Iterator 遍历方法,平时用得少。
扩展:
代码:
/*** 举一反三:* HashMap 底层实现:数组 + 链表(红黑树)。* HashSet 底层实现:HashMap,因此 Hash 集合的设计也要利用“数组+链表”。** Map 特点:k-v 对,key 不重复,key 允许空* Set 特点:元素不重复,无序** 思路:* 1、Hash 问题第一反应就是要设计哈希函数,然后利用数组进行寻址,用链表存储元素*/public class MyHashSet {private static final int HASH_FACTOR = 769;LinkedList<Integer>[] data;public MyHashSet() {data = new LinkedList[HASH_FACTOR];for (int i = 0; i < HASH_FACTOR; i++) {data[i] = new LinkedList<>();}}/*** 思路:* 1、计算 hash 值,判断对应数组位置的链表是否存在相同 key*/public void add(int key) {int h = hash(key);// 遍历链表,判断元素是否存在Iterator<Integer> iter = data[h].iterator();while (iter.hasNext()) {Integer ele = iter.next();if (ele == key) {return;}}data[h].offer(key);}/*** 思路:* 1、计算 hash 值,找到对应的数组链表,不存在则直接结束*/public void remove(int key) {int h = hash(key);Iterator<Integer> iter = data[h].iterator();while (iter.hasNext()) {Integer ele = iter.next();if (ele == key) {// 注意这里 remove 调用,按 index 移除时 index 必须小于调用对象(data[h]的大小// remove(int index) 抛异常:java.lang.IndexOutOfBoundsException: Index: 2, Size: 1data[h].remove(ele);return;}}}public boolean contains(int key) {int h = hash(key);Iterator<Integer> iter = data[h].iterator();while (iter.hasNext()) {Integer ele = iter.next();if (ele == key) {return true;}}return false;}/*** 计算 hash 值*/public int hash(int key) {return key % HASH_FACTOR;}public void printSet() {for (int i = 0; i < HASH_FACTOR; i++) {// data[i] != null: new 对象后 data[i] 就不是 null,要判断元素大小if (data[i].size() != 0) {System.out.println(data[i]);}}}public static void main(String[] args) {MyHashSet myHashSet = new MyHashSet();boolean flag;myHashSet.add(1); // set = [1]myHashSet.add(2); // set = [1, 2]flag = myHashSet.contains(1); // 返回 TrueSystem.out.println(flag);flag = myHashSet.contains(3); // 返回 False ,(未找到)System.out.println(flag);myHashSet.add(2); // set = [1, 2]flag = myHashSet.contains(2); // 返回 TrueSystem.out.println(flag);myHashSet.printSet();myHashSet.remove(2); // set = [1]flag = myHashSet.contains(2); // 返回 False ,(已移除)System.out.println(flag);}}
706-设计哈希映射
题意分析:
- 实现 HashMap 的基本功能。
解题思路:
- 参考 HashSet 的实现,无非就是链表的 Integer 对象改为了 Node
注意点:
扩展:
代码:
public class MyHashMap {private static final int HASH_FACTOR = 769;LinkedList<Node>[] data;class Node {int key;int value;public Node(int key, int value) {this.key = key;this.value = value;}public int getKey() {return key;}public void setValue(int value) {this.value = value;}public int getValue() {return value;}}public MyHashMap() {data = new LinkedList[HASH_FACTOR];for (int i = 0; i < HASH_FACTOR; i++) {data[i] = new LinkedList<>();}}public void put(int key, int value) {int h = hash(key);Iterator<Node> iter = data[h].iterator();while (iter.hasNext()) {Node node = iter.next();// key 存在,更新 valueif (node.getKey() == key) {node.setValue(value);return;}}// key 不存在,添加新 Nodedata[h].offerLast(new Node(key, value));}public int get(int key) {int h = hash(key);Iterator<Node> iter = data[h].iterator();while (iter.hasNext()) {Node node = iter.next();if (node.getKey() == key) {return node.getValue();}}return -1;}public void remove(int key) {int h = hash(key);Iterator<Node> iter = data[h].iterator();while (iter.hasNext()) {Node node = iter.next();if (node.getKey() == key) {data[h].remove(node);return;}}}/*** 计算 hash 值*/public int hash(int key) {return key % HASH_FACTOR;}public static void main(String[] args) {MyHashMap myHashMap = new MyHashMap();int res;myHashMap.put(1, 1); // myHashMap 现在为 [[1,1]]myHashMap.put(2, 2); // myHashMap 现在为 [[1,1], [2,2]]res = myHashMap.get(1); // 返回 1 ,myHashMap 现在为 [[1,1], [2,2]]System.out.println(res);res = myHashMap.get(3); // 返回 -1(未找到),myHashMap 现在为 [[1,1], [2,2]]System.out.println(res);myHashMap.put(2, 1); // myHashMap 现在为 [[1,1], [2,1]](更新已有的值)res= myHashMap.get(2); // 返回 1 ,myHashMap 现在为 [[1,1], [2,1]]System.out.println(res);myHashMap.remove(2); // 删除键为 2 的数据,myHashMap 现在为 [[1,1]]res = myHashMap.get(2); // 返回 -1(未找到),myHashMap 现在为 [[1,1]]System.out.println(res);}}
707-设计链表

题意分析:
- 链表的增删查功能。
解题思路:
- 双链表实现。定义好数据结构,按功能实现。
注意点:
- addAtIndex 需要判断链表长度,来决定是否将 index 位置数据添加到链表中。
- 根据 index 遍历链表可以分为正向遍历和反向遍历,以缩短遍历次数。
扩展:
代码:
/*** 优化:* 1、while 循环改成双向遍历,减少遍历长度*/public class MyLinkedList {DLinkedNode head, tail;// addAtIndex 会判断 index 与 链表长度关系int size;public MyLinkedList() {size = 0;head = new DLinkedNode();tail = new DLinkedNode();// 双链表哨兵节点head.next = tail;tail.prev = head;}/*** 思路:* 1、遍历双链表* @param index* @return*/public int get(int index) {if (index < 0 || index >= size) return -1;/*DLinkedNode curr = head.next;int count = 0;while (curr != null && curr != tail) {if (count == index) {return curr.val;}count++;curr = curr.next;}*/DLinkedNode curr = head;if (index + 1 < size - index) {// 要遍历到 index 位置,所以遍历次数为 index + 1for (int i = 0; i < index + 1; i++) curr = curr.next;} else {curr = tail;for (int i = 0; i < size - index; i++) curr = curr.prev;}return curr.val;}/*** 链表头部添加元素* @param val*/public void addAtHead(int val) {size++;DLinkedNode node = new DLinkedNode(val);node.next = head.next;node.prev = head;// head.next.prev 和 head.next 先修改前者,因为后者会改变 head.next 指向head.next.prev = node;head.next = node;}/*** 链表尾部添加节点* @param val*/public void addAtTail(int val) {size++;DLinkedNode node = new DLinkedNode(val);node.next = tail;node.prev = tail.prev;// 顺序和 addAtHead 相同tail.prev.next = node;tail.prev = node;}/*** 指定 index 位置添加元素,找到其前驱节点** 注意当 size=0,index=1 情况,链表插入失败。* @param index* @param val*/public void addAtIndex(int index, int val) {if (index > size) return;if (index < 0 ) index = 0;// index 位置节点和前驱节点DLinkedNode pred, succ;if (index < size - index) {pred = head;// 遍历 index 位置的前驱节点,所以循遍历次数为 indexfor (int i = 0; i < index; i++) pred = pred.next;succ = pred.next;} else {succ = tail;for (int i = 0; i < size - index; i++) succ = succ.prev;pred = succ.prev;}// curr 位置插入新节点size++;DLinkedNode toAdd = new DLinkedNode(val);toAdd.next = succ;toAdd.prev = pred;pred.next = toAdd;succ.prev = toAdd;}/*** 删除执行 index 