运行时数据区
JVM的运行时数据区主要分为虚拟机栈、堆、本地方法栈、程序计数器和MetaSpace

虚拟机栈
用于存储局部变量。主要是基本数据类型和对象引用(地址)。每个方法都会开辟一个栈,栈随着方法的执行结束就出栈,线程私有
堆
MetaSpace
用于存储类信息、常量、静态变量、即时编译器编译后的代码等数据。线程公有
本地方法栈
程序计数器
类加载过程
例如如下代码
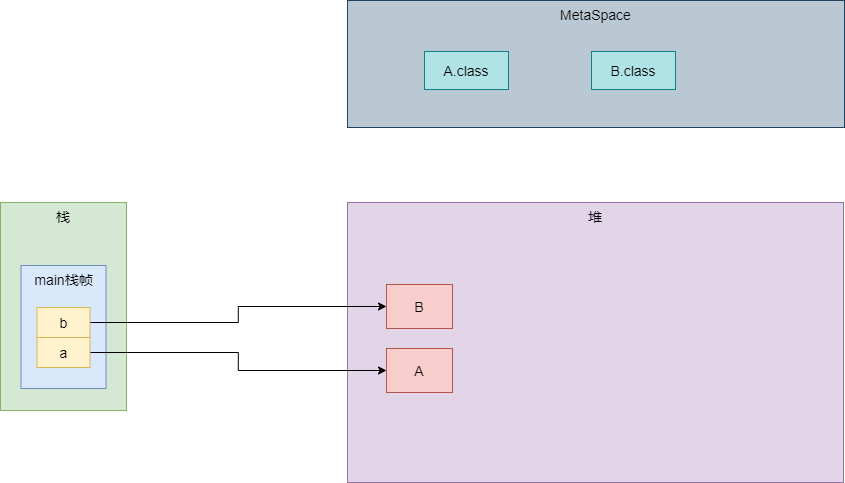
public class MainTest {public static void main(String[] args) {A a = new A();B b = new B();a.b = b;}}
public class B {}
public class A {
public static final String CON = "my_local_test";
public static StringBuffer sb = new StringBuffer("str");
public B b;
}
在main方法需要使用到A对象时,会先查看MetaSpace区中该类是否已经被加载过了,如果没有被加载过就需要先加载。加载过程分为验证、准备、解析和初始化
验证:验证class文件是否符合JVM规范
准备:给对象申请内存,给对象设置初始值(例如:0或null)
解析:将符号引用变为直接引用
初始化:如果父类没初始化会先初始化父类。主要是给变量赋值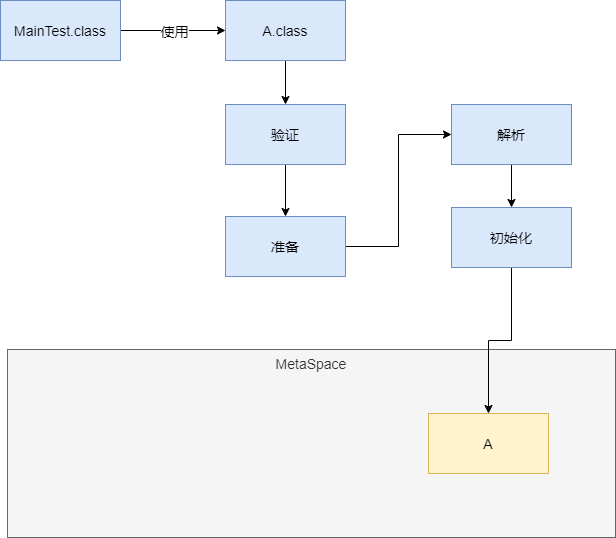
GC算法
标记-清除算法
标记-清除算法就是将可回收的对象直接进行回收。会造成碎片,可能导致无法分配对象
标记-整理算法
标记-整理算法首先将可回收对象进行回收,回收后将存活对象向一端移动,一般用于老年代回收
复制算法
- 复制算法将内存分为3块区域:
eden,s0,s1,默认比例为8:1:1 - 对象默认在
eden区进行创建 - 当第一次GC时将
eden区中存活的对象放入s0中 - 第二次时将
eden和s0中的存活对象放入s1中 - 第三次将
eden和s1中的存活对象放入s0中 - 当
s0和s1空间不够时由老年代进行过空间分配担保 - 该算法一般用于新生代回收

