原文: https://zhuanlan.zhihu.com/p/107836267
起源
1987年:Perl语言诞生了,它综合了其他的语言,用正则表达式作为基础,开创了一个新的流派,Perl流派。之后很多编程语言如:Python、Java、Ruby、.Net、PHP等等在设计正则式支持的时候都参考Perl正则表达式。
到这里我们也就知道为什么众多编程语言的正则表达式基本一样,因为他们都师从Perl。
注:Perl语言是一种擅长处理文本的语言,但因晦涩语法和古怪符号不利于理解和记忆导致很多开发者并不喜欢。
匹配原理
很多人觉得开车没必要了解车的构造原理,但是我们学编程的还真的需要了解原理。
因为了解原理,你才能调优,这往往也是初级工程师与中高级工程师之间的差别点之一!
1.执行过程
正则表达式的执行,是由正则表达引擎编译执行的,大致的执行流程猪哥也花了一个流程图给大家看看。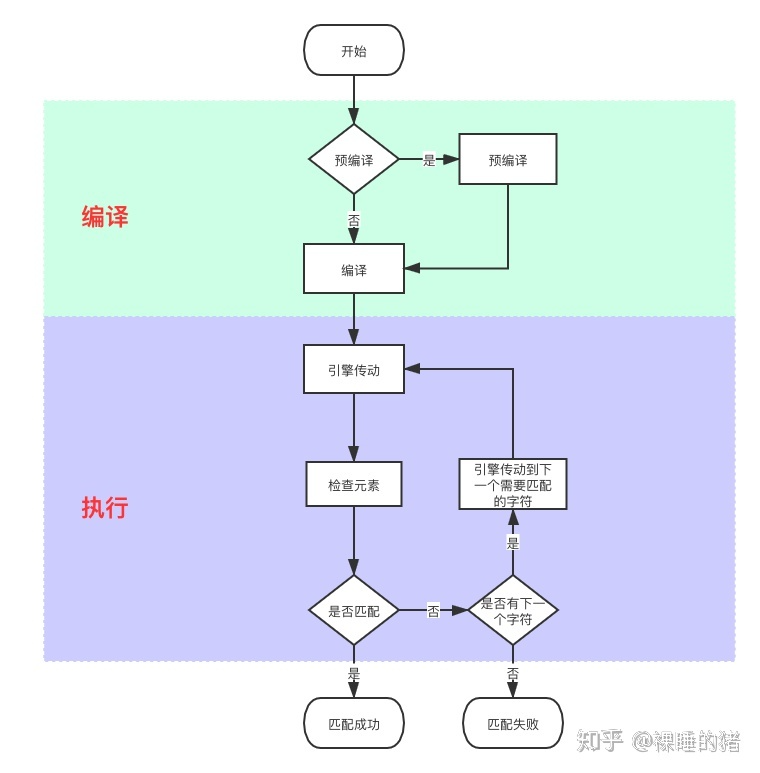
预编译(pre-use compile)
预编译执行时间比不预编译的执行时间少很多
2.引擎
正则引擎主要可以分为基本不同的两大类:
- DFA (Deterministic finite automaton) 确定型有穷自动机
- NFA (Non-deterministic finite automaton) 非确定型有穷自动机
ps:当然还有一种引擎为:POSIX NFA,这是根据NFA引擎出的规范版本,但因为使用较少所以我们这里也就不重点讲解。
这里需要和大家解释下何为确定型、有穷、自动机这几个名词:
- 确定型与非确定型:假设有一个字符串(text=abc)需要匹配,在没有编写正则表达式的前提下,就直接可以确定字符匹配顺序的就是确定型,不能确定字符匹配顺序的则为非确定型。
- 有穷:有穷即表示有限的意思,这里表示有限次数内能得到结果。
- 自动机:自动机便是自动完成,在我们设置好匹配规则后由引擎自动完成,不需要人为干预!
