7.2.1 概念
切片(slice)是对数组一个连续片段的引用(该数组我们称之为相关数组,通常是匿名的),所以切片是一个引用类型(因此更类似于 C/C++ 中的数组类型,或者 Python 中的 list 类型)。这个片段可以是整个数组,或者是由起始和终止索引标识的一些项的子集。需要注意的是,终止索引标识的项不包括在切片内。切片提供了一个相关数组的动态窗口。
切片是可索引的,并且可以由 len() 函数获取长度。
给定项的切片索引可能比相关数组的相同元素的索引小。和数组不同的是,切片的长度可以在运行时修改,最小为 0 最大为相关数组的长度:切片是一个 长度可变的数组。
切片提供了计算容量的函数 cap() 可以测量切片最长可以达到多少:它等于切片从第一个元素开始,到相关数组末尾的元素个数。如果 s 是一个切片,cap(s) 就是从 s[0] 到数组末尾的数组长度。切片的长度永远不会超过它的容量,所以对于 切片 s 来说该不等式永远成立:0 <= len(s) <= cap(s)。
多个切片如果表示同一个数组的片段,它们可以共享数据;因此一个切片和相关数组的其他切片是共享存储的,相反,不同的数组总是代表不同的存储。数组实际上是切片的构建块。
优点 因为切片是引用,所以它们不需要使用额外的内存并且比使用数组更有效率,所以在 Go 代码中 切片比数组更常用。
声明切片的格式是: var identifier []type(不需要说明长度)。
一个切片在未初始化之前默认为 nil,长度为 0。
切片的初始化格式是:var slice1 []type = arr1[start:end]。
这表示 slice1 是由数组 arr1 从 start 索引到 end-1 索引之间的元素构成的子集(切分数组,start:end 被称为 slice 表达式)。所以 slice1[0] 就等于 arr1[start]。这可以在 arr1 被填充前就定义好。
如果某个人写:var slice1 []type = arr1[:] 那么 slice1 就等于完整的 arr1 数组(所以这种表示方式是 arr1[0:len(arr1)] 的一种缩写)。另外一种表述方式是:slice1 = &arr1。
arr1[2:] 和 arr1[2:len(arr1)] 相同,都包含了数组从第三个到最后的所有元素。
arr1[:3] 和 arr1[0:3] 相同,包含了从第一个到第三个元素(不包括第四个 / 不包含下标为三的元素)。
如果你想去掉 slice1 的最后一个元素,只要 slice1 = slice1[:len(slice1)-1]。
一个由数字 1、2、3 组成的切片可以这么生成:s := [3]int{1,2,3}[:] 甚至更简单的 s := []int{1,2,3}。
s2 := s[:] 是用切片组成的切片,拥有相同的元素,但是仍然指向相同的相关数组。
一个切片 s 可以这样扩展到它的大小上限:s = s[:cap(s)],如果再扩大的话就会导致运行时错误(参见第 7.7 节)。
对于每一个切片(包括 string),以下状态总是成立的:
s == s[:i] + s[i:] // i是一个整数且: 0 <= i <= len(s)len(s) <= cap(s)
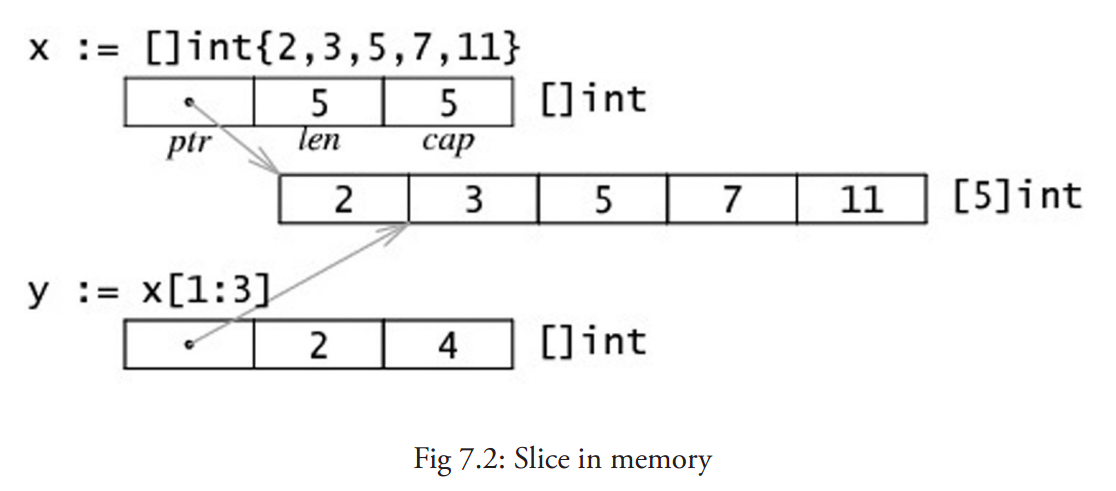
切片也可以用类似数组的方式初始化:var x = []int{2, 3, 5, 7, 11}。这样就创建了一个长度为 5 的数组并且创建了一个相关切片。
切片在内存中的组织方式实际上是一个有 3 个域的结构体:指向相关数组的指针,切片长度以及切片容量。下图给出了一个长度为 2,容量为 4 的切片 y。
y[0] = 3且y[1] = 5。- 切片
y[0:4]由 元素 3,5,7, 11 组成。
示例 7.7 array_slices.go
package mainimport "fmt"func main() {var arr1 [6]intvar slice1 []int = arr1[2:5] // item at index 5 not included!