RabbitMQ是一个由erlang开发的AMQP(Advanved Message Queue Protocol)的开源实现。
1. 核心概念
- Message
- 消息,消息是不具名的,它由消息头和消息体组成
- 消息头,包括routing-key(路由键)、priority(相对于其他消息的优先权)、delivery-mode(指出该消息可能需要持久性存储)等
- Publisher
- 消息的生产者,也是一个向交换器发布消息的客户端应用程序
- Exchange
- 交换器,将生产者消息路由给服务器中的队列
- 类型有direct(默认),fanout, topic, 和headers,具有不同转发策略
- Queue
- 消息队列,保存消息直到发送给消费者
- Binding
- 绑定,用于消息队列和交换器之间的关联
- Connection
- 网络连接,比如一个TCP连接
- Consumer
- 消息的消费者,表示一个从消息队列中取得消息的客户端应用程序
- Virtual Host
- 虚拟主机,表示一批交换器、消息队列和相关对象。
- vhost 是 AMQP 概念的基础,必须在连接时指定
- RabbitMQ 默认的 vhost 是 /
- Broker
- 消息队列服务器实体
2.交换机类型
2.1 Direct Exchange
直连型交换机,根据消息携带的路由键将消息投递给对应队列。
大致流程:有一个队列绑定到一个直连交换机上,同时赋予一个路由键 RouteKey 。然后当一个消息携带着路由值为X,这个消息通过生产者发送给交换机时,交换机就会根据这个路由值X去寻找绑定值也是X的队列。
点对点模式,消息中的路由键(routing key)如果和 Binding 中的 bindingkey 一致, 交换器就将消息发到对应的队列
中。
注意:Director模式可以使用Rabbitmq自带的Exchange:default Exchange,所以不需要将Exchange进行任何绑定(binging)操作,消息传递时,RouteKey必须完全匹配才会被队列接收,否则消息会被抛弃
2.2 Fanout Exchange
扇型交换机,不处理路由键,只需简单的将队列绑定到交换机上。
发送到交换机的消息都会被转发到该交换机绑定的所有队列上Fanout交换机转发消息是最快的,性能是最好的原因是不做路由匹配,路由规则等等
广播模式,每个发到 fanout 类型交换器的消息都会分到所有绑定的队列上去
2.3 Topic Exchange
主题交换机,这个交换机其实跟直连交换机流程差不多,但是它的特点就是在它的路由键和绑定键之间是有规则的。
所有发送到Topic Exchange的消息被转发到所有关心RouteKey中指定Topic Queue。Exchange将RouteKey和某Topic进行模糊匹配,此时队列需要绑定一个Topic
注意:可以使用通配符模糊匹配
符号 “#” 匹配一个或者多个词
符号 “*” 匹配不多不少一个词
例如: log.# 能够匹配到 “log.info.oa”
log. 只会匹配到log.error
主题交换机是非常强大的,为啥这么膨胀?
