- 阿里、京东、蚂蚁等大厂面试真题解析(1).pdf">阿里、京东、蚂蚁等大厂面试真题解析(1).pdf
- 1.Spring Bean作用域之间的区别
- 2.SpringMVC的执行过程
- 3.MyBatis中实体类中的属性与表中的字段名不一致,如何处理?
- 4.ArrayList的扩容机制
- 5.说⼀下ThreadLocal
- 6.Java中基本数据类型和包装类型的区别
- 7.mybatis的执行过程
- 8.Reentlock可重入锁的实现
- 9.接口调用的注意事项
- 10.开启事务后,一些sql已经执行。但是数据库不显示
11.索引失效场景">
11.索引失效场景- 12.什么情况下不推荐使用索引?
- 12.1.Mysql 数据库中,最常用的两种引擎是 innordb 和 myisam。InnoDB 是 Mysql 的默认存储引擎。
- 13.红黑树
- 14.RPC 与 Http的区别
- 15.浏览器输入一个请求发生了什么
阿里、京东、蚂蚁等大厂面试真题解析(1).pdf
https://juejin.cn/post/6844904096957218823
1.Spring Bean作用域之间的区别
可以通过**scope**属性指定**bean**的作用域,以决定**bean**是单实例还是多实例的。默认情况下,**Spring**只为每个在**ioc**的容器里声明的bean创建唯一的一个实例,整个**IOC**容器范围内都能共享该实例:所有后续的**getBean**()调用和bean引用都将返回这个唯一的**bean**实例。该作用域被称为**singleton**,它是所有**bean**的默认作用域
- singleton 在SpringIOC容器中仅存在一个bean实例,Bean以单例的方式存在
- prototype 每次调用getBean都会返回一个新的实例
- request 每次http请求都会创建一个新的bean,该作用域竟是仅仅适用于WebApplicationContext环境
session 同一个HTTPSession共享一个Bean,不同的HTTPSession使用不同的bean,该作用域仅适用于WebApplicationContext环境
2.SpringMVC的执行过程
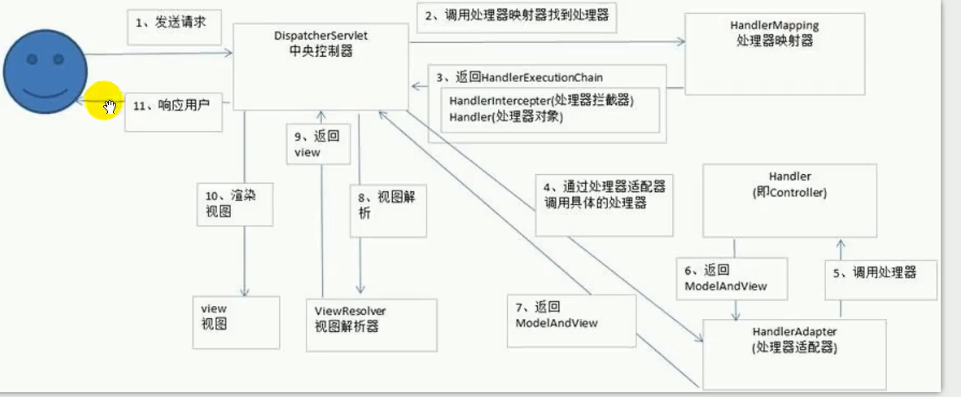
第一步:发起请求到前端控制器(DispatcherServlet)
第二步:DispatcherServlet请求HandlerMapping查找处理器Handler (可以根据xml配置、注解进行查找)
第三步:处理器映射器HandlerMapping向前端控制器返回Handler,HandlerMapping会把请求映射为HandlerExecutionChain对象(包含一个Handler处理器(页面控制器)对象,多个HandlerInterceptor拦截器对象)
第四步:DispatcherServlet调用处理器适配器HandlerAdapter去执行Handler
第五步:处理器适配器HandlerAdapter将会根据适配的结果去执行Handler
第六步:Handler执行完成给适配器返回ModelAndView
第七步:处理器适配器向前端控制器返回ModelAndView (ModelAndView是springmvc框架的一个底层对象,包括 Model和view)
第八步:前端控制器请求视图解析器去进行视图解析
第九步:视图解析器向前端控制器返回View
第十步:前端控制器进行视图渲染 (视图渲染将模型数据(在ModelAndView对象中)填充到request域)
第十一步:前端控制器向用户响应结果
1、前端控制器DispatcherServlet(不需要程序员开发) 作用接收请求,响应结果,相当于转发器,中央处理器。
有了DispatcherServlet减少了其它组件之间的耦合度。
2、处理器映射器HandlerMapping(不需要程序员开发) 作用:根据请求的url查找Handler
3、处理器适配器HandlerAdapter 作用:按照特定规则(HandlerAdapter要求的规则)去执行Handler
4、处理器Handler(需要程序员开发) 注意:编写Handler时按照HandlerAdapter的要求去做,这样适配器才可以去正确执行Handler
5、视图解析器View resolver(不需要程序员开发) 作用:进行视图解析,根据逻辑视图名解析成真正的视图(view)
