1.什么是DOM(DOM很难用,要用别的东西来操作DOM,不用DOM自带的)
1.1.网页其实就是一棵树

1.2.JS如何操作这棵树(DOM的由来)
- 浏览器往 window 上加一个 document

- JS用document 操作网页—这就是 Document Object Model (文档对象模型)
2.获取元素的API
2.1.获取任意元素

如何选择用哪一种
- 工作中只用最后两种来获取
- 自己写demo图方便快捷可以用直接用id来获取(这种方法可能部分人根本不知道,可能会觉得你是野路子)
- 最后中间的三种 get 方法兼容 IE 才用
- 第一种:
window.idxxx或者直接idxxx
获取 id = “u1” 的标签
- 这种方法大部分时候可以用,只要 id 不跟全局属性冲突就行
- 比如下面这种 window.parent 就不行,这是一个全局属性,如果有id叫这个,就要用下面那种get方法

第二种:**document.getElementById('idxxx')**—获取 id

第三种:**document.getElementsByTagName('div')[0]—获取标签名**- 注意中间比第二种多了个 s ,意思就是获取全部的 div (此时是一个伪数组),然后用获取数组里的哪一项来获取对应的 div
- 后面的 0 不能省略
第四种:**document.getElementsByClassName('bottom')[0]—获取类名**- 意思就是获取所有 class = “bottom” 的类
- 第五种:
document.querySelector('#idxxx')—获取单个标签(不加其他的就只会获取找到的第一个)
这种写法括号里可以用 JS 里的语法(比较活灵活现)
- id加 # class加 . body、head加了引号就行
[x] 选择器写法
document.querySelector('div>span:nth-child(2)')找到所有第一个div里的第二个span元素(加All的话就是找到所有的div里的第二个span元素)第六种:
document.querySelectorAll('')—获取所有符合条件的标签[x] 一些常用操作示例如下:
document.querySelectorAll("p") //返回所有的p标签document.querySelectorAll("div.note, div.alert") //返回所有class为note和alert的div
[x] 可以在最后面加数组的下标选择—-
document.querySelectorAll('')[0]document.querySelectorAll('div>span:nth-child(2)')[1]//此时就不是选择所有的div里的第二个span元素,而是在[1]之前的获取到的NodeList这个类似数组的对象,找到其中的获取到的第二个元素
2.2.获取特定元素(叫元素或标签都可以)

获取 html 元素(并不是说获取到了html里的所有元素,注意区分)
document.documentElement
- 获取 head 元素
document.head
- 获取 body 元素
document.body
- 获取窗口
window
 每点一次屏幕都会打印一次 hi
每点一次屏幕都会打印一次 hi
- 获取所有元素
document.all第六个false值

- 可以区分是否是IE浏览器,但是也可以直接使用
-
2.3.元素的六层原型链(我们获取到的元素到底是什么呢)

第一层:
div.__proto__===HTMLDivElement.prototype(用原型公式就知道了)
HTML里div元素的共有属性
浏览器上显示的是错的,如下图
- 第二层:
HTMLElement.prototype—所有HTML元素的共有属性
同上,浏览器都没有加后面的 .prototype
- 第三层:
Element.prototype—所有HTML、XML等元素的共有属性 - 第四层:
Node.prototype—所有节点的共有属性(节点主要就是包括元素和文本) - 节点类型详见 MDN

[x]
xxx.nodeType可以查看节点类型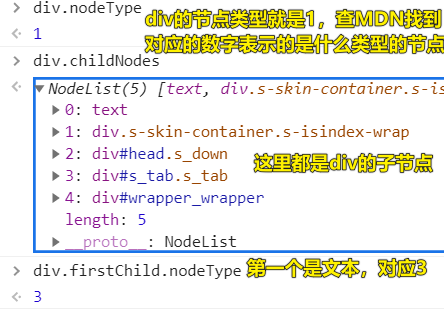
第五层:
EventTarget.prototype—就三个

第六层(最后一层):
Object.prototype—根对象(再往下就没有了,null)div完整的原型链如下:
3.节点的增删改查
3.1.增
3.1.1.创建一个标签节点
let div1 = document.createElement('div') //括号里是不同的标签document.createElement('style')document.createElement('script')document.createElement('li')
3.1.2.创建一个文本节点
let text1 = document.createTextNode('你好') //括号里是不同的字符串
3.1.3.标签里面插入文本
div1.appendChild(text1)div.innerText='你好' //div.textContent='你好'
3.1.4.插入到页面中(上面的做法在页面是看不见的,要插入到页面才能看得见)
document.body.appendChild(div1)document.head.appendChild(div1) //注意head里的是看不见的