位置元素,找到其前驱节点* @param index*/public void deleteAtIndex(int index) {if (index < 0 || index >= size) return;DLinkedNode pred, succ;if (index < size - index) {pred = head;for(int i = 0; i < index; ++i) pred = pred.next;succ = pred.next;}else {succ = tail;for (int i = 0; i < size - index; ++i) succ = succ.prev;pred = succ.prev;}size--;succ.next.prev = succ.prev;pred.next = succ.next;}/*** 双向链表定义*/class DLinkedNode {int val;DLinkedNode prev;DLinkedNode next;public DLinkedNode() {}public DLinkedNode(int val) {this.val = val;}}public void printDLinkedList(DLinkedNode head) {DLinkedNode nHead = head;DLinkedNode p = nHead;System.out.print("打印链表:");while (p != null && p != tail){System.out.print(p.val + " ");p = p.next;}System.out.println();}public static void main(String[] args) {MyLinkedList linkedList = new MyLinkedList();int res;linkedList.addAtHead(1);linkedList.addAtTail(3);linkedList.printDLinkedList(linkedList.head.next);linkedList.addAtIndex(1,2); //链表变为1-> 2-> 3linkedList.printDLinkedList(linkedList.head.next);res = linkedList.get(1); //返回2System.out.println(res);linkedList.deleteAtIndex(1); //现在链表是1-> 3linkedList.printDLinkedList(linkedList.head.next);res = linkedList.get(1); //返回3System.out.println(res);}}
622-设计循环队列

题意分析:
- 实现循环队列的功能。
解题思路:
- 数组实现。
- 单链表实现。
注意点:
- 数组实现时分清队列空和队列满的情况,两者都是 front=tail。因为有 count 计数所以代码里不用单独区分。
- 单链表实现时感受头插法和尾插法的区别,头插法在出队时尾部tail不能直接拿到其前驱节点。
扩展:
代码:(数组实现——精髓)
/*** 设计循环队列:采用数组或者单链表实现** 本代码主要用数组实现。* [0,2,3,4,5,6,0] front -> 2, tail -> 6,留有一个空位*/public class MyCircularQueue_2 {int count;int capacity;int[] data;int front, tail; // 数组头/尾指针public MyCircularQueue_2(int k) {this.capacity = k;data = new int[capacity];count = 0;front = tail = 0;}/*** 向循环队列插入一个元素。如果成功插入则返回真。** 头插法:存在一个问题,enQueue 没什么问题,但 deQueue 需要遍历整个链表。* 尾插法:enQueue 利用 tail 节点,deQueue 利用 head 节点,比较方便。(ok)* @param value* @return*/public boolean enQueue(int value) {if (count == capacity) {return false;}data[tail] = value;tail = (tail + 1) % capacity;count++;return true;}/*** 从循环队列中删除一个元素。如果成功删除则返回真。** @return*/public boolean deQueue() {if (count == 0) {return false;}front = (front + 1) % capacity;count--;return true;}/*** 从队首获取元素。如果队列为空,返回 -1 。* @return*/public int Front() {if (count == 0) {return -1;}return data[front];}/*** 获取队尾元素。如果队列为空,返回 -1 。* @return*/public int Rear() {if (count == 0) {return -1;}return data[(front + count - 1) % capacity];// return data[(tail -1) % capacity]; // 先持续添加元素至容量满是 front=tail=0,tail-1 越界}public boolean isEmpty() {return count == 0;}public boolean isFull() {return count == capacity;}public static void main(String[] args) {MyCircularQueue_2 circularQueue = new MyCircularQueue_2(3); // 设置长度为 3boolean flag;int res;flag = circularQueue.enQueue(1); // 返回 trueSystem.out.println(flag);flag = circularQueue.enQueue(2); // 返回 trueSystem.out.println(flag);flag = circularQueue.enQueue(3); // 返回 trueSystem.out.println(flag);flag = circularQueue.enQueue(4); // 返回 false,队列已满System.out.println(flag);res = circularQueue.Rear(); // 返回 3System.out.println(res);flag = circularQueue.isFull(); // 返回 trueSystem.out.println(flag);flag = circularQueue.deQueue(); // 返回 trueSystem.out.println(flag);flag = circularQueue.enQueue(4); // 返回 trueSystem.out.println(flag);res = circularQueue.Rear(); // 返回 4System.out.println(res);}}
