背景
读写分离虽然可以提高数据库的读能力,对写能力也有一定的提升,但是在写压力较大的情况下读写分离也无法缓解系统压力和提高查询性能。例如:MySQL当单表数据量超过1000W时就会对表的读写性能造成较大影响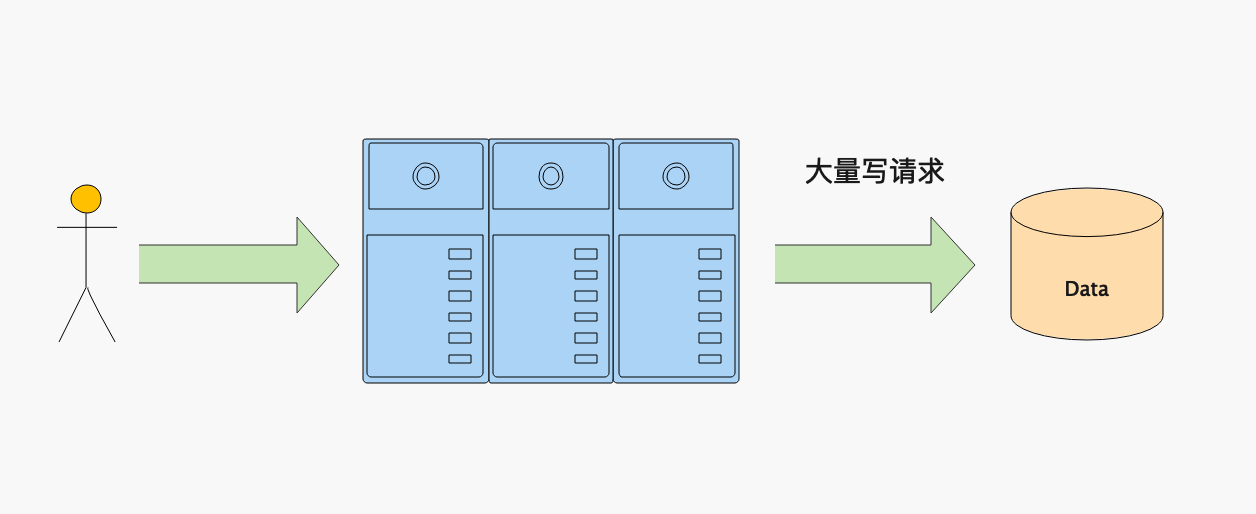
解决方案
基于数据库分区的思路,当出现单个表数量很大的情况,则需要采用水平分区的方式对数据进行拆分,即将同一个表中的不同数据拆分到不同的数据库中。例如:将订单表根据userId拆分为2个库中的2个表,可以通过将userId与2进行取模,如果结果为0则数据存入Data1中,如果结果为1则数据存入Data2中。如果是读请求,那么当userId与2取模结果为0,则从Data1库中读取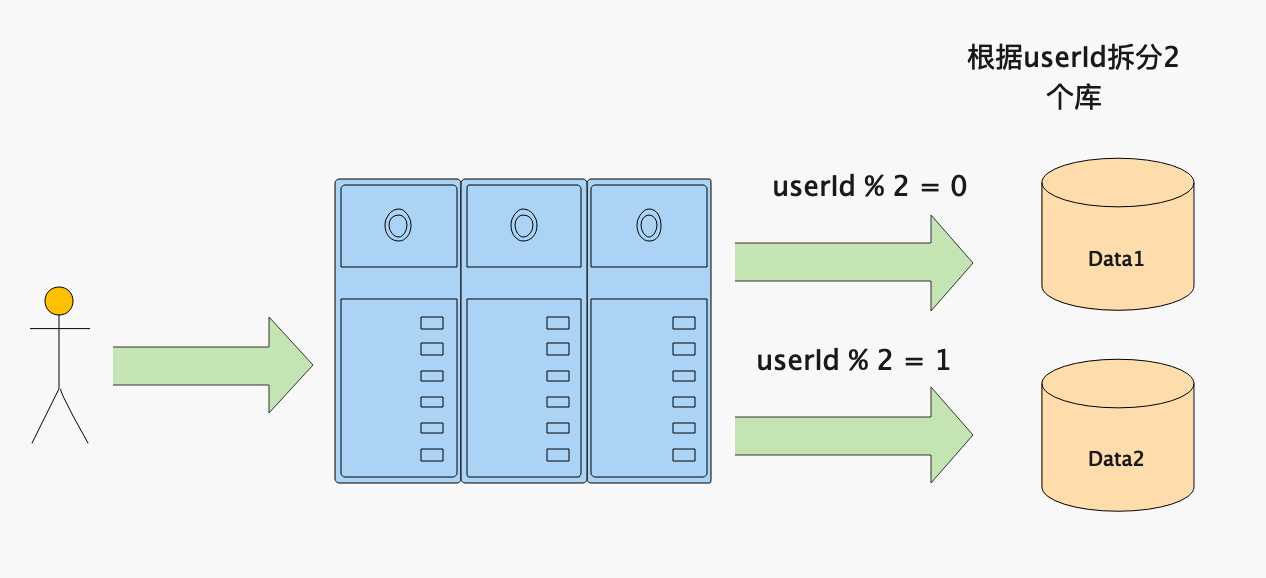
