存储结构
MySQL是以页为单位对记录进行存储和读取,即在读取某一条记录的时候其实会把条数据所在页的所有记录都加载到内存中。一个页包含FileHeader、PageHeader、UserRecord、Infimum、Supremum等信息。一个页大小为16k,下图只画出了UserRecord、Infimum和Supremem部分。每页当中的记录通过单向链表进行关联。页与页之间通过双向链表进行关联,物理上不一定连续。
当我们要查询记录时,如果没有结构的话我们只能进行全表扫描。例如:要找id=3的这条记录,我们并不知道记录在哪个页里,也不知道这个记录是否唯一,所以必须从第一个页开始遍历每个页里的每条记录看是否满足查询条件,直到最后一页,这就是全表扫描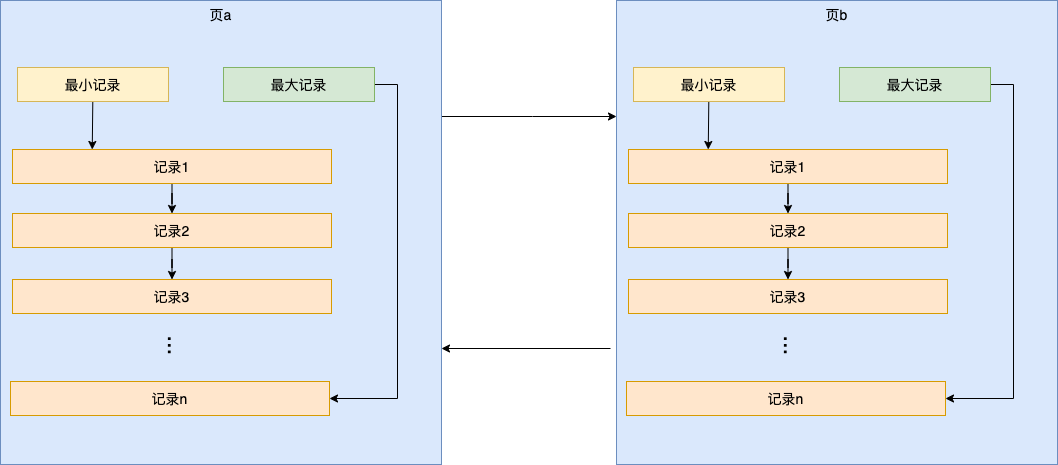
索引结构
索引也是由页为单位进行存储,其中包含record_type来区分这条记录是索引还是普通记录。next_record指向下一条记录。
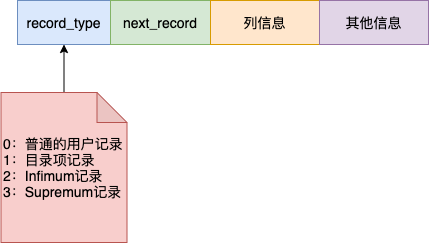
B+树索引