代码:(单链表实现)
/*** 设计循环队列:采用数组或者单链表实现** 本代码主要用单链表实现。*/public class MyCircularQueue {class Node {int val;Node next;public Node (int val) {this.val = val;}}// 思路链表长度int count;int capacity;Node head, tail;public MyCircularQueue(int k) {this.capacity = k;}/*** 向循环队列插入一个元素。如果成功插入则返回真。** 头插法:存在一个问题,enQueue 没什么问题,但 deQueue 需要遍历整个链表。* 尾插法:enQueue 利用 tail 节点,deQueue 利用 head 节点,比较方便。(ok)* @param value* @return*/public boolean enQueue(int value) {if (count == capacity)return false;Node node = new Node(value);if (count == 0) {head = tail = node;} else {tail.next = node;tail = node;}count++;return true;}/*** 从循环队列中删除一个元素。如果成功删除则返回真。** @return*/public boolean deQueue() {if (count == 0) {return false;}head = head.next;count--;return true;}/*** 从队首获取元素。如果队列为空,返回 -1 。* @return*/public int Front() {if (count == 0)return -1;return head.val;}/*** 获取队尾元素。如果队列为空,返回 -1 。* @return*/public int Rear() {if (count == 0)return -1;return tail.val;}public boolean isEmpty() {return count == 0;}public boolean isFull() {return count == capacity;}public static void main(String[] args) {MyCircularQueue circularQueue = new MyCircularQueue(3); // 设置长度为 3boolean flag;int res;flag = circularQueue.enQueue(1); // 返回 trueSystem.out.println(flag);flag = circularQueue.enQueue(2); // 返回 trueSystem.out.println(flag);flag = circularQueue.enQueue(3); // 返回 trueSystem.out.println(flag);flag = circularQueue.enQueue(4); // 返回 false,队列已满System.out.println(flag);res = circularQueue.Rear(); // 返回 3System.out.println(res);flag = circularQueue.isFull(); // 返回 trueSystem.out.println(flag);flag = circularQueue.deQueue(); // 返回 trueSystem.out.println(flag);flag = circularQueue.enQueue(4); // 返回 trueSystem.out.println(flag);res = circularQueue.Rear(); // 返回 4System.out.println(res);}}
355-设计推特(朋友圈时间线功能)

题意分析:
- 获取朋友圈最新消息,包括用户自己和用户关注的其他人的。
解题思路:
- 面向对象编程的精髓 + 方法的行为者(关注/取关都是 User 的行为)。关键是设计 User 和 Tweet 两个对象,一个用户维护一个 Tweet 单链表(链表元素按时间头部插入到 head 节点)一个用户关注多个用户的 Set 集合。
注意点:
- 这里的关注和取关是单向的,比如A关注B,A可以看到B的朋友圈,B无法看到A的朋友圈,取关逻辑同理。
扩展:
代码:
/*** 设计朋友圈时间线功能*/public class Twitter {// 我们需要一个映射将 userId 和 User 对象对应起来private Map<Integer, User> userMap = new HashMap<>();private static int timestamp = 0;public Twitter() {}/*** user 发表一条 tweet 动态* @param userId* @param tweetId*/public void postTweet(int userId, int tweetId) {// 如果用户不存在,则新建if (!userMap.containsKey(userId)) {userMap.put(userId, new User(userId));}User user = userMap.get(userId);user.post(tweetId);}/*** 返回该 user 关注的人(包括他自己)最近的动态 id,最多 10 条,* 而且这些动态必须按从新到旧的时间线顺序排列。