6、视图View(需要程序员开发jsp) View是一个接口,实现类支持不同的View类型(jsp、freemarker、pdf…)3.MyBatis中实体类中的属性与表中的字段名不一致,如何处理?
- sql语句写别名
- 2.Mybatis的全局配置文件中开启驼峰命名规则
3.在Mapper映射文件中使用resultMap来自定义映射规则
4.ArrayList的扩容机制
ArrayList是List接口的实现类,它是支持根据需要而动态增长的数组。java中标准数组是定长的,在数组被创建之后,它们不能被加长或缩短。这就意味着在创建数组时需要知道数组的所需长度,但有时我们需要动态程序中获取数组长度。ArrayList就是为此而生的,但是它不是线程安全的,ArrayList按照插入的顺序来存放数据
①ArrayList扩容发生在add()方法调用的时候, 调用ensureCapacityInternal()来扩容的,通过方法calculateCapacity(elementData, minCapacity)获取需要扩容的长度:
- ②ensureExplicitCapacity方法可以判断是否需要扩容:
- ③ArrayList扩容的关键方法grow():获取到ArrayList中elementData数组的内存空间长度 扩容至原来的1.5倍
- ④调用Arrays.copyOf方法将elementData数组指向新的内存空间时newCapacity的连续空间
从此方法中我们可以清晰的看出其实ArrayList扩容的本质就是计算出新的扩容数组的size后实例化,并将原有数组内容复制到新数组中去。
5.说⼀下ThreadLocal
- ThreadLocal是Java中所提供的线程本地存储机制,可以利⽤该机制将数据缓存在某个线程内部,该线程可以在任意时刻、任意⽅法中获取缓存的数据
2. ThreadLocal底层是通过ThreadLocalMap来实现的,每个Thread对象(注意不是ThreadLocal对象)中都存在⼀个ThreadLocalMap,Map的key为ThreadLocal对象,Map的value为需要缓存的值
3. 如果在线程池中使⽤ThreadLocal会造成内存泄漏,因为当ThreadLocal对象使⽤完之后,应该要把设置的key,value,也就是Entry对象进⾏回收,但线程池中的线程不会回收,⽽线程对象是通过强引⽤指向ThreadLocalMap,ThreadLocalMap也是通过强引⽤指向Entry对象,线程不被回收,Entry对象也就不会被回收,从⽽出现内存泄漏,解决办法是,在使⽤了ThreadLocal对象之后,⼿动调⽤ThreadLocal的remove⽅法,⼿动清除Entry对象
4. ThreadLocal经典的应⽤场景就是连接管理(⼀个线程持有⼀个连接,该连接对象可以在不同的⽅法之间进⾏传递,线程之间不共享同⼀个连接)6.Java中基本数据类型和包装类型的区别
1、包装类是对象,拥有方法和字段,对象的调用都是通过引用对象的地址;基本类型不是
2、传递方式不同
包装类型是引用的传递;基本类型是值的传递
3、声明方式不同:
基本数据类型不需要new关键字;
包装类型需要new在堆内存中进行new来分配内存空间
4、存储位置不同:
基本数据类型直接将值保存在值栈中;
包装类型是把对象放在堆中,然后通过对象的引用来调用他们
5、初始值不同:
int的初始值为 0 、 boolean的初始值为false
包装类型的初始值为null
6、使用方式不同:
基本数据类型直接赋值使用就好;
包装类型是在集合如 coolectionMap时使用
7.mybatis的执行过程
mybatis底层还是采用原生jdbc来对数据库进行操作的,只是通过 SqlSessionFactory,SqlSession Executor,StatementHandler,ParameterHandler,ResultHandler和TypeHandler等几个处理器封装了这些过程。<br /> 简单来说,跟你直接用一个sqlUtil的实现是一样,只不过很多复杂的util优化的事情,提前有其他程序员做了。Mybatis是一个映射封装,他与你用util的区别就是,他将在代码块中的sql存在统一的xml文件也就是sqlmaper中。同时他将你执行sql的传参也就是执行变量进行了通配,然后映射到你的model中。