根据上面的解释我们可得知DFA引擎 和 NFA引擎 的区别就在于:在没有编写正则表达式的前提下,是否能确定字符执行顺序!
DFA引擎执行原理:
DFA引擎的一些特点:
- 文本主导:按照文本的顺序执行,这也就能说明为什么DFA引擎是确定型(deterministic)了,稳定!
- 记录当前有效的所有可能:我们看到当执行到(d|b)时,同时比较表达式中的d和b,所以会需要更多的内存。
- 每个字符只检查一次:这提高了执行效率,而且速度与正则表达式无关。
- 不能使用反向引用等功能:因为每个字符只检查一次,文本零宽度(位置)只记录当前比较值,所以不能使用反向引用、环视等一些功能!
NFA引擎执行原理:
NFA引擎的一些特点:
- 文表达式主导:按照表达式的一部分执行,如果不匹配换其他部分继续匹配,直到表达式匹配完成。
- 会记录某个位置:我们看到当执行到(d|b)时,NFA引擎会记录字符的位置(零宽度),然后选择其中一个先匹配。
- 单个字符可能检查多次:我们看到当执行到(d|b)时,比较d后发现不匹配,于是NFA引擎换表达式的另一个分支b,同时文本位置回退,重新匹配字符’b’。这也是NFA引擎是非确定型的原因,同时带来另一个问题效率可能没有DFA引擎高。