插入页面之后,再加入样式就可以看的到了




3.1.5.关于appendChild


3.2.删
两种删除方法

代码如下:div1.parentNode.removeChild(div1) //找到该节点的爸爸,然后删除里面的该节点div1.remove() //新方法,IE不兼容,简单快捷
注:当把一个node移出页面(DOM树)之后,还可以再回到页面中(移出了,该node还在内存里,还可以再把它调用出来)
如下图(删除之后再添加还是可以的):
3.3.改
3.3.1.写标准属性
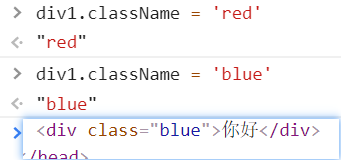
改class
div1.className = 'red'div1.className += ' blue' //或者直接 div1.className = 'red blue' 覆盖前面的div1.classList.add('gg')//前面已经有了red和blue,这种方法再加red和blue不会改变什么,加不同的才会改变
className有一个bug,后面的会覆盖前面的,要不然写+=要不然直接把所有的class都加上
改style
div1.style = 'width: 100px; color: blue;'//一般来说不要用这种,会直接覆盖之前的style;在某种意义上来说,这个也算是可以直接添加stylediv1.style.width = '200px;'//只修改width
[x] 大小写问题 比如背景色为 background-color 中间有一个中划线,需要写成下面的形式
[ ] 不然会被JS理解成前面的东西减去后面的
div1.style.backgroundColor = 'black' //同上面改部分style形式,但是中划线后面的第一个字母大写div1.style['background-color'] = 'white' //按照JS里的写法就写成这样的,比较麻烦
改 data-* 属性
div1.setAttribute("data-x","test") //会在div1里面添加一个名为 data-x 值为 test 的属性div1.getAttribute("data-x") //获取data-xdiv1.dataset.x = "gg" //.data-x也可以获取,然后直接修改就可以了
3.3.2.读标准属性
div1.stylediv1.id //这是正常的,直接 标签名.属性名
class
div1.classNamediv1.classList //返回数组形式div1.getAttribute('class') //获取class
三种不同形式的结果如下:

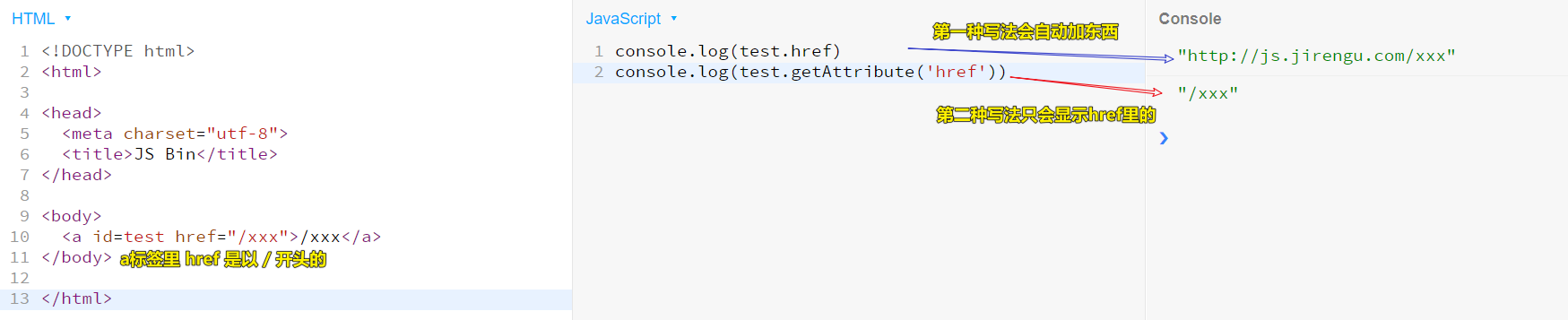
a标签
a.href //有可能浏览器会自动加工一下(把前面的域名补全了)a.getAttribute('href') //获取原本的href
3.3.3.改事件处理函数

[x] div和event都是浏览器在用户点击div的时候用call传进来的
-
test.onclick.call(test,event)fn 代指这个函数 xxx.onclick




