取子集操作符
最常见的[,还有另外两个取子集操作符: [[和$。 除了只能返回单个值以外, [[与[是类似的,它还可以用于取出列表的一部分。 当通过字符进行取子集操作时, $是[[一种有用的简化写法。对列表进行操作时,需要[[。 这是因为当[应用于列表时,总是返回列表:它从来不会返回列表包含的内容。 为了获得列表的内容,需要使用[[
向量
原子向量
原子向量索引支持 [ 和[[, 共有6种索引方式
正整数索引
a <- c(2,4,6,8)> a[1][1] 2> a[c(1,4)][1] 2 8> a[c(1:4)][1] 2 4 6 8
负整数索引:取删除指定位置元素后的其他元素
a <- c(2,4,6,8)> a[-1][1] 4 6 8> a[c(-1, -2)][1] 6 8> a[c(-1:-4)]numeric(0)> a[c(-1:-2)][1] 6 8
逻辑向量索引
a <- c(2,4,6,8)a[c(T,T,T,F)][1] 2 4 6
空值与0: 前者返回本身,后者返回一个空原子向量
a <- c(2,4,6,8)> a[][1] 2 4 6 8> a[0]numeric(0)
字符向量,可以使用[[ 索引
a <- c(2,4,6,8)names(a) <- c("a", "b", "c", "d")> a["a"]a2> a[c("a", "b")]a b2 4> a[["a"]][1] 2
列表
索引的方式与原子向量一致,但是支持$操作符号,其中,使用[将总是返回一个列表;使用[[和$,则取出列表的一部分。
矩阵与数组
你可以通过三种方式对更高维的结构进行取子集操作:
- 使用多个向量
- 使用单个向量
- 使用矩阵
对矩阵(2 维)和数组(大于 2 维)进行取子集操作的最常见的方式,是对一维取子集操作的简单推广:你对每一个维度都提供一个一维索引,并以逗号分隔。 使用空白(blank)的方式来取子集时代表取出所有的行或者列
a <- matrix(1:9, nrow = 3)> a[1,][1] 1 4 7> a[1:2,][,1] [,2] [,3][1,] 1 4 7[2,] 2 5 8> a[-1:-2,][1] 3 6 9> a[,1:2][,1] [,2][1,] 1 4[2,] 2 5[3,] 3 6> a[c(1,3),c(1,3)][,1] [,2][1,] 1 7[2,] 3 9
将矩阵命名后,同样支持字符索引
colnames(a) <- c("a","b", "c")> a[,c("a", "c")]a c[1,] 1 7[2,] 2 8[3,] 3 9
数据框
数据框同时支持[, [[, $索引方式, 支持整数,bool索引
df <- data.frame(x = 1:3, y = 3:1, z = letters[1:3])> df$x[1] 1 2 3> df["x"]x1 12 23 3> df[["x"]][1] 1 2 3> df[,df$x == 2 ][1] 3 2 1> df[1, ]x y z1 1 3 a
指如果对矩阵取子集得到的结果是一维的,那么会默认会转化为向量,使用 drop = FALSE 参数可以避免这一点。
> df[,"x", drop = T][1] 1 2 3> df[,"x", drop = F]x1 12 23 3
S3对象
S3 对象是由原子向量、数组和列表组成的,所以你可以使用上面描述的技术对 S3对象进行取子集操作。 你可以通过 str()函数获得的它们的结构信息。
S4对象
对 S4 对象来说,有另外两种取子集操作符: @(相当于$)和 slot()(相当于[[)。 @比$更加严格,如果槽(slot)不存在,那么它会返回错误。
简化与保持
简化(simplifying)和保持(preserving) ,即取子集操作之后是否把结果转化为更简单的数据类型,比如取出数据框的一列,如果选择简化,则返回的是向量,如果选择保持,则返回的仍然是数据框, 在对矩阵和数据框进行取子集操作时忽略了 drop = FALSE,是编程中最常见的错误来源之一。 总之,保持(preserving)是对所有数据类型都是相同的:你得到的输出类型与输入类型是相同的。 简化(simplifying)是数据类型随着不同行为略有变化