当一个队列的绑定键为 “#”(井号) 的时候,这个队列将会无视消息的路由键,接收所有的消息。当 (星号) 和 # (井号) 这两个特殊字符都未在绑定键中出现的时候,此时主题交换机就拥有的直连交换机的行为。所以主题交换机也就实现了扇形交换机的功能,和直连交换机的功能。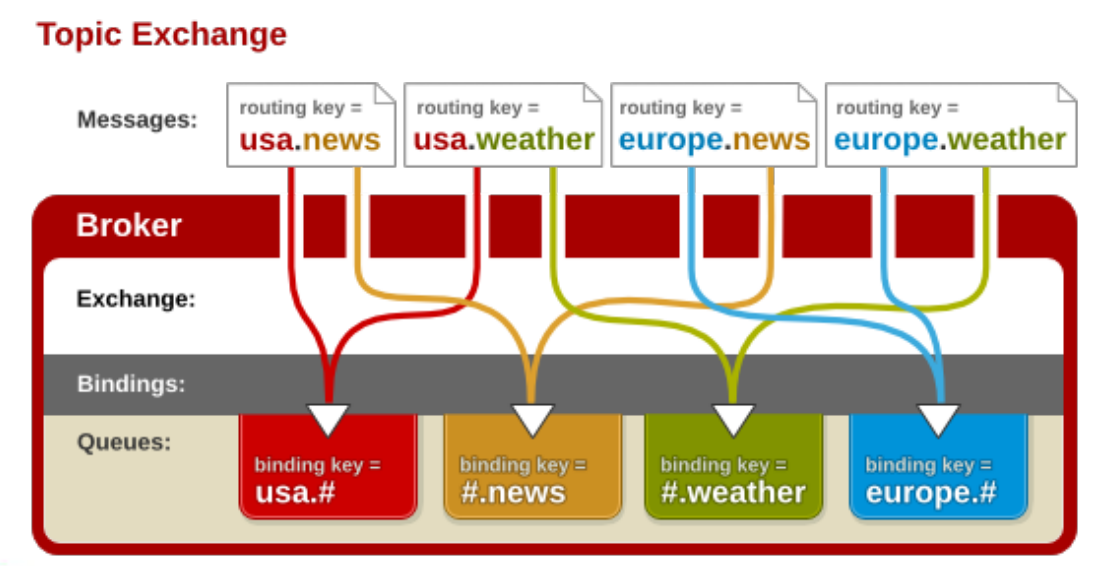
3.确认消息机制-可靠抵达
保证消息不丢失,可靠抵达,可以使用事务消息,性能下降250倍,为此引入确认机制。
- publisher comfirmCallback 确认模式
- publisher returnCallback 未投递到quque退回模式
- cunsumer ack机制

4.可靠抵达-ComfirmCallback
spring.rabbitmq.publisher-confirms=true
spring.rabbitmq.publisher-returns=true
- spring.rabbitmq.template.mandatory=true
- confirm模式只能保证消息倒带 broker,不能保证消息准确投递到目标queue里,还有些业务场景下,我们需要保证消息一定要投递到目标queue里,此时就需要用到return退回模式
- 这样如果未能投递到目标queue里将调用returnCallback,可以记录下详细到投递数据,定期的巡检或者自动纠错都需要这些数据
参考连接: https://www.rabbitmq.com/admin-guide.html
6.普通http同步请求、基于线程池的异步请求、基于消息队列的请求三者的比较
多线程当然是速度最优的方式,不过它比较依赖服务器的配置,由于都是在系统内部进行,也存在这请求丢失的风险;队列消息是性价比最优的方式,不吃配置,请求不会因系统的问题而丢失,而且队列消息所在的服务器一般都比较稳定(毕竟没有什么业务操作),不过它无法提升访问速度;其实呢,每种方式都有利有弊,最重要的还是要看你面对的业务逻辑和实际情况
7.为什么使用消息队列?消息队列有什么优点和缺点?Kafka、ActiveMQ、RabbitMQ、RocketMQ 都有什么优点和缺点?
其实就是问问你消息队列都有哪些使用场景,然后你项目里具体是什么场景,说说你在这个场景里用消息队
列是什么?
面试官问你这个问题,期望的一个回答是说,你们公司有个什么业务场景,这个业务场景有个什么技术挑战,
如果不用 MQ 可能会很麻烦,但是你现在用了 MQ 之后带给了你很多的好处。
先说一下消息队列常见的使用场景吧,其实场景有很多,但是比较核心的有 3 个:解耦、异步、削峰。
解耦
看这么个场景。A 系统发送数据到 BCD 三个系统,通过接口调用发送。如果 E 系统也要这个数据呢?那如
果 C 系统现在不需要了呢?A 系统负责人几乎崩溃…… 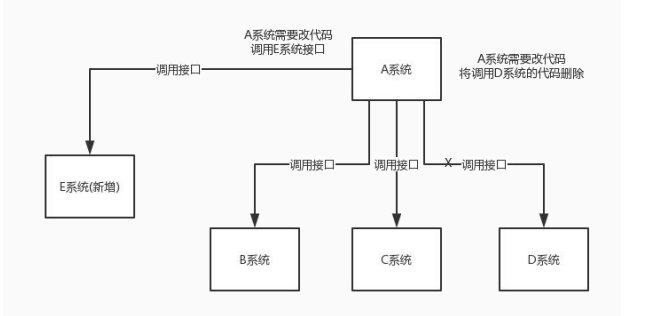
在这个场景中,A 系统跟其它各种乱七八糟的系统严重耦合,A 系统产生一条比较关键的数据,很多系统都
需要 A 系统将这个数据发送过来。A 系统要时时刻刻考虑 BCDE 四个系统如果挂了该咋办?要不要重发,
要不要把消息存起来?头发都白了啊!
