1 内存模型
- 内存位置
- 每一个变量都是一个对象,包括作为其成员变量的对象。
- 每个对象至少占有一个内存位置。
- 基本类型都有确定的内存位置(无论类型大小如何,即使他们是相邻的,或是数组的一部分)。
- 相邻位域是相同内存中的一部分。
- 所有东西都在内存中。当两个线程访问不同的内存位置时,不会存在任何问题,一切都工作顺利。当两个线程访问同一个内存位置,就要小心了。如果没有线程更新数据,那还好;只读数据不需要保护或同步。当有线程对内存位置上的数据进行修改,那就有可能会产生条件竞争。
C++内存模型分为:
- 强内存模型:要求所有线程保持顺序一致性,即后面提到的排序一致顺序
- 指令按源码顺序执行
- 线程上的所有操作都遵循一个全局顺序:即线程B的角度看到线程A的执行顺序与线程A自己执行的顺序是一样的
-
1.1 内存顺序
不同的内存序列模型在不同的CPU架构下,功耗是不一样的,三种类型模型分为6种内存序列选项:
排序一致顺序:所有操作都不能重排;如果一个线程中将一个操作放在另一个操作前面,那么这个顺序就必须让其他线程有所了解。
- memory_order_seq_cst(所有原子类型的默认顺序):memory_order_seq_cst执行完毕后,所有cpu都是确保可以看到之前修改的最新数据的。memory_order_seq_cst指令执行后则保证真正写入内存。一个普通的读就可以看到由memory_order_seq_cst修改的数据,而memory_order_acquire则需要由memory_order_release配合才能看到,否则什么时候一个普通的load能看到memory_order_release修改的数据是不保证的。
- memory_order_acq_rel:是memory_order_acquire和memory_order_release的合并,这条语句前后的语句都不能被reorder
- 获取-释放顺序:
- memory_order_acquire:执行memory_order_acquire的cpu,可以看到别的cpu执行memory_order_release为止的语句对内存的修改。执行memory_order_acquire这条指令犹如一道栅栏,这条指令没执行完之前,后续的访问内存的指令都不能执行,这包括读和写。
- memory_order_release:执行memory_order_release的cpu,在这条指令执行前的对内存的读写指令都执行完毕,这条语句之后的对内存的修改指令不能超越这条指令优先执行。这也象一道栅栏。在这之后,别的cpu执行memory_order_acquire,都可以看到这个cpu所做的memory修改
- memory_order_consume:程序可以说明哪些变量有依赖关系,从而只需要同步这些变量的内存。类似于memory_order_acquire,但是只对有依赖关系的内存。意思是别的CPU执行了memory_order_release操作,而其他依赖于这个atomic变量的内存会被执行memory_order_consume的CPU看到。
- 松散顺序:
std::atomic
void write_x() { x.store(true, std::memory_order_seq_cst); // 1 }
void write_y() { y.store(true, std::memory_order_seq_cst); // 2 } void read_x_then_y() { while (!x.load(std::memory_order_seq_cst)); if (y.load(std::memory_order_seq_cst)) // 3 ++z; } void read_y_then_x() { while (!y.load(std::memory_order_seq_cst)); if (x.load(std::memory_order_seq_cst)) // 4 ++z; } int main() { x = false; y = false; z = 0; std::thread a(write_x); std::thread b(write_y); std::thread c(read_x_then_y); std::thread d(read_y_then_x); a.join(); b.join(); c.join(); d.join(); assert(z.load() != 0); // 5 }