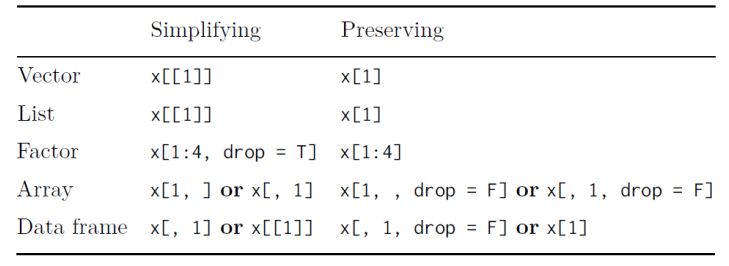
- 原子向量: 移除名字
- 列表: 返回列表内的对象,而不是包含单个元素的列表。
- 因子: 丢弃所有没有用到的水平。
- 矩阵和数组: 如果任一维度的长度为 1,则丢弃那个维度
- 数据框: 如果输出是单列的,那么将用向量替代数据框返回
$
$是一种简化的操作符, x$y 等价于 x[[“y”, exact = FALSE]] ,试图把它与存有列名的变量联合使用是不可取的
$可以部分匹配列名,如匹配mtcars数据框的am列val <- "cyl"> mtcars$valNULL
> mtcars$a[1] 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 0 0 0 0 0 1 1 1 1 1 1 1> mtcars$am[1] 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 0 0 0 0 0 1 1 1 1 1 1 1
应用
手动匹配与合并
手动实现left_join部分功能,
- grades:成绩表
- info: 不同成绩对应评分
- df:每个成绩对应的评分表 ```r grades <- c(100, 102, 102, 100, 101) info <- data.frame( grade = 100:102, desc = c(“Excellent”, “Good”, “Poor”), fail = c(F, F, T) ) info
id <- match(grades, info$grade) df <- info[id,] rownames(df) <- c(1:nrow(df)) df
—输出 ———————————————————————————————————
grade desc fail 1 100 Excellent FALSE 2 102 Poor TRUE 3 102 Poor TRUE 4 100 Excellent FALSE 5 101 Good FALSE
<a name="o1bya"></a>### 随机取样随机抽取行或列```rdf <- data.frame(x = rep(1:3, each = 2), y = 6:1, z = letters[1:6])df[sample(nrow(df),3),]# 有放回df[sample(nrow(df),3, rep = T),]
排序
order函数,order输出一个向量,默认返回输入向量各个元素从小到大排列的index值, decreasing = TRUE 把排序方式从升序变成降序。 默认情况下,缺失值都将排在向量的末尾;但是,你可以设置 na.last = NA 来删除缺失值,或者设置 na.last = FALSE 把缺失值排在向量的开头。
x <- c("b", "c", "a")order(x)> [1] 3 1 2x[order(x)]> [1] "a" "b" "c"
展开聚合的数据
展开聚合的数据(Expanding aggregated counts):有时你得到了一个数据框, 相同的行已经合并到了一起,一个用来计数的列也已经添加进去了。 rep()函数联合整数取子集操作,使得展开这种数据变得容易,它通过重复行的索引来进行
> df <- data.frame(x = c(2, 4, 1), y = c(9, 11, 6), n = c(3, 5, 1))# n为计数列> dfx y n1 2 9 32 4 11 53 1 6 1df2 <- df[rep(c(1:nrow(df)),df$n),]rownames(df2) <- c(1:nrow(df2))df2[,-ncol(df2)]x y1 2 92 2 93 2 94 4 115 4 116 4 117 4 118 4 119 1 6
删除列
df$col <- NULLdf[,"col"] <- NULLdf[["col"]] <- NULL

若有收获,就点个赞吧
0 人点赞