3.3.4.改内容(即改子代)—JSBin
改文本内容(两者都可使用,几乎没区别)
div.innerText='xxx'div.textContent='xxx' //前面的div不是说是该标签是个div标签,而是说该标签的id为div,如果没有id会直接报错
改 HTML 内容
div.innerHTML='<strong>重要内容</strong>'
[x] 注意这里的 HTML 均为大写
- 虽然好用,但是里面内容不要太多,最大容量2W字符左右,太多会导致浏览器卡顿
- 里面可以添加多层任意标签内容,不仅仅是只能用一个标签
改标签
div.innerHTML='' //先清空div.appendChild(div2)//再添加,div2是一个节点
上面三个都是改儿子,那么能不能改爸爸呢
newParent.appendChild(div) //直接这样就从原来的地方消失了,到了新的地方
[x] newParent 代指新爸爸的 id
-
3.4.查
查爸爸;查爷爷
//查爸爸node.parentNodenode.parentElement//查爷爷(调用两次node)node.parentNode.parentNode
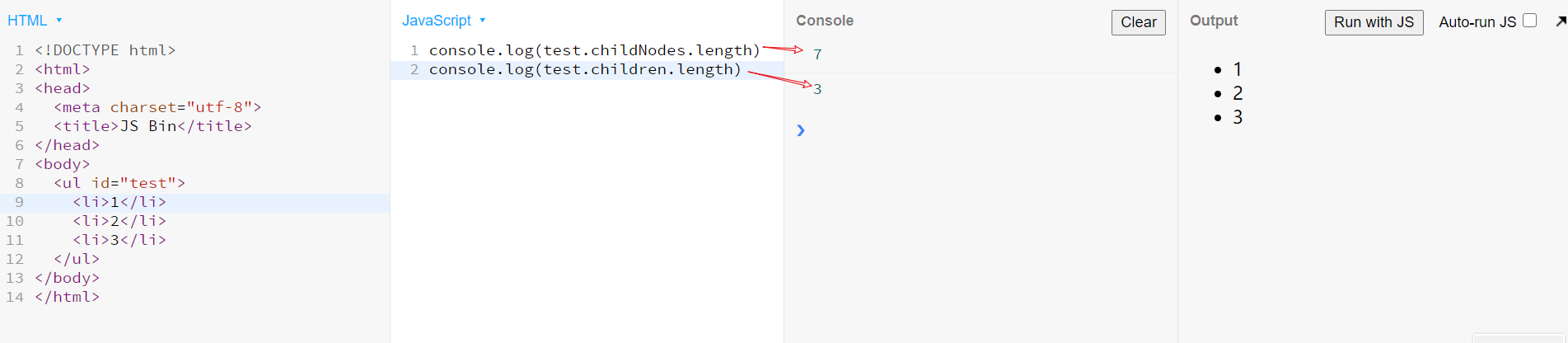
查子代—JSBin
node.childNodesnode.children //优先使用这种
[x]
node.childNodes.length打出来有问题。它把每一块空的地方合并成一个空格,也算是一个长度了- 所以优先使用
node.children

- 改变子代时,两种方法都会实时更新
[ ] 但是如果是打印
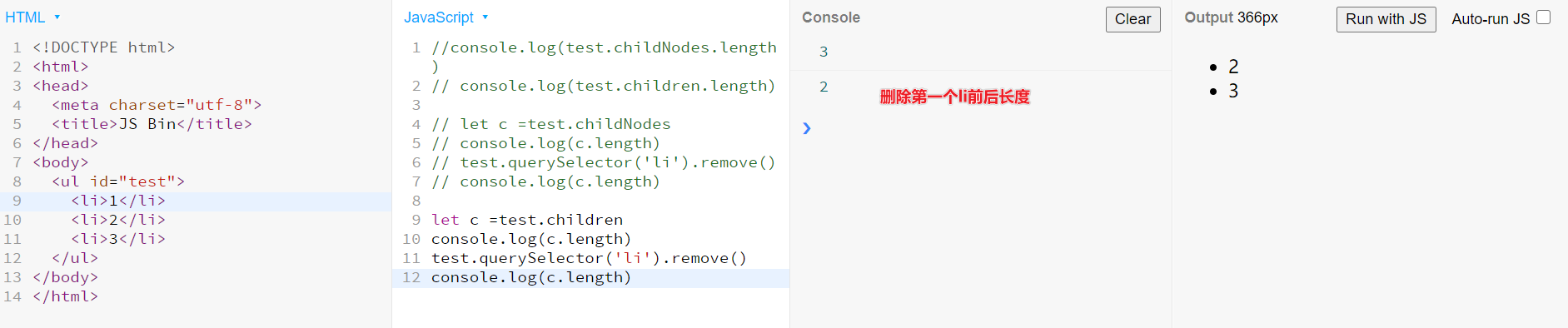
document.querySelectorAll('li').length只会认定第一次的长度3,后面怎么改都是第一次打印的3查兄弟姐妹
[x] 首先都需要先找到自己的爸爸,再其子元素里找兄弟姐妹
node.parentNode.children //还需要排除自己node.parentNode.childNodes //不仅要排除自己,还要排除其他的节点(空格等)

let siblings = []let c2 = div1.parentElement.children //先找到它的爸爸,再从爸爸的子代里找兄弟姐妹for(let i=0;i<c2.length;i++){if(c2[i] !== div1){siblings.push(c2[i])}}
查看老大和老幺
//node.children[0]node.firstChild //查看第一个node.lastChild //查看最后一个
这里 node 如果是 div1 了,那就是找 div1 的子元素了

这是在百度页面,我插入了一个div1到head里查看当前位置前后的(下面的方法是查找文本节点)
node.previousSibling //查看前一个兄弟node.nextSibling //查看后一个兄弟

[x] 如果不想要文本节点,在 Sibling 前面再加一个 Element 也行,表示元素兄弟
-
node.previousElementSibling -
node.next``Element``Sibling汇总:

遍历一个 div 里的所有元素
同数据结构里的tree — 链接travel = (node, fn) => {fn(node)if (node.children) {for (let i = 0; i < node.children.length; i++) {travel(node.children[i], fn) //递归}}}travel(div1, (node) => console.log(node)) //fn在这里定义是什么函数了
DOM也都是树结构

若有收获,就点个赞吧
0 人点赞