- 可实现反向引用等功能:因为具有回退这一步,所以可以很容易的实现反向引用、环视等一些功能!
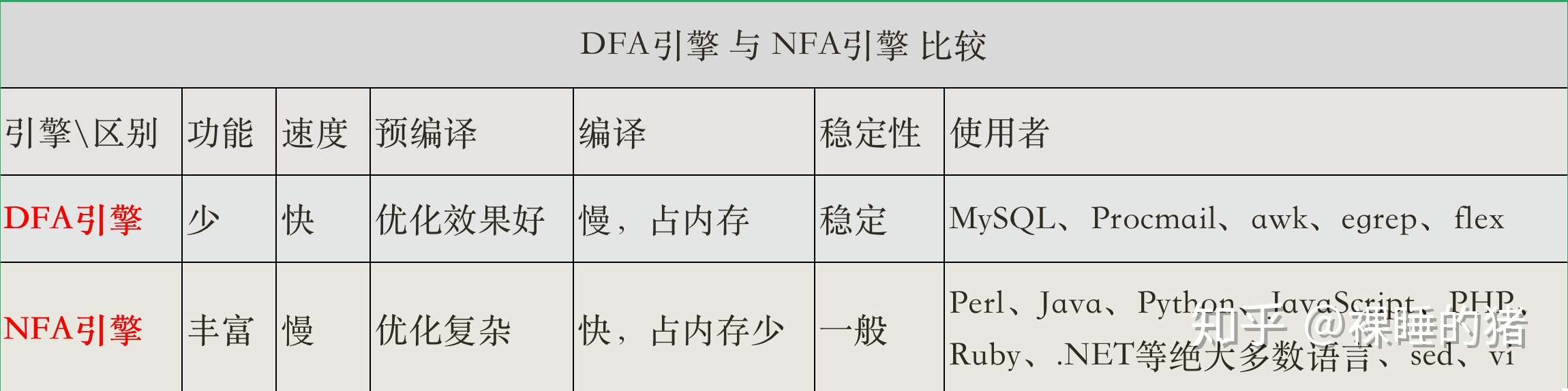
DFA(是电动机) 和NFA(汽油机) 都有很长的历史,不过,正如汽油机一样,NFA 的历史更长一些。也有些系统采用了混合引擎,它们会根据任务的不同选择合适的引擎(甚至对同一表达式中的不同部分采用不同的引擎,以求得功能与速度之间的最佳平衡)。 ——《精通正则表达式》
3.回溯
作为绝大多数编程语言都选择的引擎——NFA (非确定型有穷自动机) 引擎,我们当然要再详细了解一下它的精髓——回溯。

动图中,我们可以看到当某个正则分支匹配不成功之后,文本的位置需要回退,然后换另一个分支匹配,而回退这步专业术语就叫:回溯。
回溯的原理类似我们走迷宫时走过的路设置一个标志物,如果不对则原路返回,换另一条路。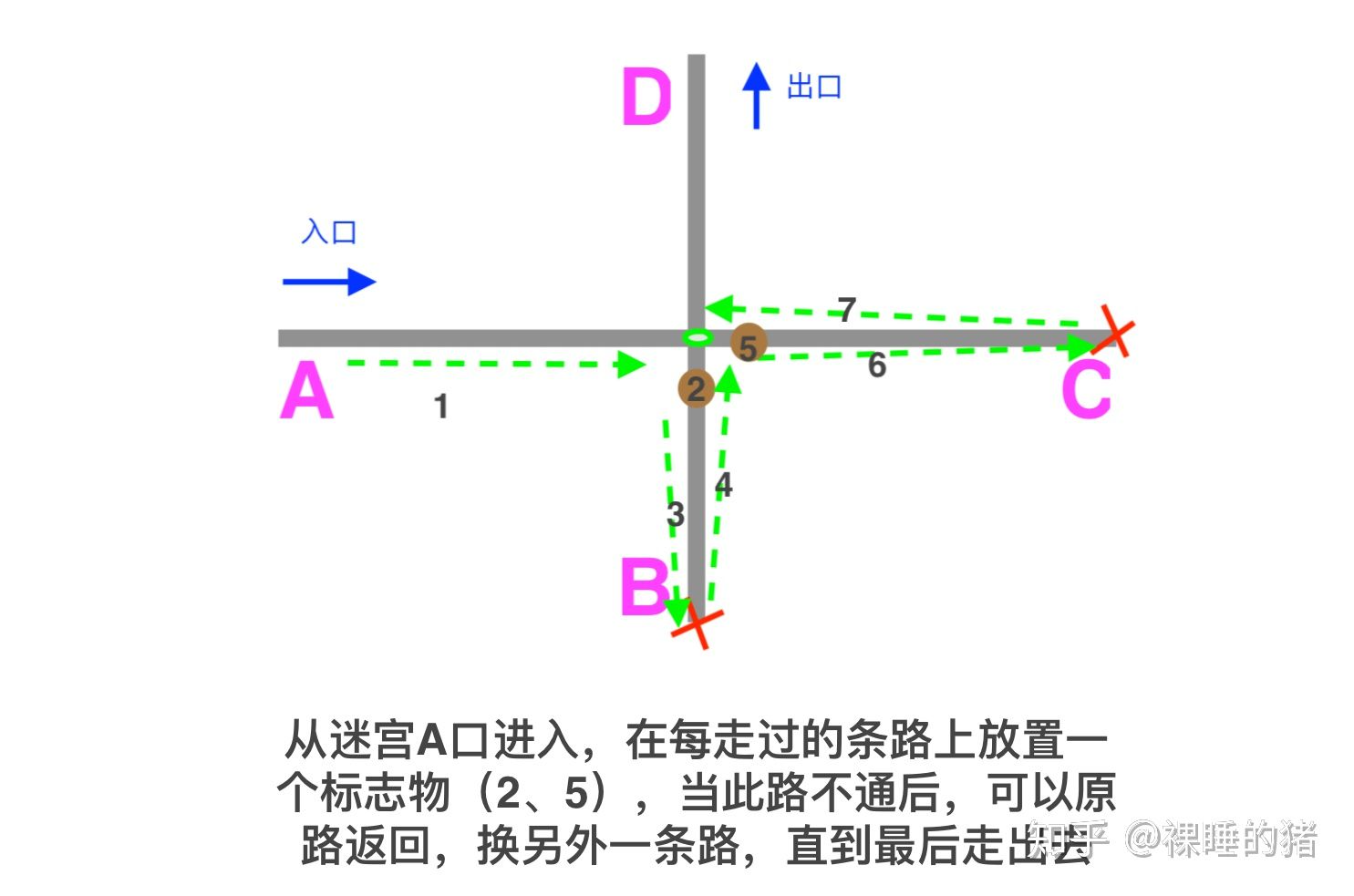
回溯机制不但需要重新计算正则表达式和文本的对应位置,也需要维护括号内的子表达式所匹配文本的状态(b匹配成功),保存到内存中以数字编号的组中,这就叫捕获组。
保存括号内的匹配结果之后,我们在后面的正则表达式中就可以使用,这就是我们所说的反向引用,在上面的案例中只有一个捕获,所以$1=b。