<br />Mybatis大概的执行过程:<br />通过factory方法获取sqlsession----通过MapperProxy代理到dao--执行底层数据库操作,简单说就是**“据经过controller再经过service然后执行service中的相关方法并关联到mapper再执行mapper.xml中的sql语句=== ”**<br />我们以JDBC为例看看他们的区别:<br />JDBC:<br />(1) 加载JDBC驱动,建立并获取数据库连接 ,创建statement对象<br />(2) 设置SQL语句的传入参数<br />(3) 执行SQL语句并获得查询结果<br />(4) 对查询结果进行转换处理并将处理结果返回<br />(5) 释放资源<br />Mybatis:<br />**1:使用连接池,datasource,在驱动并连接的这个过程中优化并解耦**<br />JDBC第一步其实从效率角度来看是不合适的,因为无论什么数据库都不可能支撑随机和庞大的连接数,而且不可避免的存在连接浪费的情况,Mybatis就封装了这些优化的方法。<br />**2:统一sql存取到XML**<br />如果代码写在java块中,在团队合作中很可能出现两个交叉业务的代码使用类似的sql语句,而开发人员的工作本身没有交集,那就代表sql语句肯定是无法复用的。而且对sql的修改,就代表着对java文件的修改,需要重新编译和打包部署(比如常见的状态值更改,sql修改随着业务变化必然存在修改)。<br />mybatis将sql统一存取到xml中,就算存在业务交叉,但因为统一配置的缘故,sql在xml中一目了然,两个跨team的程序员可以看到对方的sql,来判断自己是否需要重用。并且使用xml配置可以减少代码编译。<br />还有就是在java中拼写长sql太恶心了。<br />**3:参数和结果集映射**<br />sql的方式需要传入参数,如果存在多条件“或类型”的查询(列表查询的查询条件允许空),那就代表你必须传参进行sql拼接,就算使用xml的方式也不行。要么每个业务独立配置xml中的sql,要么还是写入java代码中,或者以工具的方式进行自动拼接。<br />Mybatis使用映射的方式,方便model管理参数,同时以解析器的方式将参数动态拼接到sql(sqlmaper里那些标签),由于是model映射,连查询结果都可以统一映射,方便取出和运算。而且mybatis对查询结果集进行了缓存处理,使得重复查询进一步进行了优化。<br />**4:对多重复sql进行复用封装**<br />比如模板方法,将常用sql模块化,直接调用。比如通用的save和getID之类的,只有表名和字段名有变化。
8.Reentlock可重入锁的实现
ReentrantLock 默认采用非公平锁,除非在构造方法中传入参数 true 。
- 公平锁模型:
- 初始化时, state=0,表示无人抢占锁。这时候,A线程请求锁,占了锁,把state+1。
- 线程A取得了锁,把 state原子性+1,这时候state被改为1,A线程继续执行其他任务,然后来了线程B请求锁,线程B无法获取锁,生成节点进行排队。初始化的时候,会生成一个空的头节点,然后才是B线程节点,这时候,如果线程A又请求锁,是否需要排队?答案当然是否定的,否则就直接死锁了
- 非公平锁模型
但是它对于当前的事务窗口生效,如果想要设置全局的,需要加上global字段
SET GLOBAL TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
11.索引失效场景
1.(存在索引列的数据类型隐形转换)列类型是字符串,查询条件未加引号。
2.未使用该列作为查询条件
3.使用like时通配符%在前
4. 如果条件中有 OR,即使其中有部分条件带索引也不会使用。注 意:要想使用 or,又想让索引生效,只能将 or 条件中的每个列 都加上索引。
5. Where 子句中对索引列使用函数,用不上索引
6、Where 子句里对索引列上有数学运算,!=或者 <>(不等于),可能导致不走索引,也可能走 INDEX FAST FULL SCAN
7.未使用最左前缀法则,则不会使用索引
8、字段的 is not null 和 is null,当字段允许为 Null 的条件下:is not null 用不到索引,is null 可以用到索引。
9、范围后的索引会导致索引失效
12.什么情况下不推荐使用索引?