如果使用 MQ,A 系统产生一条数据,发送到 MQ 里面去,哪个系统需要数据自己去 MQ 里面消费。如果新
系统需要数据,直接从 MQ 里消费即可;如果某个系统不需要这条数据了,就取消对 MQ 消息的消费即可。
这样下来,A 系统压根儿不需要去考虑要给谁发送数据,不需要维护这个代码,也不需要考虑人家是否调用
成功、失败超时等情况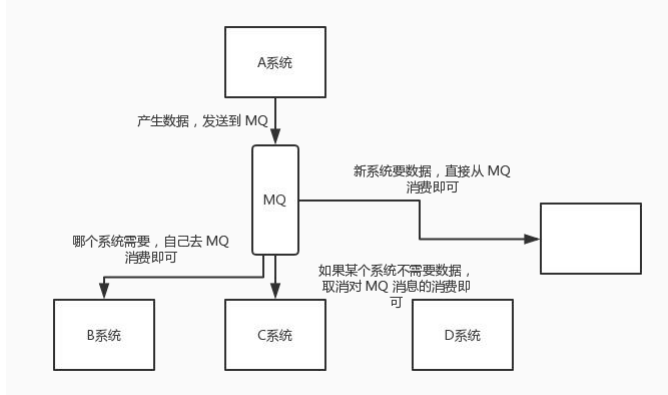
总结:通过一个 MQ,Pub/Sub 发布订阅消息这么一个模型,A 系统就跟其它系统彻底解耦了。
面试技巧:你需要去考虑一下你负责的系统中是否有类似的场景,就是一个系统或者一个模块,调用了多个
系统或者模块,互相之间的调用很复杂,维护起来很麻烦。但是其实这个调用是不需要直接同步调用接口的,
如果用 MQ 给它异步化解耦,也是可以的,你就需要去考虑在你的项目里,是不是可以运用这个 MQ 去进行
系统的解耦。在简历中体现出来这块东西,用 MQ 作解耦。
异步
削峰
消息队列有什么优缺点
优点上面已经说了,就是在特殊场景下有其对应的好处,解耦、异步、削峰。
缺点有以下几个:
系统可用性降低
系统引入的外部依赖越多,越容易挂掉。本来你就是 A 系统调用 BCD 三个系统的接口就好了,人 ABCD 四
个系统好好的,没啥问题,你偏加个 MQ 进来,万一 MQ 挂了咋整,MQ 一挂,整套系统崩溃的,你不就完
了?如何保证消息队列的高可用,可以点击这里查看。
系统复杂度提高
硬生生加个 MQ 进来,你怎么保证消息没有重复消费?怎么处理消息丢失的情况?怎么保证消息传递的顺
序性?头大头大,问题一大堆,痛苦不已。
一致性问题
A 系统处理完了直接返回成功了,人都以为你这个请求就成功了;但是问题是,要是 BCD 三个系统那里,
BD 两个系统写库成功了,结果 C 系统写库失败了,咋整?你这数据就不一致了。
所以消息队列实际是一种非常复杂的架构,你引入它有很多好处,但是也得针对它带来的坏处做各种额外的
技术方案和架构来规避掉,做好之后,你会发现,妈呀,系统复杂度提升了一个数量级,也许是复杂了 10 倍。
但是关键时刻,用,还是得用的。
Kafka、ActiveMQ、RabbitMQ、RocketMQ 有什么优缺点?
| 特性 | ActiveMQ | RabbitMQ | RocketMQ | Kafka |
|---|---|---|---|---|
| 单机吞吐量 | 万级,比 RocketMQ、 Kafka 低一 个数量级 | 同ActiveMQ | 10 万级,支撑高吞 吐 | 10 万级,高吞吐,一般配合 大数据类的系统来进行实时 数据计算、日志采集等场景 |
| 时效性 | ms级别 | 微妙级别RabbitMQ 的一大特 点,延迟 最低 | ms级别 | 延迟在 ms 级以内 |
| 可用性 | 高,基于主 从架构实现 高可用 | 同ActiveMQ | 非常高,分布式架构 | 非常高,分布式,一个数据多 个副本,少数机器宕机,不会 丢失数据,不会导致不可用 |
| 消息可靠性 | MQ 领域的功能极其完备 | 基于 erlang 开发,并 发能力很 强,性能 极好,延 时很低 | MQ 功能较为完善, 还是分布式的,扩展性好 |
功能较为简单,主要支持简单 的 MQ 功能在大数据领域的 实时计算以及日志采集被大 规模使用 |
1.应用场景方面
RabbitMQ:用于实时的,对可靠性要求较高的消息传递上。
kafka:用于处于活跃的流式数据,大数据量的数据处理上。
2.架构模型方面
producer,broker,consumer
RabbitMQ:以broker为中心,有消息的确认机制
kafka:以consumer为中心,无消息的确认机制
3.吞吐量方面
RabbitMQ:支持消息的可靠的传递,支持事务,不支持批量操作,基于存储的可靠性的要求存储可以采用内存或硬盘,吞吐量小。
kafka:内部采用消息的批量处理,数据的存储和获取是本地磁盘顺序批量操作,消息处理的效率高,吞吐量高。
4.集群负载均衡方面
RabbitMQ:本身不支持负载均衡,需要loadbalancer的支持
kafka:采用zookeeper对集群中的broker,consumer进行管理,可以注册topic到zookeeper上,通过zookeeper的协调机制,producer保存对应的topic的broker信息,可以随机或者轮询发送到broker上,producer可以基于语义指定分片,消息发送到broker的某个分片上

若有收获,就点个赞吧
0 人点赞