代码中断言5一定成果,因为不是存储x的操作①发生,就是存储y的操作②发生,导致Z最后不可能为0。<a name="QwxXK"></a>### 获取-释放顺序这个序列是松散序列(relaxed ordering)的加强版;虽然操作依旧没有统一的顺序,但是在这个序列引入了同步。这种序列模型中:- 原子加载就是获取(acquire)操作(memory_order_acquire)- 原子存储就是释放(memory_order_release)操作,原子读-改-写操作释放操作与获取操作同步,这样就能读取已写入的值。这意味着不同线程看到的序列虽不同,但这些序列都是受限的。**memory_order_acquire示例:**```cpp/*原子操作的内存顺序:获取释放序列memory_order_acquire*/#include <atomic>#include <thread>#include <assert.h>#include <iostream>std::atomic<bool> x, y;std::atomic<int> z;void write_x(){x.store(true, std::memory_order_release);}void write_y(){y.store(true, std::memory_order_release);}void read_x_then_y(){while (!x.load(std::memory_order_acquire));if (y.load(std::memory_order_acquire)) // 1++z;}void read_y_then_x(){while (!y.load(std::memory_order_acquire));if (x.load(std::memory_order_acquire)) // 2++z;}int main(){x = false;y = false;z = 0;std::thread a(write_x);std::thread b(write_y);std::thread c(read_x_then_y);std::thread d(read_y_then_x);a.join();b.join();c.join();d.join();assert(z.load() != 0); // 3}
③可能会失败,因为可能在加载②和y①的时候,读取到的是false。因为x和y是由不同线程写入,所以序列中的每一次释放到获取都不会影响到其他线程的操作。
松散顺序
原子类型上的操作以松散序列执行,没有任何同步关系。同一线程中对于同一变量的操作还是服从先发执行的关系,但是不同线程几乎不需要相对的顺序。唯一的要求是在访问同一线程中的单个原子变量不能重排序,当给定线程看到原子变量的特定值时,随后线程的读操作就不会去检索变量较早的那个值。
当使用memory_order_relaxed,就不需要任何额外的同步,对于每个变量的修改顺序只是线程间共享的事情。
/*原子操作的内存顺序:松散序列memory_order_relaxed*/#include <atomic>#include <thread>#include <iostream>#include <assert.h>std::atomic<bool> x, y;std::atomic<int> z;void write_x_then_y16(){//1在2前面执行x.store(true, std::memory_order_relaxed); // 1y.store(true, std::memory_order_relaxed); // 2}void read_y_then_x16(){//3在4前面执行while (!y.load(std::memory_order_relaxed)); // 3if (x.load(std::memory_order_relaxed)) // 4++z;}int main(){x = false;y = false;z = 0;std::thread t1(write_x_then_y16);std::thread t2(read_y_then_x16);t1.join();t2.join();assert(z.load() != 0); // 5}
语句5断言可能会失败,加载x的操作④可能读取到false,即使加载y的操作③读取到true,并且存储x的操作①先发与存储y的操作②。因为x和y是两个不同的变量,memory_order_relaxed不会保证前后语句的执行顺序。
1.2 atomic_thread_fence
如果原子操作库缺少了栅栏,那么这个库就不完整。栅栏操作会对内存序列进行约束,使其无法对任何数据进行修改,典型的做法是与使用memory_order_relaxed约束序的原子操作一起使用。栅栏属于全局操作,执行栅栏操作可以影响到在线程中的其他原子操作。