单key业务实践
索引表法
缓存映射法
基因法
一对多业务实践
mapping表法
基因法
多对多业务实践,数据冗余
服务同步冗余
线下异步冗余
应用场景
中间件
- TDDL:阿里出品,只开源了读写分离功能,未开源分库分表功能
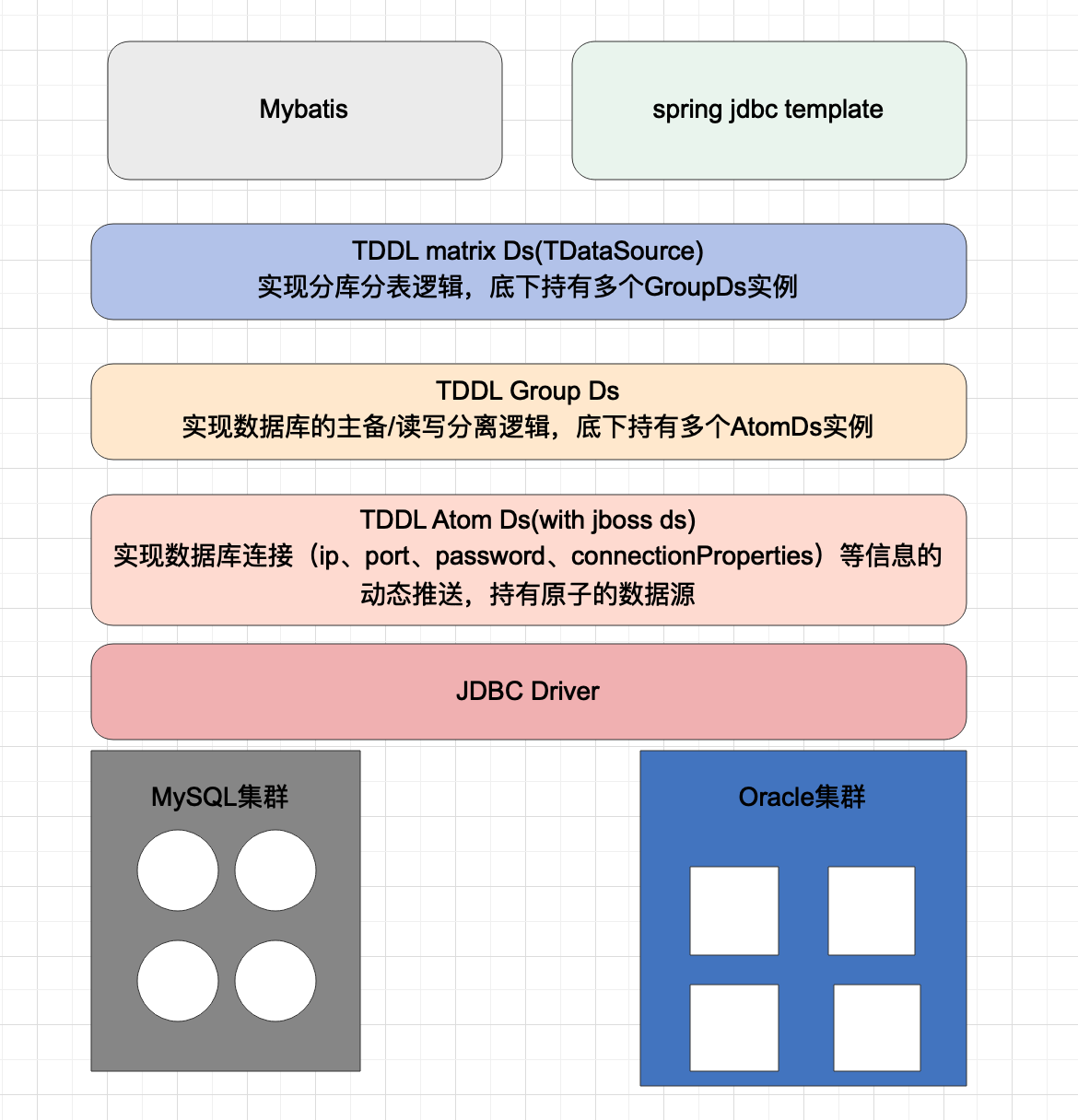
架构示意图
执行流程
- ShardingSephere:当当网开源,应该是目前应用最广的分库分表中间件。与其读写分离功能一样,通过拦截sql语句,并对其进行解析、计算等实现分库分表

- MyCat:基于代理的方式对sql语句进行解析,从而计算出数据在哪个库的哪个表中。基本不维护了

问题
例如:订单表包含:买家id、卖家id、商品id等字段,通过卖家id进行分库,即同一个卖家的订单在一个库中
