ACID之Isolation(隔离性)
数据库的隔离级别主要分为4种:
- READ_UNCOMMITTED(读未提交)
- READ_COMMITTED(读提交)
- REPEATABLE_READ(可重复读)
- SERIALIZABLE(串行化)
读未提交:读取到别的事务未提交的数据,例如:事务A和事务B,在读未提交的隔离级别下,事务A可以读取到事务B还未提交的修改,那么如果后续事务B将修改回滚了,最终就会导致事务A读取到的错误的记录,即脏读
串行化:不能有多个事务并发执行,只能排队执行,只有当事务A执行完后事务B才可以进行操作,对于并发量较高的场景特别不适用
读提交:读取到别的事务已经提交的数据。例如:事务A可以读取到事务B已经提交了数记录,但是此时事务C对该记录也进行了修改,那么事务A第二次读的时候会发现记录与第一次读取时不一致,即不可重复读
可重复读:即一个事务对同一条记录的2次读取不会因为其他事务的修改而导致不一致。例如:事务A读取了记录1,此时事务B修改了该记录,当事务A再次读取到该记录时还是未被事务B修改的记录。但是当事务A执行的语句是删除用户表中年龄小于20岁的人员,而同时事务B又向db中插入了一条年龄为18的人员,那么虽然事务A最终的执行是成功的,但是看起来好像漏了一条数据,即幻读
对于隔离级别,在现实的场景中我们一般不会选用读未提交和串行化这2种隔离级别。mysql的默认隔离级别是可重复读,而oracle的隔离级别为读提交。那么数据库是如何实现并发情况下保证隔离级别特性的呢?这个解决方案主要是通过加锁或通过MVCC来保证
锁
数据库在并发执行时事务保证隔离性的一种解决方案是通过对记录进行加锁。即读的时候上S锁(共享锁),写的时候上X锁(排他锁)。当记录已经被上了S锁时,后续记录依旧可以读取(SS不冲突)。当记录已经被上了S锁时,后续记录不可以对其上X锁(SX冲突)。当记录已经被上了X锁时,后续事务无法对该记录进行读取或修改,必须等X锁释放后才能进行操作(XS冲突,XX冲突)
下面举个例子:
数据库中存在表T,其中有字段id和k,都为integer类型,id和k的初始值都为1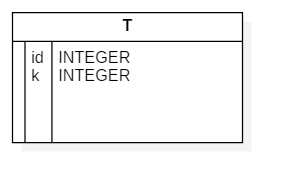
事务的执行顺序
| 序号 | 事务A | 事务B |
|---|---|---|
| 1 | start transaction | |
| 2 | select k from t where id = 1 | |
| 3 | update t set k = k + 1 where id = 1 | |
| 4 | commit | |
| 5 | select k from t where id = 1 |
读提交
在读提交的隔离级别下,事务B在序号2时读到的k的值为1,在序号4时读到的值为2。即事务B在2时读取id为1的记录,此时上了S锁,读取完后立即释放锁,在3时事务A对记录上X锁,执行完后释放。所以在5时事务B读取到的k的值为2
可重复读
在可重复读的隔离级别下,事务B在2时读到的值为1,在5时读到的值还是为1。因为事务B在2时读取记录并对记录上了S锁,此时读取完成后并不会立即释放锁(事务提交时统一释放),当事务A执行3时,发现由于记录已经被上了S锁,所以没法继续对记录上X锁,所以此时只能等待,事务B在4时读取到的值依旧是1
在使用锁控制读提交和可重复读的隔离级别时,主要区别就是锁的释放时间不同(1)读提交在语句执行完后立即释放锁(2)可重复读在语句执行完后不立即释放锁,而是等到整个事务执行完后再释放
锁的缺点:
- SS不是互斥的,那么对于读多写少的场景可能会导致一直无法加上X锁,从而无法更新记录(可通过引入锁升级和意向锁机制解决,此处不详述)。例如今日微博的场景,作者发布了一条微博,可是作者想对该微博进行修改,但由于读者较多,大家都在阅读该记录,不断对记录上S锁,而作者的更新请求需要等所有S锁释放,从而导致作者的更新一章失败
- 由于还是需要加锁,可能会导致死锁及效率低下的问题。加锁和解锁本身也是对资源的一种消耗,对于现如今的互联网行业来说这种频繁加锁解锁的操作是不合适的
MVCC
MVCC即多版本并发控制。即通过对记录维护多个版本从而不需要对记录进行上锁即可实现隔离级别的特性。
首先读取时创建视图,将事务分成3类:已提交事务、未提交事务(启动了还未提交)和未开始事务(系统已经创建过的事务ID最大值+1)。事务id保证了严格顺序递增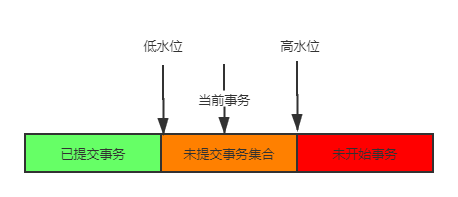
对于当前事务来说,已提交事务是可以被读取的,未开始事务记录是不可被读取的
在未提交事务中的记录也不可读取。例如,未提交事务集合中包含99,100(事务A),101(事务B),102(事务C)。
| 序号 | 事务A(100) | 事务B(101) | 事务C(102) |
|---|---|---|---|
| 1 | start transaction | ||
| 2 | start transaction | ||
| 3 | start transaction | ||
| 4 | select k from t where id = 1 | ||
| 5 | update t set k = k + 1 where id = 1 | ||
| 6 | commit | ||
| 7 | update t set k = k + 1 where id = 1 | ||
| 8 | select k from t where id = 1 | ||
| 9 | select k from t where id = 1 | ||
| 10 | commit | ||
| 11 | commit |

读提交
- 序号4的时候开启快照读(一致性读),此时事务B和C还没提交,所以读到的就是数据的初始版本k=1
- 序号8读取时k=3。此时事务C已经提交并且由于update语句是当前读,读到了事务C提交的k = 2这条记录,在序号8时,读取的记录最后一次修改又是自己,所以此时读到的k为3
序号9读取为快照读(一致性读),但由于是读提交级别下,所以不能复用序号4中的一致性视图,需要开启新的一致性视图,此时事务C的修改已经提交,所以k = 2
可重复读
序号4的时候开启快照读(一致性读),此时事务B和C还没执行,所以读到的就是数据的初始版本k=1
- 序号8读取时k=3。虽然事务C是的版本号是在当前活动的事务列表中的,但是由于update语句是当前读,读到了事务C提交的k = 2这条记录,在序号8时,读取的记录最后一次修改又是自己,所以此时读到的k为3
- 序号9读取时由于在序号4已经创建过一致性视图,所以依旧利用原有视图,读取到的结果k = 1
在读提交隔离级别下,每次select都会创建一个一致性视图,在可重复读隔离级别下,第一次select才会创建一个一致性视图,后续每次相同select都会复用之前的视图
无用的记录处理
MVCC通过维护了记录的多个版本从而保证了并发情况下的隔离级别特性,但是这样会造成有无用记录生成,例如:事务A将记录修改为k = 1,记录B将记录修改为k = 2,如果事务都成功提交后,对于后续记录来说k = 1这条记录就是无用的记录,那么mysql通过purge进行垃圾回收(此处不详述)

若有收获,就点个赞吧
0 人点赞