垃圾收集器
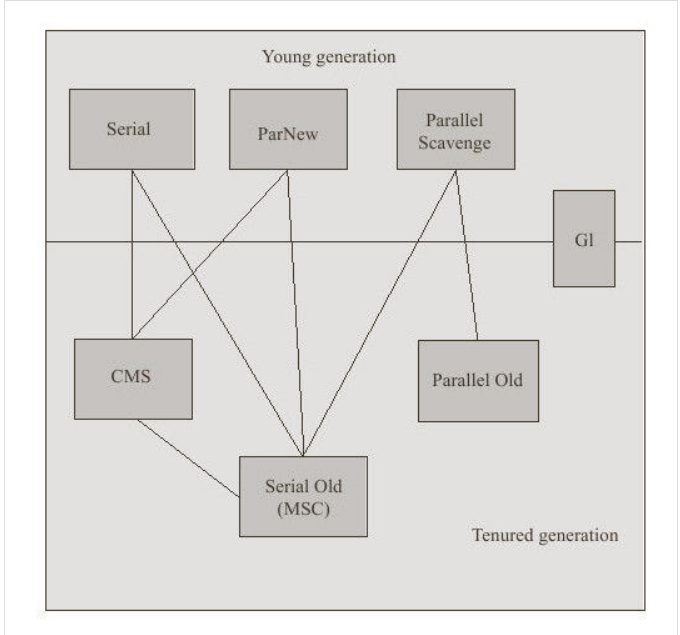
Serial收集器
- 单线程收集器,在进行垃圾收集时必须暂停所有其他工作线程,直到它收集结束
- 新生代:复制算法,暂停所有用户线程
-
Serial Old收集器
Serial收集器的老年代版本
- 老年代:标记-整理算法,暂停所有用户线程
-
ParNew收集器
Serial收集器的多线程版本
- 新生代:复制算法,多线程垃圾收集,暂停所有用户线程
-
Parallel Scavenge收集器
该收集器的目标是达到一个可控制的吞吐量,高吞吐量可以高效利用CPU时间,尽快完成任务,适合后台运算而不需要太多交互的任务。
- 吞吐量=运行用户代码时间/(运行用户代码时间 + 垃圾收集时间),虚拟机运行了100分钟,垃圾收集花费1分钟,吞吐量为99%
- 新生代:复制算法,多线程垃圾收集,暂停所有用户线程
- 使用参数:-XX:+UseParallelGC
- -XX:MaxGCPauseMillis:大于0的毫秒数,收集器尽可能保证回收花费的时间不超过设定值
- -XX:GCTimeRatio:大于0小于100的整数,就是垃圾收集时间占总时间的比率,相当于是吞吐量的倒数。如果把此参数设置为19,那允许的最大GC时间就占总时间的5%(即1/(1+19)),默认值为99,就是允许最大1%(即1/(1+99))的垃圾收集时间
- -XX:+UseAdaptiveSizePolicy:当这个参数打开之后,就不需要手工指定新生代的大小(-Xmn)、
- Eden与Survivor区的比例(-XX:SurvivorRatio)、晋升老年代对象年龄(-XX:
- PretenureSizeThreshold)等细节参数了,虚拟机会根据当前系统的运行情况收集性能监控信
- 息,动态调整这些参数以提供最合适的停顿时间或者最大的吞吐量,这种调节方式称为GC
-
Parallel Old收集器
Parallel Scavenge收集器的老年代版本
- 老年代:标记-整理算法
-
CMS收集器
该收集器是一种以获取最短回收停顿时间为目标的收集器
- 该收集器收集分为4个步骤:初始标记(Stop The World),并发标记,重新标记(Stop The World),并发清除
- 老年代:标记-清除算法
- 使用参数:-XX:+UseConcMarkSweepGC
- 缺点:对CPU资源敏感,无法处理浮动垃圾(并发清除时用户线程还在运行产生新的垃圾),基于标记-清除进行收集(产生内存碎片)
- -XX:+UseCMSCompactAtFullCollection:在顶不住需要FullGC时进行内存碎片合并(默认开启)
-XX:CMSFullGCsBeforeCompaction:设置执行多少次不压缩的Full GC后,跟着来一次带压缩的(默认值为0,表示每次进入FullGC时都进行碎片整理)
G1收集器
G1收集器是将堆划分为一个个大小相等的region,每个region有可能是eden、survivor、old或humongous。Humongous用于存放大于等于1.5个region的数据
G1收集器的收集过程分为:初始标记:仅仅标记一下GCRoots能直接关联到的对象,需STW
- 并发标记:对堆中的对象进行可达性分析,这阶段耗时较长
- 最终标记:修正并发标记阶段因用户程序运作而导致变动的那部分记录。
- 筛选回收:对各个resion的回收价值和成本排序,根据用户所期望的GC停顿时间来制定回收计划

跨代引用
只要使用了分代回收的机制,就会有跨带引用问题,例如:一个老年代对象引用了一个新生代对象,所以老年代对象也需要作为GC Root,但是扫描整个老年代对象的话效率就比较低下
为了解决这个问题,HotSpot虚拟机使用了RemeberedSet来记录老年代对象对新生代对象的引用。当进行MinorGC的时候只需要扫描这个RememberedSet中对新生代的引用即可

若有收获,就点个赞吧
0 人点赞