a) 数据唯一性差的字段不要使用索引
b) 频繁更新的字段不要使用索引
c) 字段不在 where 语句中出现时不要添加索引,如果 where 后含 IS NULL/IS NOT NULL/LIKE ‘%输入符%’等条件,不要使用索引
d) Where 子句里对索引使用不等于(<>),不建议使用索引
12.1.Mysql 数据库中,最常用的两种引擎是 innordb 和 myisam。InnoDB 是 Mysql 的默认存储引擎。
- 事务处理上方面
MyISAM 强调的是性能,查询的速度比 InnoDB 类型更快,但是不提供事务支持。
InnoDB 提供事务支持事务。 - 外键
MyISAM 不支持外键,InnoDB 支持外键。 - 锁
MyISAM 只支持表级锁,InnoDB 支持行级锁和表级锁,默认是行级锁,行锁大幅度提高了多用户并发操作的性能。innodb 比较适合于插入和更新操作比较多的情况,而 myisam 则适合用于频繁查询的情况。另外,InnoDB 表的行锁也不是绝对的,如果在执行一个 SQL 语句时,MySQL 不能确定要扫描的范围,InnoDB 表同样会锁全表,例如 update table set num=1 where name like “%aaa%”。 - 全文索引
MyISAM 支持全文索引, InnoDB 不支持全文索引。innodb 从 mysql5.6 版本开始提供对全文索引的支持。 - 表主键
MyISAM:允许没有主键的表存在。
InnoDB:如果没有设定主键,就会自动生成一个 6 字节的主键(用户不可见)。 - 表的具体行数
MyISAM:select count() from table,MyISAM 只要简单的读出保存好的行数。因为
MyISAM 内置了一个计数器,count()时它直接从计数器中读。
InnoDB:不保存表的具体行数,也就是说,执行 select count(*) from table 时,InnoDB要扫描一遍整个表来计算有多少行13.红黑树
红黑树是一种特定类型的二叉树。
红黑树是每个节点都带有颜色属性的二叉查找树,颜色或红色或黑色。在二叉查找树强制一般要求以外,对于任何有效的红黑树我们增加了如下的额外要求:
【1】性质1. 节点是红色或黑色。
【2】性质2. 根节点是黑色。
【3】性质3 每个叶节点是黑色的。
【4】性质4 每个红色节点的两个子节点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色节点)
【5】性质5. 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
14.RPC 与 Http的区别
常见的远程调用方式有以下几种:
- RPC:Remote Produce Call远程过程调用,类似的还有RMI(Remote Methods Invoke 远程方法调用,是JAVA中的概念,是JAVA十三大技术之一)。自定义数据格式,基于原生TCP通信,速度快,效率高。早期的webservice,现在热门的dubbo,都是RPC的典型
- RPC的框架:webservie(cxf)、dubbo
- RMI的框架:hessian
- Http:http其实是一种网络传输协议,基于TCP,规定了数据传输的格式。现在客户端浏览器与服务端通信基本都是采用Http协议。也可以用来进行远程服务调用。缺点是消息封装臃肿。现在热门的Rest风格,就可以通过http协议来实现。
- http的实现技术:HttpClient
- 相同点:底层通讯都是基于socket,都可以实现远程调用,都可以实现服务调用服务
- 不同点:
RPC:框架有:dubbo、cxf、(RMI远程方法调用)Hessian
当使用RPC框架实现服务间调用的时候,要求服务提供方和服务消费方 都必须使用统一的RPC框架,要么都dubbo,要么都cxf跨操作系统在同一编程语言内使用
优势:调用快、处理快http:框架有:httpClient
当使用http进行服务间调用的时候,无需关注服务提供方使用的编程语言,也无需关注服务消费方使用的编程语言,服务提供方只需要提供restful风格的接口,服务消费方,按照restful的原则,请求服务,即可跨系统跨编程语言的远程调用框架
既然两种方式都可以实现远程调用,我们该如何选择呢?