我们给在不同线程上的两个原子操作中添加一个栅栏,代码如下所示,栅栏可以让自由操作变的有序:
#include <atomic>#include <thread>#include <assert.h>#include <iostream>std::atomic<bool> x, y;std::atomic<int> z;void write_x_then_y(){x.store(true, std::memory_order_relaxed); // 1 设置x为truestd::atomic_thread_fence(std::memory_order_release); // 2 释放栅栏y.store(true, std::memory_order_relaxed); // 3 设置y为true}void read_y_then_x(){while (!y.load(std::memory_order_relaxed)); // 4 等待y为true时退出循环,保证4一定在3之后执行std::atomic_thread_fence(std::memory_order_acquire); // 5 获取栅栏if (x.load(std::memory_order_relaxed)) // 6 读取x的值++z;}int main(){x = false;y = false;z = 0;std::thread a(write_x_then_y);std::thread b(read_y_then_x);a.join();b.join();assert(z.load() != 0); // 7 z=1,断言不会触发}
- 在没有添加atomic_thread_fence时,a,b两个线程中对x的写入和读取时没有确定顺序的(relaxed模式),所以有概率出现先执行x.load,后执行x.store,导致z最后的值为0,从而触发断言7。
- 添加了atomic_thread_fence之后,步骤2和5同步。要获取栅栏,必须先等待栅栏释放,从而步骤1肯定要在步骤6前面运行,即保证了确定的顺序:先x.store,后x.load。所以结果时确定的,z=1,断言7不会触发。
使用栅栏的想法是:当获取操作能看到释放栅栏操作后的存储结果,那么这个栅栏就与获取操作同步;并且,当加载操作在获取栅栏操作前,看到一个释放操作的结果,那么这个释放操作同步于获取栅栏。当然,也可以使用双边栅栏操作,举一个简单的例子:当一个加载操作在获取栅栏前,看到一个值有存储操作写入,且这个存储操作发生在释放栅栏后,那么释放栅栏与获取栅栏同步。同步点,就是栅栏本身。
2 原子操作
原子操作是个不可分割的操作。系统的所有线程中,不可能观察到原子操作完成了一半;要么就是做了,要么就是没做,只有这两种可能。
2.1 标准原子类型
标准原子类型定义在头文件**<atomic>**中。这些类型的所有操作都是原子的,语言定义中只有这些类型的操作是原子的。下面的原子类型都可以通过特化std::atomic<>类型模板得到,并且拥有更多的功能(不追求功能可以直接使用原子类型:
表 标准原子类型和与其相关的std::atomic<>特化类
| 原子类型 | 相关特化类 |
|---|---|
| atomic_bool | std::atomic |
| atomic_char | std::atomic |
| atomic_schar | std::atomic |
| atomic_uchar | std::atomic |
| atomic_int | std::atomic |
| atomic_uint | std::atomic |
| atomic_short | std::atomic |
| atomic_ushort | std::atomic |
| atomic_long | std::atomic |
| atomic_ulong | std::atomic |
| atomic_llong | std::atomic |
| atomic_ullong | std::atomic |
| atomic_char16_t | std::atomic |
| atomic_char32_t | std::atomic |
| atomic_wchar_t | std::atomic |
std::atomic<>类模板是一个通用类模板,操作被限制为(具体顺序介绍见3.3节):
- Store操作,可选如下顺序:
memory_order_relaxed,memory_order_release,memory_order_seq_cst。 - Load操作,可选如下顺序:
memory_order_relaxed,memory_order_consume,memory_order_acquire,memory_order_seq_cst。 - Read-modify-write(读-改-写)操作,可选如下顺序:
memory_order_relaxed,memory_order_consume,memory_order_acquire,memory_order_release,memory_order_acq_rel,memory_order_seq_cst
C++标准库不仅提供基本原子类型,还定义了与原子类型对应的非原子类型:
| 原子类型定义 | 标准库中相关类型定义 |
|---|---|
| atomic_int_least8_t | int_least8_t |
| atomic_uint_least8_t | uint_least8_t |
| atomic_int_least16_t | int_least16_t |
| atomic_uint_least16_t | uint_least16_t |
| atomic_int_least32_t | int_least32_t |
| atomic_uint_least32_t | uint_least32_t |
| atomic_int_least64_t | int_least64_t |
| atomic_uint_least64_t | uint_least64_t |
| atomic_int_fast8_t | int_fast8_t |
| atomic_uint_fast8_t | uint_fast8_t |
| atomic_int_fast16_t | int_fast16_t |
| atomic_uint_fast16_t | uint_fast16_t |
| atomic_int_fast32_t | int_fast32_t |
| atomic_uint_fast32_t | uint_fast32_t |
| atomic_int_fast64_t | int_fast64_t |
| atomic_uint_fast64_t | uint_fast64_t |
| atomic_intptr_t | intptr_t |
| atomic_uintptr_t | uintptr_t |
| atomic_size_t | size_t |
| atomic_ptrdiff_t | ptrdiff_t |
| atomic_intmax_t | intmax_t |
| atomic_uintmax_t | uintmax_t |
2.2 std::atomic<>类模板
不是任何自定义类型都可以使用std::atomic<>的:需要满足一定的标准才行。为了使用std::atomic<UDT>(UDT是用户定义类型),这个类型必须有拷贝赋值运算符,即
- 这个类型不能有任何虚函数或虚基类
- 必须使用编译器创建的拷贝赋值操作
- 所有的基类和非静态数据成员也都需要支持拷贝赋值操作
当使用用户定义类型T进行实例化时,std::atomic<T>的可用接口就只有: load(), store(), exchange(), compare_exchange_weak(), compare_exchange_strong()和赋值操作,以及向类型T转换的操作。下表列举了每一个原子类型所能使用的操作。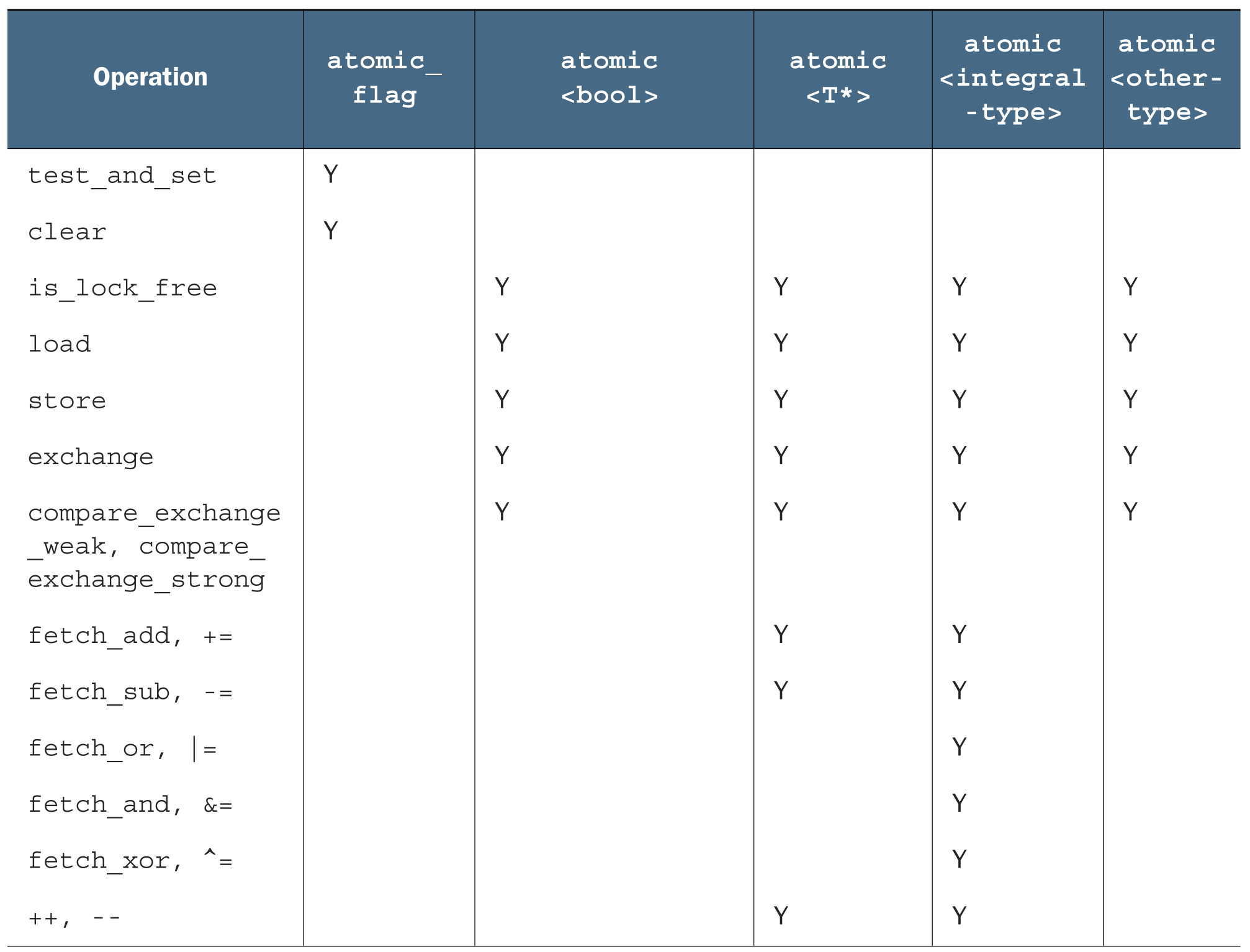
2.3 std::atomic_flag
std::atomic_flag是最简单的原子类型,它表示了一个布尔标志。这个类型的对象可以在两个状态间切换:设置和清除。主要操作有:
- 初始化:
std::atomic_flag类型的对象必须被ATOMIC_FLAG_INIT初始化,初始化标志位是“清除”状态。 - 释放:clear()成员函数,clear()是一个存储操作,所以不能有memory_order_acquire或memory_order_acq_rel语义
- 清除和设置:test_and_set()成员函数,并返回修改前的值
std::atomic_flag对象不能拷贝和赋值,简单操作示例如下:
/*使用std:atomic_flag实现自旋互斥锁*/#include <iostream>#include <thread>#include <atomic>#include <vector>using namespace std;std::atomic_flag lock = ATOMIC_FLAG_INIT;//初始化void f(int n){for (int cnt = 0; cnt < 2; ++cnt) {while (lock.test_and_set(std::memory_order_acquire)) // 获得锁; // 如果返回值为清除,则一直循环(自旋)std::cout << "Output from thread " << n << '\n';lock.clear(std::memory_order_release); // 释放锁}}int main(){std::vector<std::thread> v;for (int n = 0; n < 10; ++n) {v.emplace_back(f, n);}for (auto& t : v) {t.join();}return 0;}
2.4 std::atomic
最基本的原子整型类型就是std::atomic<bool>。它有着比std::atomic_flag更加齐全的布尔标志特性。虽然依旧不能拷贝构造和拷贝赋值,但可以使用非原子的bool类型进行构造,所以可以被初始化为true或false,并且可以从非原子bool变量赋值给std::atomic<bool>:
std::atomic<bool> b(true);//初始化为trueb=false;//使用非原子的bool类型赋值
主要操作有:
- 写入true或false:store函数
- 加载:load()
- “读-改-写”:
- exchange()成员函数:允许使用新选的值替换已存储的值,并且会自动检索原始值。
- compare_exchange_weak()和compare_exchange_strong():比较原子变量的当前值和一个期望值,当两值相等时,存储所提供的值;当两值不等,期望值就会被更新为原子变量中的值。
使用示例: ```cppstd::atomic<bool> b;bool x=b.load(std::memory_order_acquire);//加载原子bool类型b.store(true);//写入新值x=b.exchange(false, std::memory_order_acq_rel);//返回原值,并写入false
include
include
include
std::vector
void reader_thread() { while(!data_ready.load()) // 1 { std::this_thread::sleep(std::milliseconds(1)); } std::cout<<”The answer=”<<data[0]<<”\m”; // 2 } void writer_thread() { data.push_back(42); // 3 data_ready=true; // 4 }
`std::atomic<bool>`和`std::atomic_flag`的不同之处在于,`std::atomic<bool>`可能不是无锁的。为了保证操作的原子性,**其实现中可能需要一个内置的互斥量**。特殊情况时,可以使用is_lock_free()成员函数,检查`std::atomic<bool>`上的操作是否无锁。这是除了`std::atomic_flag`之外,另一个所有原子类型都拥有的特征(is_lock_free)。<a name="gElzh"></a>## 2.5 std::atomic<T*>:指针运算原子指针类型,可以使用内置类型或自定义类型T,通过特化`std::atomic<T*>`进行定义。就像`std::atomic<bool>`,虽然**既不能拷贝构造,也不能拷贝赋值**,但是**可以通过合适的类型指针进行构造和赋值**。<br />主要操作有:- 是否无锁:成员函数is_lock_free()一样- `std::atomic<T*>`也有load(), store(), exchange(), compare_exchange_weak()和compare_exchage_strong()成员函数,与`std::atomic<bool>`的语义相同,获取与返回的类型都是T*。- fetch_add()和fetch_sub():在存储地址上做原子加法和减法,为+=, -=, ++和--提供简易的封装。```cppclass Foo{};Foo some_array[5];std::atomic<Foo*> p(some_array);Foo* x=p.fetch_add(2); // p加2,并返回原始值assert(x==some_array);assert(p.load()==&some_array[2]);x=(p-=1); // p减1,并返回原始值assert(x==&some_array[1]);assert(p.load()==&some_array[1]);

若有收获,就点个赞吧
0 人点赞