// load the array with integers: 0,1,2,3,4,5for i := 0; i < len(arr1); i++ {arr1[i] = i}// print the slicefor i := 0; i < len(slice1); i++ {fmt.Printf("Slice at %d is %d\n", i, slice1[i])}fmt.Printf("The length of arr1 is %d\n", len(arr1))fmt.Printf("The length of slice1 is %d\n", len(slice1))fmt.Printf("The capacity of slice1 is %d\n", cap(slice1))// grow the sliceslice1 = slice1[0:4]for i := 0; i < len(slice1); i++ {fmt.Printf("Slice at %d is %d\n", i, slice1[i])}fmt.Printf("The length of slice1 is %d\n", len(slice1))fmt.Printf("The capacity of slice1 is %d\n", cap(slice1))// grow the slice beyond capacity//slice1 = slice1[0:7 ] // panic: runtime error: slice bound out of range}
输出:
Slice at 0 is 2Slice at 1 is 3Slice at 2 is 4The length of arr1 is 6The length of slice1 is 3The capacity of slice1 is 4Slice at 0 is 2Slice at 1 is 3Slice at 2 is 4Slice at 3 is 5The length of slice1 is 4The capacity of slice1 is 4
如果 s2 是一个 slice,你可以将 s2 向后移动一位 s2 = s2[1:],但是末尾没有移动。切片只能向后移动,s2 = s2[-1:] 会导致编译错误。切片不能被重新分片以获取数组的前一个元素。
注意 绝对不要用指针指向 slice。切片本身已经是一个引用类型,所以它本身就是一个指针!!
问题 7.2: 给定切片 b:= []byte{'g', 'o', 'l', 'a', 'n', 'g'},那么 b[1:4]、b[:2]、b[2:] 和 b[:] 分别是什么?
7.2.2 将切片传递给函数
如果你有一个函数需要对数组做操作,你可能总是需要把参数声明为切片。当你调用该函数时,把数组分片,创建为一个 切片引用并传递给该函数。这里有一个计算数组元素和的方法:
func sum(a []int) int {s := 0for i := 0; i < len(a); i++ {s += a[i]}return s}func main() {var arr = [5]int{0, 1, 2, 3, 4}sum(arr[:])}
7.2.3 用 make () 创建一个切片
当相关数组还没有定义时,我们可以使用 make () 函数来创建一个切片 同时创建好相关数组:var slice1 []type = make([]type, len)。
也可以简写为 slice1 := make([]type, len),这里 len 是数组的长度并且也是 slice 的初始长度。
所以定义 s2 := make([]int, 10),那么 cap(s2) == len(s2) == 10。
make 接受 2 个参数:元素的类型以及切片的元素个数。
如果你想创建一个 slice1,它不占用整个数组,而只是占用以 len 为个数个项,那么只要:slice1 := make([]type, len, cap)。
make 的使用方式是:func make([]T, len, cap),其中 cap 是可选参数。
所以下面两种方法可以生成相同的切片:
make([]int, 50, 100)new([100]int)[0:50]
下图描述了使用 make 方法生成的切片的内存结构:
示例 7.8 make_slice.go
package mainimport "fmt"func main() {var slice1 []int = make([]int, 10)// load the array/slice:for i := 0; i < len(slice1); i++ {slice1[i] = 5 * i}// print the slice:for i := 0; i < len(slice1); i++ {fmt.Printf("Slice at %d is %d\n", i, slice1[i])}fmt.Printf("\nThe length of slice1 is %d\n", len(slice1))fmt.Printf("The capacity of slice1 is %d\n", cap(slice1))}
输出:
Slice at 0 is 0Slice at 1 is 5Slice at 2 is 10Slice at 3 is 15Slice at 4 is 20Slice at 5 is 25Slice at 6 is 30Slice at 7 is 35Slice at 8 is 40Slice at 9 is 45The length of slice1 is 10The capacity of slice1 is 10