- 速度来看,RPC要比http更快,虽然底层都是TCP,但是http协议的信息往往比较臃肿
- 难度来看,RPC实现较为复杂,http相对比较简单
- 灵活性来看,http更胜一筹,因为它不关心实现细节,跨平台、跨语言。
因此,两者都有不同的使用场景:
- 如果对效率要求更高,并且开发过程使用统一的技术栈,那么用RPC还是不错的。
- 如果需要更加灵活,跨语言、跨平台,显然http更合适
那么我们该怎么选择呢?
微服务,更加强调的是独立、自治、灵活。而RPC方式的限制较多,因此微服务框架中,一般都会采用基于Http的Rest风格服务。[
](https://blog.csdn.net/fantacy10000/article/details/100855055)
15.浏览器输入一个请求发生了什么
首先是域名解析
浏览器检查是否有缓存(游览器缓存-系统缓存-路由器缓存)。如果有,直接显示。如果没有,跳到第三步。
在发送http请求前,需要域名解析(DNS解析),解析获取对应过的ip地址,DNS查询步骤,其中一步成功则直接跳到建立连接部分:
- 浏览器搜索自身的DNS缓存
- 搜索操作系统自身的DNS缓存
- 读取本地的HOST文件
-
建立TCP连接(TCP三次握手)
浏览器获得域名对应的IP地址后,建立TCP连接,TCP协议通过“三次握手”等方法保证传输的安全可靠:
发送方:SYN(synchronize),客户端发送SYN包(SYN=j)到服务器
- 接收方:SYN/ACK:在接收到客户端的syn包后,服务器也要发送一个SYN包给客户端,即SYN+ACK包,(确认信息传达)
- 发送方:ACK:客户端收到SYN+ACK包后,向服务器发送ACK包(确认接收方在线可收消息,握手结束)
-
发送HTTP请求
客户端向服务端发起HTTP请求(例如:POST/login.html http/1.1)。
客户端发送请求头信息,请求内容,最后会发送一空白行,标示客户端请求完毕服务器发送HTML响应
服务器做出应答,表示对于客户端请求的应答,例如:HTTP/1.1 200 OK。
服务器向客户端发送应答头信息。
服务器向客户端发送请求头信息后,也会发送一空白行,标示应答头信息发送完毕,接着就以Content-type要求的数据格式发送数据给客户端。TCP连接的释放
数据传输完毕后,双方都可释放连接。最开始的时候,客户端和服务器都是处于ESTABLISHED状态,然后客户端主动关闭,服务器被动关闭。
客户端:FIN:客户端进程发出连接释放报文,并且停止发送数据;
- 服务器:ACK:服务器收到连接释放报文,发出确认报文;
- 服务器:FIN+ACK:将最后的数据发送完毕后,就向客户端发送连接释放报文
- 客户端:ACK:收到服务器的连接释放报文后,发出确认报文(服务器只要收到了客户端发出的确认,立即进入CLOSED状态。同样,撤销TCB后,就结束了这次的TCP连接)
[
](https://blog.csdn.net/fantacy10000/article/details/100855055)

若有收获,就点个赞吧
0 人点赞