在InnoDB引擎中,索引的保存结构默认为B+树。其中包含了每个页的最小值和页号信息。每条数据的索引值都小于下一条数据的索引值,每一页上的最大值都小于等于下一页的最小值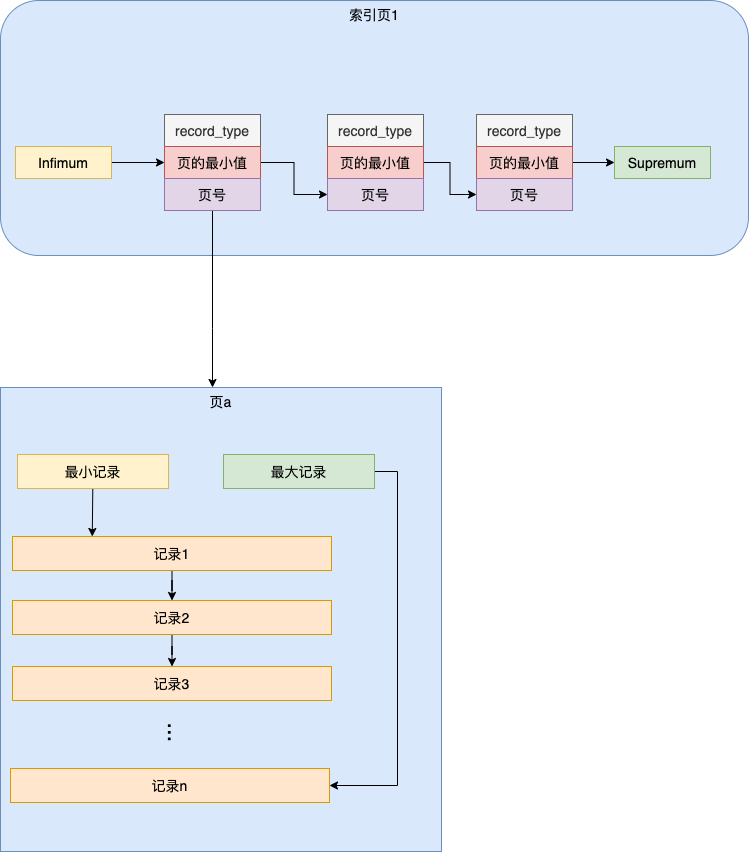
例如:有如下表信息,假设一个索引页最多存储3条记录,一个记录页最多存储3条记录
create table index_demo(c1 int,c2 int,c3 char(1),primary key (c1),index idx_c2(c2))
记录信息如下
| c1 | c2 | c3 |
|---|---|---|
| 1 | 4 | u |
| 3 | 9 | d |
| 4 | 4 | a |
| 5 | 3 | y |
| 9 | 3 | u |
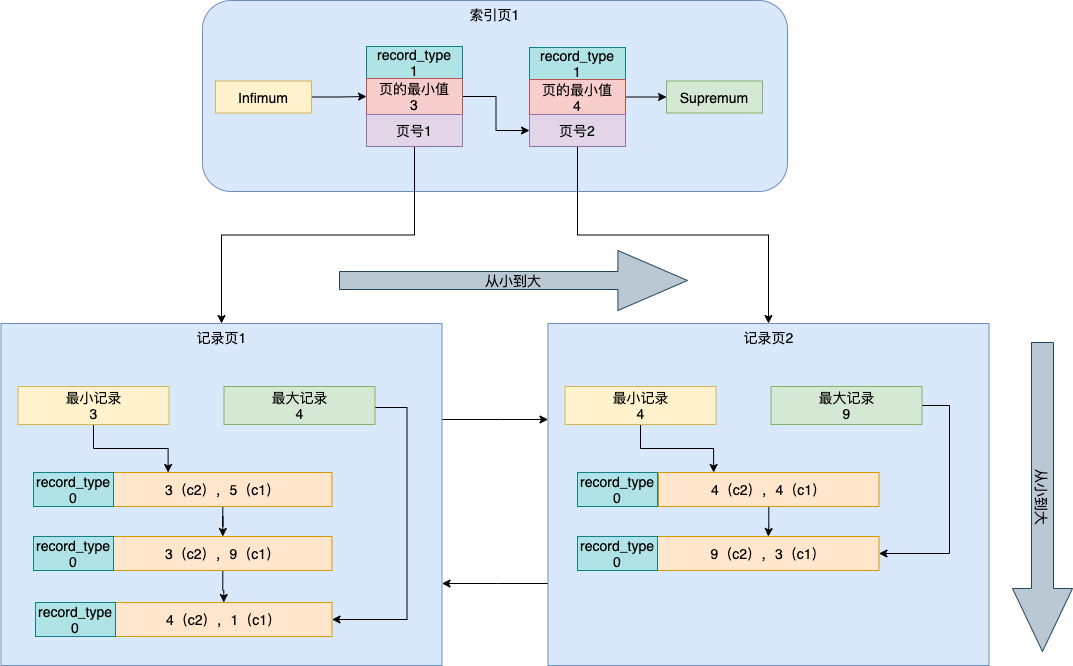
聚簇索引
聚簇索引是在叶子节点上存储整条数据,mysql的主键是聚簇索引。由于假设了一个记录页只能存储3条数据,所以下图中分为了2个记录页
