转自微信公众号:迪普观点
01 埋点系统概述
当我们在谈论大数据时,实际上我们所说的大数据是什么呢?我的理解是 在公司实际应用的大数据里,通常认为 大数据=业务数据+用户行为数据。
这篇文章重点描述用户行为数据的采集、加工和应用。用户行为数据的采集、加工和应用显然是一种较为复杂的系统工程,在这里将这一套系统工程简称为埋点系统。
在工作实践中,埋点系统作为各种业务的支撑性基础设施,我认为应该包含下图中的这些模块,才能最大化流量数据的价值: 我将在剩余篇幅中,对埋点系统的重点模块做介绍:
我将在剩余篇幅中,对埋点系统的重点模块做介绍:
02 采集SDK
用户行为数据采集指的是针对特定用户行为或者事件进行捕获、处理和发送的过程;
为了让采集过程规范,简化,通常会使用数据采集SDK,采集SDK可以自研,也可以采购。
数据采集 SDK 的功能,概括起来就三点:
- 通过埋点来采集数据
将采集到的数据传输到指定的服务器端
最大限度的保证数据的准确性和完整性
<br />常见的埋点方式:
代码埋点
全埋点(无埋点)
可视化全埋点(圈选)
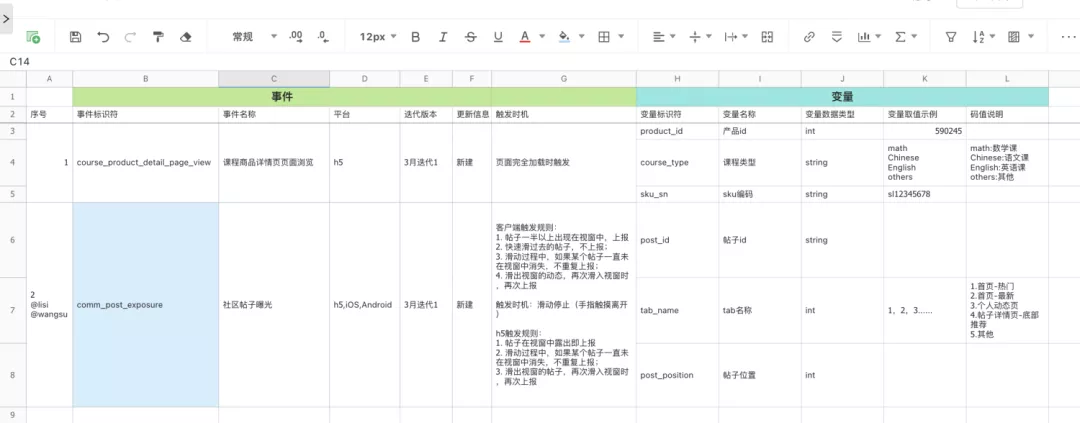
03 埋点文档设计
如何保证采集到的数据是可用的,易用的,除了从采集SDK中定义全局统一的数据结构,还需要在开发过程中尽可能做到规范,这就需要埋点文档:
一份好的埋点文档具备什么特征:
- 结构清晰,开发和测试的理解成本低,比如应该有全公司统一认知规范的事件和变量命名规则,见词知意;
- 可以方便的查看文档历史版本内容,老埋点做更新时可以迅速定位差异;
- 每个埋点有明确的负责人,清晰记录,谁开发的,谁测试的,谁为这个埋点的数据质量负责;
- 一个业务的所有埋点,尽可能集合存放,统一管理;
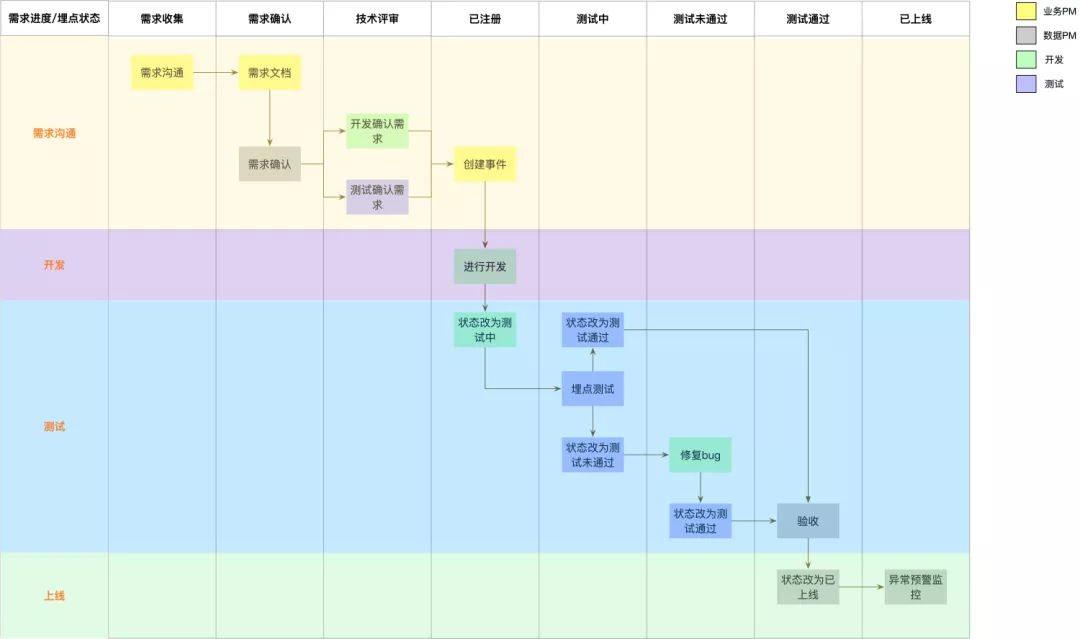
04 埋点的开发流程
埋点需求有需求小,需求多,上线链条长的特征,是一个长期的,涉及大量协作的的工作,如何兼顾开发效率和数据质量,是必须要思考的问题。
我的实践中,与开发团队磨合出了较为平衡的规范的协作流程。以下流程要点:
- 流程设计的目的是为了兼顾开发效率与数据质量,所以一定不能为了规范而规范,需要在长期与开发测试的磨合中,不断优化调整;
- 人工操作难免出错,能用工具自动化的部分,尽可能自动化;
- 在长期配合中,刻意培养所有参与方的各种共识,沉淀出知识背景,不需要每次从头开始讲各种注意事项;
示例的协作流程如下图:
05 埋点的数据质量保障
抛开数据质量谈大数据都是空谈,我从两个角度说明一下如何去做埋点数据质量保障:
上线前,生产过程规范,保证数据质量:**
- 埋点文档规范,比如同一个变量,在不同的埋点里命名应该一样(维度统一);
- 开发按规范埋;
- 测试按规范测;
上线后,有完善的监控预警策略:**
- 每个埋点有明确的负责人,为该埋点的全生命周期的数据质量做保障;
- 负责人可以根据自己对于业务的理解,制定异常提醒策略,并支持负责人订阅异常提醒;
- 从业务全局视角制定完善的埋点SLA,在出问题时,优先保障高优先级的数据;
END
埋点系列文章预告:
1. 详解埋点采集SDK的架构和原理;
2. 埋点系统-埋点测试
3. 埋点系统-埋点元数据管理系统
4. 埋点系统-服务端埋点的设计与应用
5. 埋点系统-全埋点原理
6. 埋点系统-标签管理
(Tag_Manager)


若有收获,就点个赞吧
0 人点赞