因为字符串是纯粹不可变的字节数组,它们也可以被切分成 切片。
练习 7.4: fobinacci_funcarray.go: 为练习 7.3 写一个新的版本,主函数调用一个使用序列个数作为参数的函数,该函数返回一个大小为序列个数的 Fibonacci 切片。
7.2.4 new () 和 make () 的区别
看起来二者没有什么区别,都在堆上分配内存,但是它们的行为不同,适用于不同的类型。
- new (T) 为每个新的类型 T 分配一片内存,初始化为 0 并且返回类型为 T 的内存地址:这种方法 *返回一个指向类型为 T,值为 0 的地址的指针,它适用于值类型如数组和结构体(参见第 10 章);它相当于
&T{}。 - make(T) 返回一个类型为 T 的初始值,它只适用于 3 种内建的引用类型:切片、map 和 channel(参见第 8 章,第 13 章)。
换言之,new 函数分配内存,make 函数初始化;下图给出了区别:

在图 7.3 的第一幅图中:
var p *[]int = new([]int) // *p == nil; with len and cap 0p := new([]int)
在第二幅图中, p := make([]int, 0) ,切片 已经被初始化,但是指向一个空的数组。
以上两种方式实用性都不高。下面的方法:
var v []int = make([]int, 10, 50)
或者
v := make([]int, 10, 50)
这样分配一个有 50 个 int 值的数组,并且创建了一个长度为 10,容量为 50 的 切片 v,该 切片 指向数组的前 10 个元素。
问题 7.3 给定 s := make([]byte, 5),len (s) 和 cap (s) 分别是多少?s = s[2:4],len (s) 和 cap (s) 又分别是多少?
问题 7.4 假设 s1 := []byte{'p', 'o', 'e', 'm'} 且 s2 := s1[2:],s2 的值是多少?如果我们执行 s2[1] = 't',s1 和 s2 现在的值又分别是多少?
7.2.5 多维 切片
和数组一样,切片通常也是一维的,但是也可以由一维组合成高维。通过分片的分片(或者切片的数组),长度可以任意动态变化,所以 Go 语言的多维切片可以任意切分。而且,内层的切片必须单独分配(通过 make 函数)。
7.2.6 bytes 包
类型 []byte 的切片十分常见,Go 语言有一个 bytes 包专门用来解决这种类型的操作方法。
bytes 包和字符串包十分类似(参见第 4.7 节)。而且它还包含一个十分有用的类型 Buffer:
import "bytes"type Buffer struct {...}
这是一个长度可变的 bytes 的 buffer,提供 Read 和 Write 方法,因为读写长度未知的 bytes 最好使用 buffer。
Buffer 可以这样定义:var buffer bytes.Buffer。
或者使用 new 获得一个指针:var r *bytes.Buffer = new(bytes.Buffer)。
或者通过函数:func NewBuffer(buf []byte) *Buffer,创建一个 Buffer 对象并且用 buf 初始化好;NewBuffer 最好用在从 buf 读取的时候使用。
通过 buffer 串联字符串
类似于 Java 的 StringBuilder 类。
在下面的代码段中,我们创建一个 buffer,通过 buffer.WriteString(s) 方法将字符串 s 追加到后面,最后再通过 buffer.String() 方法转换为 string:
var buffer bytes.Bufferfor {if s, ok := getNextString(); ok { //method getNextString() not shown herebuffer.WriteString(s)} else {break}}fmt.Print(buffer.String(), "\n")
这种实现方式比使用 += 要更节省内存和 CPU,尤其是要串联的字符串数目特别多的时候。
练习 7.5 给定切片 sl,将一个 []byte 数组追加到 sl 后面。写一个函数 Append(slice, data []byte) []byte,该函数在 sl 不能存储更多数据的时候自动扩容。
练习 7.6 把一个缓存 buf 分片成两个 切片:第一个是前 n 个 bytes,后一个是剩余的,用一行代码实现。

若有收获,就点个赞吧
0 人点赞