分布式事务
以卖家id作为分区key,那么当一个买家提交购物车中的订单时,可能会拆分为多个订单,那么不同的商家订单会保存到不同的库当中就会产生分布式事务问题
这种情况可以选择进行循环单条保存,通过监控跟核对以及补偿解决数据一致性问题
分页查询
将订单表进行分库后,由于不带分区key的查询会扫描所有的库和表,性能非常差
这种情况可以将库中的所有订单信息同步到离线数据库中,进行统一查询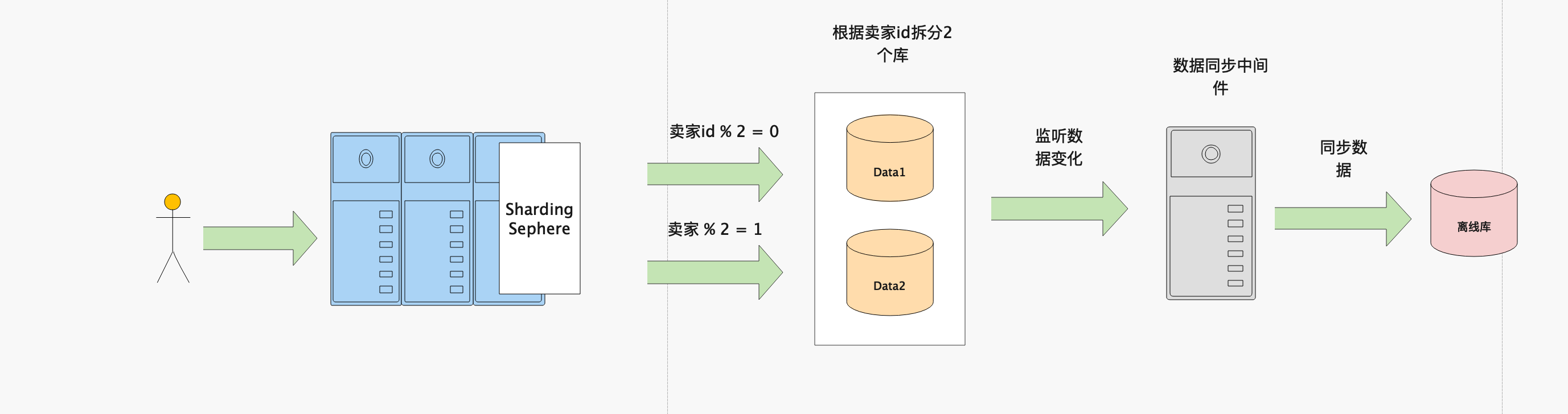
没有分区key查询
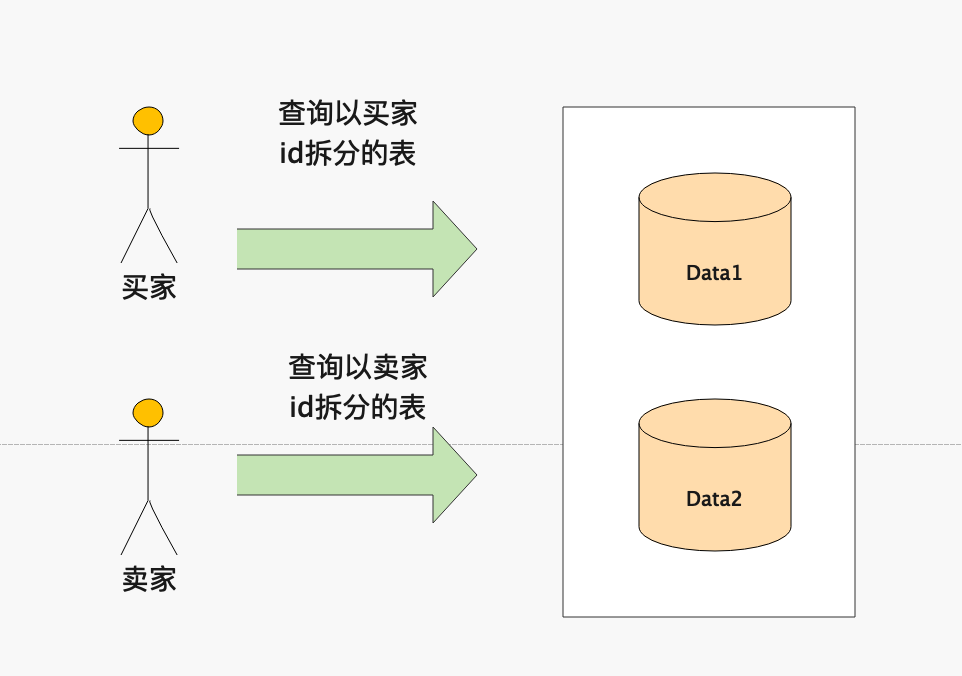
上述例子中通过卖家id进行了分库,那么买家需要查看自己买过哪些商品的时候由于没有卖家id,所以会导致查询全路由,性能较差。