例如上述案例中的c1列为聚簇索引。如果此时我们要查询c1=3的数据,就先从索引页1根据页的最小值查找,发现是在1-5中间(1 < 3 < 5),所以去找页号1对应的记录页1,此时页1为记录页(record_type = 0),在记录页1中通过二分查找的方式再查询c1=3的记录
索引裂变:当表中的记录越来越多,索引页会随之增加,上例中假设了一个数据页存储3条记录,一个索引页能存储3条记录,当我们插入第13条记录时索引就会裂变。其他索引的列表方式和聚簇索引一样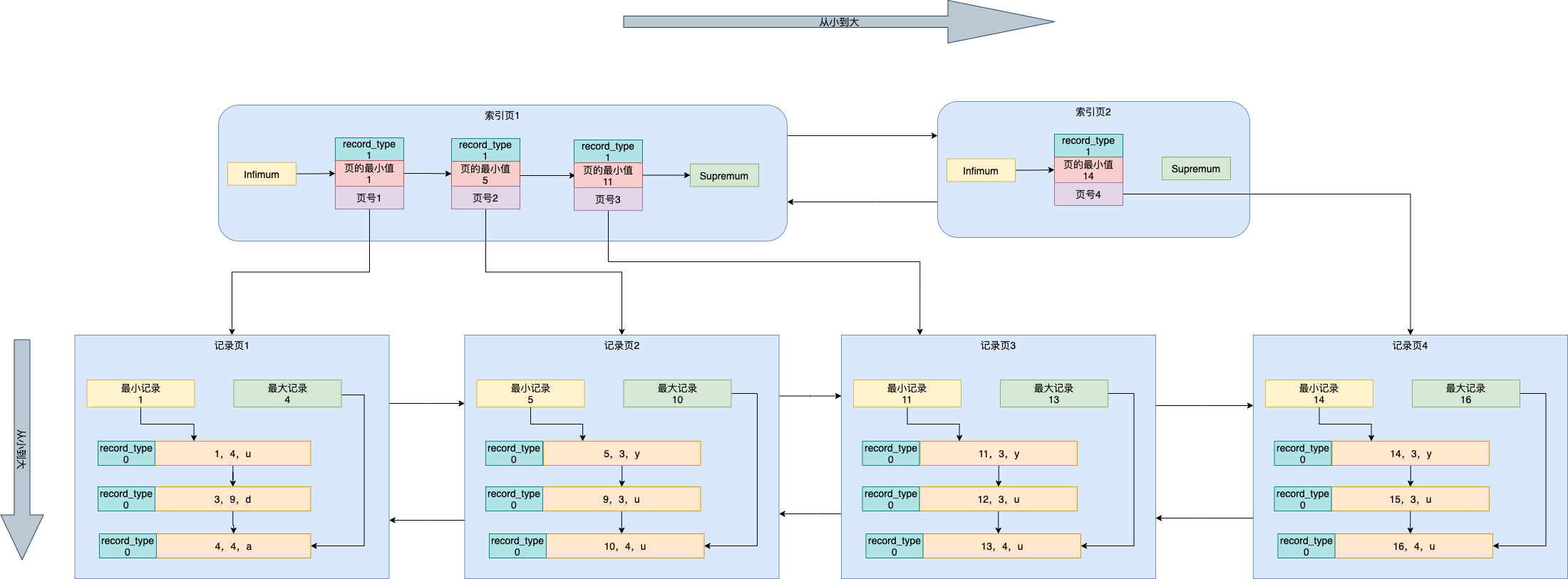
二级索引
二级索引即普通索引。在数据页中存储的是索引列信息及主键信息,先按索引列排序,再按主键排序。例如上例中的c2列为二级索引
例如要查找c2=4的记录
- 从索引页1中查找对应的记录页1
- 从记录页1中找到第一条c2=4的记录,一直向下遍历(还需要遍历后续索引页),所以从记录页1中找出c2=4,c1=1的记录,再从记录页2找到c2=4,c1=4的记录
- 再通过记录页中查找到的主键值从聚簇索引中查找需要的信息(回表)
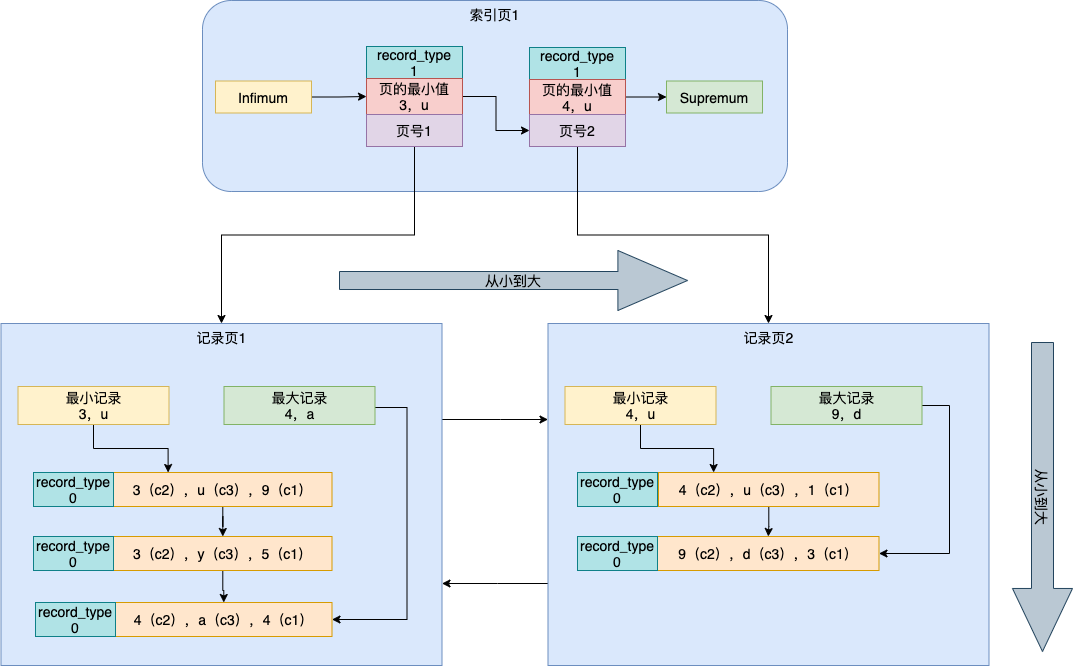
联合索引