回溯陷阱:讲到回溯必须提到回溯陷阱,它导致的结果就是机器CPU使用率爆满(超100%),机器就卡死了。
举个例子:text=aaaaa,pattern=/^(a*)b$/,匹配过程大致是
- (a*):匹配到了文本中的aaaaa
- 匹配正则中的b,但是失败,因为(a*)已经把text都吃了
- 这时候引擎会要求(a*)吐出最后一个字符(a),但是无法匹配b
- 第二次是吐出倒数第二个字符(还是a),依然无法匹配
- 就这样引擎会要求(a*)逐个将吃进去的字符都吐出来
- 但是到最后都无法匹配b
这里的重点就在于 引擎会要求*匹配的东西一点一点吐回,我们假设如果文本长度为几万,那引擎就要回溯几万次,这对机器的CPU来说简直是灾难。
4.优化
编写巧妙的正则表达式不仅仅是一种技能,而且还是一种艺术。
上面我们了解到,绝大多数的编程语言都采用的是NFA引擎,而NFA引擎的特点是:功能强大、但有回溯机制所以效率慢。所以我们需要学习一些NFA引擎的一些优化技巧,以减少引擎回溯次数以及更直接的匹配到结果!
针对NFA引擎的可优化的点其实挺多的,为了方便大家记忆,猪哥也画幅结构图归纳一下,方便大家收藏细看。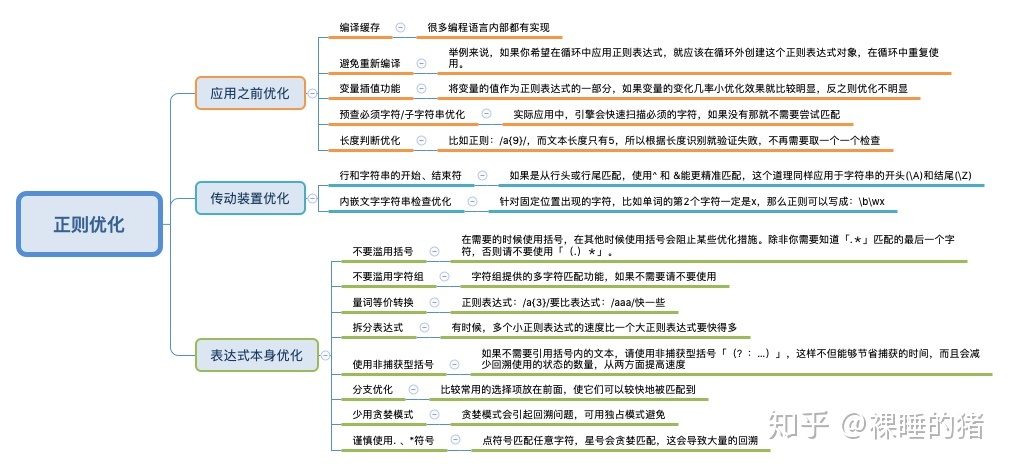

若有收获,就点个赞吧
0 人点赞