对于这种情况可以使用异构索引表,即将数据以买家id作为分区key对数据进行同步,所有以买家id的查询走以买家id分库的表。但是这种方式会有一定的延迟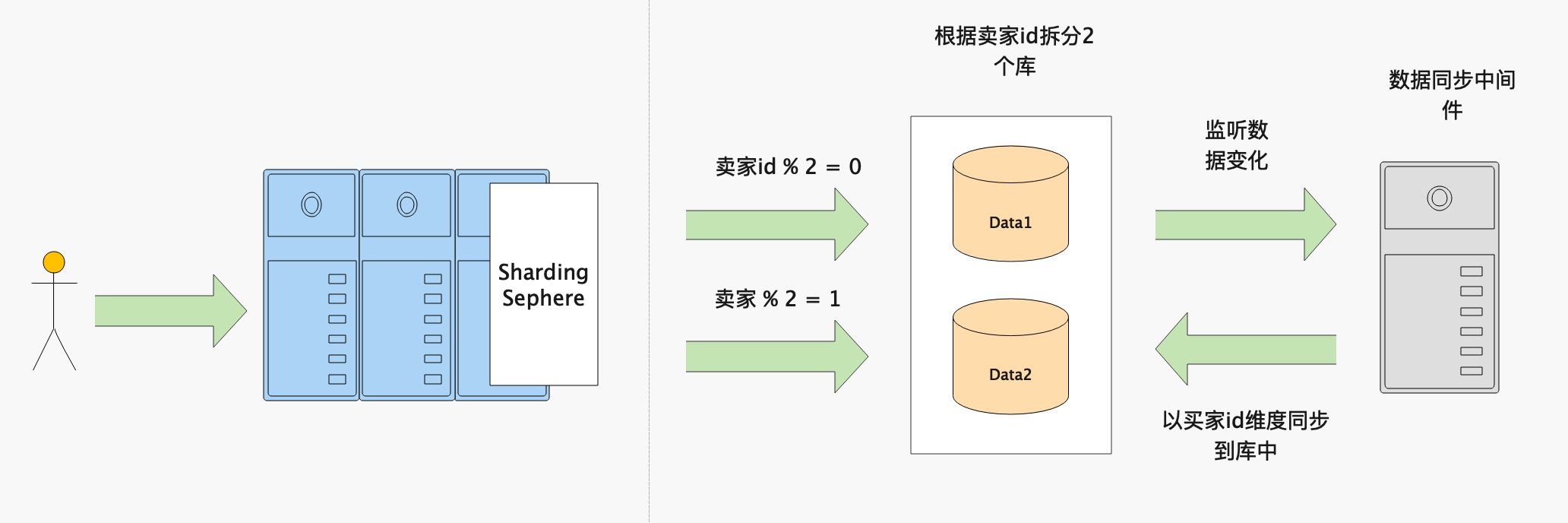
分数分布不均匀
分区key的选择需要使数据分布尽量均匀,否则还是会导致单库或单表的压力过大。例如:上述例子中使用卖家id进行分库,那么有的卖家销售量很大,有的卖家销售量很小,就会导致订单存储不均匀,会导致销售量大的卖家所在的库数据量大
主键冲突
对于分库分表的应用,由于数据散落到各个库表中,如果使用自增主键的话会导致主键冲突。例如:库1中的订单表和库2中的订单表生成了相同的主键。
- 使用单独的sequence生成器,主键不自动生成,由sequence主动生成后保存到分库表中
- 使用雪花算法生成id

若有收获,就点个赞吧
0 人点赞