** 拿到用户id及其关注的用户的所有 Tweet,取 Top 10* @param userId* @return*/public List<Integer> getNewsFeed(int userId) {List<Integer> res = new ArrayList<>();if (!userMap.containsKey(userId)) return res;// 拿到关注的用户 id(包含用户本身)Set<Integer> users = userMap.get(userId).followed;/*PriorityQueue<Tweet> priorityQueue2 = new PriorityQueue<>(users.size(), new Comparator<Tweet>() {@Overridepublic int compare(Tweet o1, Tweet o2) {return o2.time - o1.time;}});*/// 简写PriorityQueue<Tweet> priorityQueue = new PriorityQueue<>(users.size(), (a,b) -> (b.time - a.time));// 先将所有链表头节点插入优先级队列for (int id : users) {Tweet tweet = userMap.get(id).head;if (tweet == null)continue;priorityQueue.add(tweet);}// 取前 10while (!priorityQueue.isEmpty()) {if (res.size() == 10) break;// 弹出最近发表的Tweet tweet = priorityQueue.poll();res.add(tweet.id);if (tweet.next != null) {priorityQueue.add(tweet.next);}}return res;}/*** follower 关注 followee,如果 Id 不存在则新建* @param followerId* @param followeeId*/public void follow(int followerId, int followeeId) {// 若 follower 不存在,则新建if (!userMap.containsKey(followerId)) {userMap.put(followerId, new User(followerId));}// 若 followee 不存在,则新建if (!userMap.containsKey(followeeId)) {userMap.put(followeeId, new User(followeeId));}// 开始关注userMap.get(followerId).follow(followeeId);}/*** follower 取关 followee,如果 Id 不存在则什么都不做* @param followerId* @param followeeId*/public void unfollow(int followerId, int followeeId) {if (userMap.containsKey(followerId)) {userMap.get(followerId).unfollow(followeeId);}}/*** Tweet 信息*/private class Tweet {private int id;private int time;private Tweet next;public Tweet(int id, int time) {this.id = id;this.time = time;this.next = null;}}/*** 面向对象的设计原则,「关注」「取关」和「发文」应该是 User 的行为,* 况且关注列表和推文列表也存储在 User 类中,* 所以我们也应该给 User 添加 follow,unfollow 和 post 这几个方法*/private class User {private int id;// 用户关注的人private Set<Integer> followed;// 用户发表的推特链表头节点private Tweet head;public User(int userId) {followed = new HashSet<>();this.id = userId;this.head = null;follow(userId);}/*** 用户发送 tweet* @param tweetId*/public void post(int tweetId) {Tweet tweet = new Tweet(tweetId, timestamp);timestamp++;// 将新建的 tweet 头插法插入到链表中tweet.next = head;head = tweet;}/*** 用户关注其他用户* @param userId*/public void follow(int userId) {followed.add(userId);}/*** 用户取关其他用户* @param userId*/public void unfollow(int userId) {// 不可以取关自己if (userId != this.id)followed.remove(userId);}}public static void main(String[] args) {Twitter twitter = new Twitter();List<Integer> res = new ArrayList<>();twitter.postTweet(1, 5); // 用户 1 发送了一条新推文 (用户 id = 1, 推文 id = 5)res = twitter.getNewsFeed(1); // 用户 1 的获取推文应当返回一个列表,其中包含一个 id 为 5 的推文System.out.println(res);twitter.follow(1, 2); // 用户 1 关注了用户 2twitter.postTweet(2, 6); // 用户 2 发送了一个新推文 (推文 id = 6)res = twitter.getNewsFeed(1); // 用户 1 的获取推文应当返回一个列表,其中包含两个推文,id 分别为 -> [6, 5] 。推文 id 6 应当在推文 id 5 之前,因为它是在 5 之后发送的System.out.println(res);twitter.unfollow(1, 2); // 用户 1 取消关注了用户 2res = twitter.getNewsFeed(1); // 用户 1 获取推文应当返回一个列表,其中包含一个 id 为 5 的推文。因为用户 1 已经不再关注用户 2System.out.println(res);}}
模板
题意分析:
解题思路:
注意点:
扩展:
代码:

若有收获,就点个赞吧
0 人点赞