联合索引即为多个列建立索引。例如:要对上例中的c2,c3列建立联合索引,即索引先按c2列排序,c2相同的再按c3列排序。
例如:要查找c2=3,c3=y的记录
- 先根据索引页1中判断出记录应该在页号1中(字符需转换为ascii码进行比较)
- 在记录页1中找到第一条满足条件的记录
- 从第一条满足条件的记录开始向后遍历(如果需要记录页2也需要遍历),直到第一条不满足条件的记录为止
- 根据c1(主键)列信息从聚簇索引中查找对应的记录(回表)
例如:要查找c2=4的记录
- 根据索引页1中判断c2=4的记录应该在页号1中(3,u < 4 < 4,u)
- 从索引页1中查找到第一条满足条件的记录(c2=4,c3=a,c1=4)
- 从第一条记录向后遍历,找到第一条不满足的记录为止(c2=4,c3=u,c1=1)
- 根据c1(主键)列信息从聚簇索引中查找对应的记录(回表)
覆盖索引
对于二级索引和联合索引并不是每一个查询都需要进行回表操作。例如:select c1 from index_demo where c2 = 4,我们只需要查出c1(主键)列的信息,那么索引中已经包含了c1列的信息,就不需要回表了

若有收获,就点个赞吧
0 人点赞
